Need help troubleshooting a Windows Azure SQL Database connection, or getting started with SQL Server Data Tools? Well, there's now a one-stop shop where you can identify aspects of your problem as it relates to the big picture of database development and immediately go to the appropriate resources to solve it.
Yes, data developers now have their own lifecycle management acronym and accompanying guidance.
That's thanks to Microsoft's Louis Berner and his Database Lifecycle Management topic page in the MSDN Library.
"DLM is not a product but a comprehensive approach to managing the database schema, data, and metadata for a database application," the page states. It includes a complicated diagram (see Figure 1) that developers can use to identify apps and actions specific to their scenarios, along with links for guidance in the categories SQL Server Data Tools, SQL Server Management Studio and Windows Azure SQL Database.
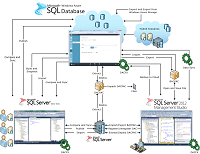
[Click on image for larger view.] |
| Figure 1. The DLM Diagram |
I asked Berner about his DLM topic page, which has been getting some buzz in data development circles since it went live around the end of January. He explained that he worked in SQL Server Education, collaborating with Microsoft Customer Support Services to spot trends in customer support calls and resolve problems.
Last summer, he identified several issues in his bailiwick: SQL Server and SQL Database (Azure) manageability. He listed them as:
- Customers were frustrated in their efforts to get started with the Windows Azure platform.
- Data portability was a specific area that stood out as problematic, especially as it relates to service-level agreements, for example, backup/restore, business continuity and disaster recovery.
- Connectivity and troubleshooting connection issues were topics of concern.
- Understanding basic concepts was lacking in terms of what Microsoft offers for database development, portability and monitoring across scenarios that include on-premise, hybrid and cloud architectures; I described it in general terms as "Database Lifecycle Management."
"Customer frustration was understandable because we had developed features and tools over the course of many releases and a time span of five years or more," Berner explained. "Many resources within feature teams didn't understand the holistic view because they worked on individual pieces of the puzzle, and many were recent arrivals to the product unit. Because of their focus on individual features, they weren't expected to understand the big picture."
One particularly important issue he wanted to emphasize was data-tier applications. "Developers can benefit from use of data-tier applications features to create a package for deployment to production, to create a snapshot of a schema for version control, or to publish a schema update in a controlled manner," he said. "This provides developers the ability to cleanly hand off to DBA or Ops resources. The data-tier application is an under-used and under-appreciated feature, in my opinion, maybe because customers don't know about it."
Well, if you didn't know about it, you do now--and you know where to go to learn more. Berner says he will continue to improve on the DLM page. "As I continue to monitor [Customer Support Services] data and other sources of customer experience, I have developed a backlog of additional topics to include in a topic refresh. I will also iterate on the artwork to improve it. Eventually, I would like customers to be able to drill down through the diagram to get to the content they want."
Berner has received good comments on his project and would like to get more feedback from data developers to help him in his improvement process. So check out the page and let him know what you think in the comments section or by sending him an e-mail with the subject: "DLM topic on MSDN."
We'd like to hear from you, too. Please comment here or drop me a line.
Posted by David Ramel on 04/17/20130 comments
Tables, graphs and 3D bar charts just don't cut it anymore. To really glean insights from all that data you're collecting, you need pretty pictures, maps and interactive "cinematic guided tours" that users can play with.
That's the vibe at the PASS Business Analytics Conference underway in Chicago, as witnessed by today's announcement of "project codename 'GeoFlow' Preview for Excel 2013."
"Now you can apply geographic and temporal data visually, analyze that data in 3D and create visual tours to share your insights with others," says this video about the new product that started out in Microsoft Research:
And there's plenty more where that came from. The conference session schedule lists 11 presentations on data visualization, another tool to further Microsoft's cause of self-service business intelligence (BI).
These things are a step up from the
Pivot tool that I played around with a while back, and even more recent cool toys such as the
"Data Explorer" preview and
Power View. GeoFlow lets you work with more than 1 million data rows in an Excel workbook and combine it with a 3D package on
Bing Maps, according to a Microsoft
announcement.
It's available now for download, provided you have: Microsoft Office Professional Plus 2013 or Office 365 ProPlus; and Windows 8 or Windows 7 or Windows Server 2008 R2.
Will you data devs be using the latest in 3D data visualization? Comment here or drop me a line.
