In-Depth
Demystifying the C# Yield-Return Mechanism
You can write cleaner, more efficient code with Yield-Return; the key is knowing the right situations for using the statement.
I remember when the C# language yield-return statement was released as part of C# 2.0 along with Visual Studio 2005. Early documentation for the yield-return mechanism made the statement sound exotic and mysterious.
Recent discussions with some of my developer colleagues suggested that several years later now the yield-return statement isn't used very often. We suspect this lack of use is not so much because developers don't know how to use the yield-return mechanism, but rather mostly because developers aren't quite sure exactly when to use yield-return. In this article I'll describe three common programming scenarios where you might want to consider using yield-return:
- Generating a sequence of strings where each string in the sequence depends on the value of the previous string
- Processing a text file sequentially where different kinds of lines are treated differently
- Sequentially filtering or modifying a large List collection of objects
The best way to see where I'm headed is to take a look at the screenshot in Figure 1, The first scenario uses yield-return to generate a sequence of 10 strings, where each new string is the previous string with two characters exchanged. The second scenario uses yield-return to walk through a text file, leaving lines that begin with d@ alone, but combining lines that have a@ followed by two numbers and lines that have b@ followed by one number, into lines that have d@ followed by three numbers. The third scenario uses yield-return to filter a List collection of Person objects to select those objects where the name field starts with "A," and the age field is less than 20. I assume you have intermediate level C# coding skills, but not that you know anything about the yield-return mechanism.
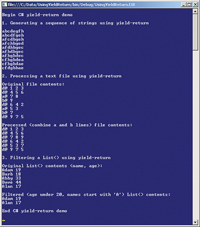
[Click on image for larger view.] |
| Figure 1. Three common C# yield-return scenarios. |
Generating a Sequence of Items
If you examine the first part of the output in Figure 1 and didn't know this was an article about the yield-return mechanism, you'd probably have realized that generating 10 strings where the value of each new string is derived from the value of the previous string isn't a difficult problem, and can be solved without using yield-return. One way to produce the output shown in the first scenario without using yield-return is to code a method named ComputeNextString, like so:
static string ComputeNextString(string currString)
{
char[] charArray = currString.ToCharArray();
int x = r.Next(0, charArray.Length);
int y = r.Next(0, charArray.Length);
char tmp = charArray[x];
charArray[x] = charArray[y];
charArray[y] = tmp;
return new String(charArray);
}
The method converts the input parameter string to a character array, exchanges two randomly selected characters, and returns a string with the characters exchanged. This method assumes the existence of a class-scope Random object named r. (If the Random object had been declared inside the method, each call would have reset the object and so every return string would have the same value). The ComputeNextString method could be called in a console application like so:
string str = "abcdefgh";
for (int i = 0; i < 10; ++i) {
str = ComputeNextString(str);
Console.WriteLine(str);
}
There's nothing surprising here; in fact, this is a very reasonable approach to take. Note that method ComputeNextString is explicitly called a total of 10 times. An alternative approach to computing each string as needed would be to generate a collection of strings, storing the strings in an array or list, and then returning one at a time as called. However, this approach could use lots of memory if you needed lots of strings.
Now let's see how to generate the same output in an entirely different way using yield-return. Listing 1, gives the method definition.
And here's how the method was called to produce the first part of Figure 1:
Console.WriteLine("1. Generating a sequence of strings using yield-return");
foreach (string s in ComputeNextString(10))
Console.WriteLine(s);
The yield-return version of method ComputeNextString accepts the maximum number of strings to generate as input parameter n, and returns type IEnumerable<string>. In somewhat overly simplistic terms, you can loosely interpret return type IEnumerable<string> to mean a collection of strings that can be consumed one at a time by a foreach statement.
The key line of code in ComputeNextString is the yield return statement inside the for loop. You can interpret "yield return someValue" to mean "wait for a calling foreach statement to request the next item and respond to that request by emitting someValue." The C# 2.0 design team decided to use two keywords, yield and return, together rather than create a new keyword such as "emit" or "ready." The "return" part of yield-return is potentially misleading to those not familiar with the yield-return statement, because return by itself unconditionally transfers control out of a method.
Notice that I can declare and instantiate a Random object inside the definition of method ComputeNextString, rather than externally as a class-scope object because the yield-return version of ComputeNextString is only called once. Behind the scenes, the C# compiler generates all the plumbing code to maintain state and coordinate the responses to the foreach calls.
In this example I use yield-return to generate a sequence of strings where the value of each new string depends on the value of the previous string. The technique isn't limited to strings; you can use the same technique to generate a sequence of numeric values or a sequence of objects that have multiple fields. But, based on my experience, generating a sequence of dependent strings is a more common task than generating sequences of dependent numeric values or dependent objects.
So if you need to generate a sequence of strings, values or objects where the next result depends in some way on previous results, which approach -- using a traditional coding pattern or using yield-return -- is better? It's essentially a matter of personal preference. There are no compelling technical advantages to one or the other of the two approaches.
Processing Text Files
Now let's look at the second scenario, where a text file is processed sequentially but different lines are treated differently. I created a dummy data file named DataFile.txt:
d@ 1 2 3
d@ 4 5 6
a@ 7 8
b@ 9
d@ 6 4 2a@ 5 3b@ 7d@ 9 7 5
Here I'm imagining that a complete data line begins with "d@" and is followed by three integers, and that there are separated data lines where the first two integers are on a line preceeed by "a@," followed immediately by the third integer on a line preceeded by "b@." I defined a method named FetchNextLine, shown in Listing 2,
The method returns an enumerator of strings, which allows the strings to be consumed one at a time by a calling foreach loop. After opening the file for reading, I walk through the file one line at a time. If I hit a complete line starting with d@, I place it on deck to be called using a yield-return statement. Otherwise, if I hit a line that begins with a@, I create a result line by advancing to the next line, which starts with b@, and concatentating the contents of the two lines, and then place that result on deck where it's ready to be called next by a foreach statement.
Here's the code to call the FetchNextLine method:
Console.WriteLine("2. Processing a text file using yield-return\n");
Console.WriteLine("Original file contents: ");
DisplayFile("..\\..\\DataFile.txt");
Console.WriteLine("Processed (combine a and b lines) file contents:");
foreach (string s in FetchNextLine("..\\..\\DataFile.txt"))
Console.WriteLine(s);
By placing method FetchNextLine in a foreach statement, I produce a very clean and elegant calling mechanism. I could have written code to process the data file and produce the same results using traditional coding patterns; that is, without using the yield-return machanism. But using a traditional appoach the calling code would be much messier. So, when processing a text file sequentially where some lines must be treated differently than other lines, even though there is no significant technical advantage to using the yield-return mechanism I generally prefer the yield-return approach because it usually gives me a cleaner calling interface.
Filtering a List Collection
If you've followed me up to this point you might have gotten the impression that there are no scenarios where using the yield-return mechanism provides a clear technical advantage over traditional coding patterns. In this section I'll explain the third part of the output in Figure 1 where I filter a List collection of objects and explain how there is in fact a clear technical advatage for the yield-return mechanism in this scenario.
First, I define a dummy Person class as shown in Listing 3.
My dummy Person class has two fields -- name and age -- and normal methods including a constructor, get properties and an overridden ToString mehod. In addition, I code two static filering methods that use the yield-return mechanism. The first filter returns an enumerator that can be used by a foreach statement to consume Person objects where the age field is less than 20. The second filter returns Person objects where the name field starts with "A." Although I coded the static filter methods inside the class definition, I could just as easily have defined them as standalone methods outside the Person class.
To generate the output shown in the