Posted by David Ramel on 04/11/20130 comments
It was just an inconspicuous little reference seemingly buried in the verbiage announcing all the new goodies in the Visual Studio 2012 Update 2, looking almost like an afterthought jammed in at the last minute:
"It includes support in Blend for SketchFlow, WPF 4.5, and Silverlight 5."
But it was like getting a note from an old, long-lost friend. "Oh yeah, Silverlight is still around."
Some 16 months since Silverlight 5 has been available for download, you can now use it with the latest Blend hooked up to the latest Visual Studio, just like you used to. It made me want to dive right in and play around with those 3D-like animations built with the storyboard. I had used it for weeks (months?) to build a cool blackjack game with all the bells and whistles, including playing cards flipping through the air onto the card table. I loved it.
But, for a while now, having sensed the winds of change, I've been plugging away at getting up to speed on apps built with HTML5, JavaScript and CSS. I hate it.
I know that's just me the hobbyist, and it means nothing. Maybe Silverlight is irrelevant to serious LOB devs. And even if that's not the case, after all, Microsoft has said it's not killing off Silverlight tomorrow or anything drastic like that. And it has been available as a preview download since last August. But still, it was nice to catch up with that old friend and see that others still cared about him, too, fitting him into their plans. I wondered what the user reaction would be, so I checked. It looks like Silverlight still has a loyal following.
There it was, No. 2 on the "Hot ideas" page of the Visual Studio UserVoice site--where you can present and vote on ideas for VS--with the simple title of "Silverlight 6." The OP had written, "Please do work on Silverlight next version. I feel Silverlight is great tool ... but as you guys stopped working on it; I feel that I wasted my time in learning Silverlight." The Jan. 13 post had 874 votes and 54 comments, mostly along the same lines.
But I don't want to give the impression that this is a landslide movement or anything. The most popular idea was to bring color back to VS, and it had more than 12,000 votes, which astounds me, right up there with the ALL CAPS menu fiasco. And Silverlight wasn't even mentioned in the comments section of the S. Somasegar blog post announcing the new update.
So maybe Silverlight is like Douglas MacArthur, an old soldier who doesn't die, but just fades away. An old friend with whom I'll stay in touch but won't meet at the pub for a couple of beers anymore. And that's cool. I know, it's only Silverlight and Blend ... but I like it.
Do you like Silverlight? Please comment here or drop me a line.
Posted by David Ramel on 04/05/20130 comments
Ok, that report is due soon, so I'm going to fire up dBASE to run some reports, export the data into Lotus 1-2-3 and summarize everything with WordPerfect--while listening to Wham! and Foreigner, of course.
Oops, my mind was momentarily transported back into the mid '80s.
Amazingly, though, one of those pioneering software products was just updated as of yesterday. Yup, dust off those old .dbf files, dBASE PLUS 8 has been released.
And, while the original Ashton-Tate version was developed for the CP/M operating system (remember those dual 5-1/4 in. floppies--one for the program, one for the data?), this new one runs on Windows 8 (yes, even the 64-bit version). My, how times have changed.
WordPerfect, of course, is still around under the stewardship of Corel Corp., but I hadn't heard anything about dBASE for quite a while. The new dBASE guardian, dBase LLC, claims it's still in use by "millions of software developers." The company was formed last year with the help of some people who formerly worked at dataBased Intelligence Inc., "the legal heir" to dBASE.
I'm not sure exactly what happened to dBASE after the astounding success of dBASE III, but, according to Wikipedia, the decline started with "the disastrous introduction of dBase IV, whose stability was so poor many users were forced to try other solutions. This was coincident with an industry-wide switch to SQL in the client-server market, and the rapid introduction of Microsoft Windows in the business market."
Anyway, the new version includes ADO support, a new UI and "enhanced developer features with support for callbacks and the ability to perform high precision math."
Pricing is $399 for the regular edition, $299 for an upgrade and $199 for a personal edition without ADO support. I wonder what those prices equate to in 1985 dollars?
UPDATE: Here's a pretty good history of dBASE by Jean-Pierre Martel, editor of The dBASE Developers Bulletin.
Any old-timers out there with a good memory? What did dBASE III sell for? And why did some of these pioneering products die or fade into obscurity, while others continue to thrive? Comment here or drop me a line.
Posted by David Ramel on 03/20/20130 comments
"Does SSDT for Visual Studio 2012 support BI project templates?" asked James V. Serra in a TechNet forum last September.
Some six months later, the answer was yes: "Hi James, the download to add the BI Project Templates to the VS2012 shell is now available."
Microsoft last week
announced the online release of "SQL Server Data Tools – Business Intelligence for Visual Studio 2012" (SSDT BI), available for download
here.
The release includes templates for Visual Studio 2012 BI projects, including Analysis Services, Integration Services and Reporting Services. These templates were part of the old Business Intelligence Development Studio (BIDS).
SQL Server Data Tools (SSDT) encompasses a bunch of integrated services and enhancements to improve database development entirely from within the Visual Studio IDE, such as incorporating functionality found in BIDS and SQL Server Management Studio (SSMS), among a host of other features.
Prior to this, the BI templates were available only in Visual Studio 2010, SSDT 2010 or SQL Server 2012. The new release will be installed through the SQL Server 2012 setup tool as a shared service and will install a Visual Studio 2012 integrated shell if you don't already have VS 2012.
This will hopefully relieve a lot of the frustration of data developers confused by different versions of SSDT, which was introduced with SQL Server 2012 but hosted in the VS 2010 shell, and inconsistencies in functionality as data development tools have evolved.
Apparently, though, there are still some frustrated users and more integration to be done. SQL DBA John Pertell welcomed the announcement. "That’s great news as a lot of developers, myself included, have been waiting for this functionality," he said. However, he added, "the bad news is that it doesn’t include the Database Projects templates released last year. You’ll still need to install them separately. But they will work together."
He explained further:
So if you want just the BI templates for Visual Studio 2012 you only have to install the BI version of SSDT. If you also want the database projects you will need to install both the BI templates and the database templates. And if you want to use the test plans for your new database projects and create SSRS reports or SSIS packages you’ll need a full edition of VS 2012, either Premium or Ultimate, plus the database templates plus the BI templates.
There were also some users frustrated by the install experience, especially on 64-bit machines running SQL Server 2012 (see comments on this blog post). Visual Studio and the SSDT integrated shell are 32-bit apps, and users reported errors, some of which were apparently caused by the installation tool trying to install the 32-bit version of SQL Server 2012, Service Pack 1. The solution seems to be to choose the "perform new install" option during installation and not the "add features to existing" option.
Still, many data devs are happy with the new capabilities. Those include Serra, who said on his blog, "It took 8 months, but at least it was quicker than being able to use BI in VS 2010, which took about two years."
Other enhancements to Visual Studio 2012 added last week include Office Developer Tools and a SQL Server Data-Tier Application Framework update.
What do you think of the new BI functionality in SSDT? Are we headed toward one big, comprehensive IDE that will include everything you need for SQL Server development in one place? Comment here or by e-mail.
Posted by David Ramel on 03/14/20130 comments
Remember when SQL developers felt threatened by Big Data? Relational database management systems were old-school relics that couldn't cope with the vast amounts of unstructured, disparate data. NoSQL was the future. You needed to get onboard with Hadoop and MapReduce, running on Linux.
Well, not anymore.
Maybe not ever, really. There is just too big of an installed base of SQL developers and systems for the two camps, Big Data and SQL, to have remained apart. Even four or five years ago the convergence was underway with Hive, a data warehouse system for Hadoop that uses "a SQL-like language called HiveQL."
That convergence seems to be rapidly accelerating. Microsoft has been helping out, of course, with PolyBase in its SQL Server 2012 Parallel Data Warehouse to enable SQL queries of Big Data and initiatives such as HDInsight and the Hortonworks Data Platform to get Big Data into the Windows ecosystem.
But Redmond has plenty of company. Just this week I had the opportunity to interview Web coding pioneer Lloyd Tabb about the subject when his new company, Looker Data Sciences Inc., announced a query-based business intelligence (BI) platform called Looker. "SQL and relational querying is the best way to ask questions of large related data sets," Tabb told me.
He should know what he's talking about. He was a database and languages architect at Borland in the earlier days of RDBMS and went on to build LiveWire, the first application server for the World Wide Web. He was later a principal engineer at Netscape where he was architect of Netscape Navigator Gold (later named Composer), the first WYSIWYG HTML editor, and the engineering lead for Netscape Communicator. He helped found Mozilla.org and later became a pioneer in crowdsourcing, just to name a few of his accomplishments.
Looker, according to the company, "uses a new modeling language, LookML, which enhances SQL for analytics so end-users can perform powerful analytics without needing to know how a query is written."
I asked Tabb about the use of SQL instead of NoSQL, Hadoop or other Big Data technologies associated with BI analytics, and he gave me a little history lesson.
"Back in the day conventional wisdom was that if you were going to create an application for a PC you had to write it in Assembly language," Tabb said. "Higher-level languages generated code that was too big and too slow. Later, conventional wisdom was that you couldn't build a 'real-applicaiton' in an agile language--it was too big and too slow.
"Hadoop was designed because at the time there were no SQL engines that could deal with data sets that large. Developers regressed to hand coding queries in MapReduce. Both SQL and C are still in use today because they are the best abstractions for the kinds of problems they solve."
Looking around, I see lots of other evidence pointing to the Borg-like assimilation of Big Data by SQL. A few weeks ago GigaOM explored the subject with an article titled "SQL is what's next for Hadoop: Here's who's doing it," and just yesterday a PluralSight course on the topic was announced, described as "An investigation into the convergence of relational SQL database technologies from several vendors and Big Data technologies like Apache Hadoop."
And there are plenty more similar things going on out there. So rest easy, SQL data developers, your future is still bright.
What do you think about the convergence of Big Data and SQL? Share your thoughts by commenting here or by e-mail.
Posted by David Ramel on 03/08/20130 comments
I tuned in to a Webcast earlier this week where Red Hat announced it was contributing its Hadoop plug-in to the open source Apache Hadoop community and totally embracing Big Data with an "open hybrid cloud" strategy. More on that later.
What I found really interesting was the response to an audience member who asked, "How do you define Big Data?"
Hmmm. Good question. It's one of the most over-hyped terms in the tech world today, but exactly what is it? Red Hat executive Ranga Rangachari provided the following:
So ... what we think of ... analysts have different ways to talk about this. You've heard some analysts talk about the four Vs, which is the volume, the velocity and a few other attributes to it. And, yes, that is one way to look at it, but I think our view of Big Data is, fundamentally I think, the underlying type of data, either semi-structured or unstructured. That's one way, at least, from a technology standpoint, which contrasts very much from your typical structured databases that people are used to over the last 20 years or so.
Huh?
Obviously, it's not that easy to define Big Data.
John K. Waters addressed the question a year ago:
While there's lots of talk about big data these days (a lot of talk), there currently is no good, authoritative definition of big data, according to Microsoft Regional Director and Visual Studio Magazine columnist Andrew Brust.
"It's still working itself out," Brust says. "Like any product in a good hype cycle, the malleability of the term is being used by people to suit their agendas. And that's okay; there's a definition evolving."
Wikipedia defines it as "collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications."
In other words, no one knows.
Anyway, Red Hat will open source it's Hadoop plug-in and jump on the Big Data bandwagon with it's vision of an open hybrid cloud application platform and infrastructure. Rangachari said it was designed to give companies the ability to create Big Data workloads on a public cloud and move them back and forth between their own private clouds, "without having to reprogram those applications." Red Hat said in a news release that many companies use public clouds such as Amazon Web Services for developing software, proving concepts and pre-production phases of projects that use Big Data. "Workloads are then moved to their private clouds to scale up the analytics with the larger data set," the company said.
The Red Hat Hadoop plug-in is part of Red Hat Storage, running on Linux, which is based on the GlusterFS distributed file system. It's provided as an alternative to the Hadoop Distributed File System, known for some technical limitations that Apache and other organizations have also addressed.
Rangachari said the path to the open hyrbrid cloud Big Data application platform will eventually incorporate an Apache Hive connector (now in preview), NoSQL/MongoDB Java interoperability and RESTful OData Web protocol access, in addition to its existing JBoss middleware.
He emphasized that the new cloud strategy will be woven throughout every Red Hat project, noting that "Big Data could be one of the killer apps for the open hybrid cloud."
When asked why Red Hat was contributing its Hadoop plug-in to Apache, Rangachari said the Apache Hadoop community was the "center of gravity" in the Hadoop world and that the move will provide developers with easier access to the plug-in from the same ecosystem. He also said the company expects that, rather than stopping innovation of the technology, the move to open source will actually contribute to more innovation.
So what exactly is Big Data. Please explain here in a comment or via e-mail. We'll all appreciate it.
Posted by David Ramel on 02/22/20130 comments
Data developers were interested to learn this week that it was a futuristic data storage product called WinFS that Bill Gates identified as the Microsoft product he most regretted not making it to market.
In a live question-and-answer event on Reddit.com called Ask Me Anything, the legendary Microsoft co-founder answered dozens of questions from readers. While he was most concerned with the charitable work of the Bill & Melinda Gates Foundation, many questions inevitably focused on his Microsoft and programming days.
Here's the exchange about the database product:
Q: What one Microsoft program or product that was never fully developed or released do you wish had made it to market?
A: We had a rich database as the client/cloud store that was part of a Windows release that was before its time. This is an idea that will remerge since your cloud store will be rich with schema rather than just a bunch of files and the client will be a partial replica of it with rich schema understanding.
When another reader guessed that it might be WinFS, Gates answered in the affirmative. Another reader wondered if the OS mentioned was Vista, and Gates replied that: "Vista was what eventually shipped but Winfs had been dropped by then."
According to Wikipedia, WinFS is short for Windows Future Storage, described as:
the code name for a cancelled data storage and management system project based on relational databases, developed by Microsoft and first demonstrated in 2003 as an advanced storage subsystem for the Microsoft Windows operating system, designed for persistence and management of structured, semi-structured as well as unstructured data.
I found it interesting to learn that even way back then, Microsoft was thinking ahead to the cloud, and then, as now, it's all about the data.
What did you think about Gates' AMA session? Please comment here or send me an e-mail.
Posted by David Ramel on 02/15/20131 comments
"The icon of the shy geeky computer programmer is a mainstay of the technology landscape. But is it true?"
That's how a recent e-mail to me from Evans Data Corp. started out. At a previous company, as part of a class, I took a Myers-Briggs test that indicated I was introverted. And that my personality type (ISTP, one of 16 possible categories) tended to like motorcycles. I didn't need a standardized test to tell me either of those things, but I found it interesting.
I found the e-mail interesting, too. It said: "We asked over 400 software developers to rate themselves on a scale measuring introverted vs. extroverted. Only 2 percent thought they were completely introverted. So where do you think the other 98 percent saw themselves?"
Right off the bat, I thought, most of them probably thought themselves either partly introverted or extroverted. Duh. (Is there even such a thing as being "completely introverted?") But I was curious, so I asked for more information. Turns out this introvert/extrovert question was just a tiny part of a report to help companies market to developers. And they even provided me with a nice, customized quote to buy the report.
I'll have to pass on that, thanks, but the question still intrigued me. I know that good programmers tend to be good at math, so I've got a big strike against me for ever getting good. But what about being introverted? Does that help?
I would bet that most programmers are introverted. And, unfortunately, introversion comes with some negative baggage. Extroverts run things. They're the managers and supervisors. They're the ones you want to hang out with.
But I learned in the Myers-Briggs class that being introverted doesn't necessarily mean bad things, like being a weird loner who doesn't want to interact with people. From my understanding of that class, it has more to do with how people tend to recharge their batteries. Extroverts like being at parties and social occasions and can do it all day and come away refreshed. Introverts can socialize, but it leaves them tired. To recharge, they like to be alone for a while. Maybe reading a book or writing code. And being introverted doesn't mean you won't be a successful manager or supervisor. The class instructor said that former president Jimmy Carter is an introvert.
Well, I can't spring for report right now (I won't tell you the cost), but I'll do the next best thing: conduct my own survey. Are you introverted or extroverted? How do you see programmers in general? Does one or the other help or hinder good programming? Comment here or drop me a line. And I won't charge you.
Posted by David Ramel on 02/07/20136 comments
The Entity Framework Power Tools Beta 3 was released this week, but some data developers eager to get their hands on new features were disappointed to learn it mostly includes bug fixes because the product's functionality is shifting to the EF Designer in Visual Studio 2012.
With EF Power Tools, data developers get additional Visual Studio design-time tools for Entity Framework development.
The most important bug fix in Beta 3 is non-compatibility with Visual Studio 2012 Update 1. Several other issues were also addressed, but some developers wanted more.
"I was so happy when I saw the title ... but no new features," one reader commented.
Microsoft's Rowan Miller explained: "The reason we aren't adding a bunch of new features is that we're incorporating 'Reverse Engineer Code First' into the EF Designer workflow (which already has table selection, etc.)." He pointed to the Entity Framework CodePlex page for more information on that initiative.
In response to another reader, Miller expounded on his explanation:
When I say included as part of the EF Designer I really just mean that all the EF tooling (EF Designer, Reverse Engineer Code First, and the other Power Tools functionality) will be included in a single installer (which in turn is included 'in-the-box' in new versions of Visual Studio). We are going to use the same wizard that Database First uses for selecting tables etc. though.
The Beta 3 does add some context menu options to the "Entity Framework" sub-menu in Visual Studio. For example, you can right-click on a C# project for "Reverse Engineer Code First" functionality, which lets you generate Code First mappings for a database. "This option is useful if you want to use Code First to target an existing database as it takes care of a lot of the initial coding," Microsoft said.
Another project right-click option lets you add reverse engineering templates to your project.
You can also right-click on a code file that includes a derived DbContext class to display the entire Code First model in the EF designer, display Code First model Entity Data Model (EDMX) XML and generate pre-compiled views, along with other options.
And, instead of generating pre-compiled views, you can right-click on a EDMX file to generate views for a model created using the EF Designer.
Microsoft said that even though it won't be releasing a Power Tools RTM, it will continue Beta releases until the related functionality is incorporated into a pre-release version of the EF Designer.
What's your experience been when using EF Power Tools and the EF Designer? Please share your thoughts here or drop me a line.
Posted by David Ramel on 02/01/20130 comments
Some especially significant implications for Web developers can be found in a new study by research firm Ovum that measured the sentiment about Big Data vendors in 2012 Twitter posts.
While the study indicated that Big Data retained its popularity last year, data developers will be more interested in conclusions drawn by Ovum concerning the future of Web development.
"The Big Data buzz word even managed to transcend from the enterprise IT world to become a hot topic for business publications and journals in 2012, with MongoDB claiming considerable mindshare among Web developers who traditionally relied on MySQL," Ovum said in a news release.
Ovum principal analyst Tony Baer expounded upon that idea in a blog post. "To some extent, the results were surprising: while Hadoop garners much of the spotlight as a Big Data platform, the vendor 10gen, which develops MongoDB, came in second in mentions to Apache, which hosts the Hadoop project."
Ovum reported that Apache garnered 9.4 percent of Twitter posts, while MongoDB followed at 6.2 percent. "Although MongoDB is not known for storing high volumes of data, it is associated with variety, given its schemaless architecture," Baer said. "The popularity of the 10gen brand is attributable to the fact that MongoDB has become for Web developers the document equivalent of MySQL; it is open source, built in a language (JavaScript) that is highly popular among Web developers, and relatively simple to develop."
However, Baer said, "Ovum believes that the popularity of 10gen is more indicative of the future of Web development rather than Big Data, per se. We view 10gen as becoming the non-transactional database successor to MySQL in the world of Web developers."
I also found it interesting that a study about Big Data used the Big Data technique of culling information from social media to provide insights and conclusions not available through traditional database systems. I also found it interesting that DataSift, the company that conducted the study for Ovum, showed up in the very results it produced, coming in at 10th place in the ranking of Big Data companies mentioned in Twitter posts. All kinds of fascinating stuff here.
What do you think? Is MongoDB encroaching upon MySQL's turf? Please share your thoughts here or drop me a line.
Posted by David Ramel on 01/24/20131 comments
Being a data development guy, I was interested in how data-related developers were faring when the recent Visual Studio Magazine Salary Survey came out, and the answer is pretty darn well, comparatively.
But, also being a Silverlight fan, I was most struck by one particular chart: "Salary by Microsoft Technology Expertise." More than 1,000 developers were asked: "What Is Your Primary Area of Technology Expertise (Have Product Knowledge and Work with on a Regular Basis)?" One line said it all:
Silverlight n/a
No one? Not one single developer was primarily using Silverlight?
It seems like only yesterday that Silverlight was the technology of choice for streaming Olympic Games, political conventions and Netflix movies.
There was a lot of angst among Silverlight developers when Microsoft emphasized new ways of developing apps for the Windows Store and Windows 8 ecosystems with the Windows Runtime, focusing on open technologies such as JavaScript, HTML5 and CSS. Silverlight developers were reassured that their skills would transfer to the new ecosystems and that they could continue to use XAML, C# and such to produce new-age apps with Silverlight's companion Expression Blend IDE. That may well be happening, but it looks like Silverlight itself is dying on the vine, judging from this salary survey. Too bad.
Anyway, back to the data devs. While the average salary for .NET developers was pegged at about $94,000, SQL Server developers reported an average salary of $97,840, taking second place in areas of expertise after SharePoint at $103,188.
SQL Server developers also ranked highly when it came to the best technologies for job security/retention, being chosen by about 65 percent of respondents, following Visual Studio/.NET Framework at 82 percent.
So, as I reported last year, data-related developers are doing all right. Congratulations, and keep up the good work!
Do you miss Silverlight? Do you feel good about your job prospects as a data developer? Please share your thoughts by commenting here or dropping me a line.
Posted by David Ramel on 01/18/20135 comments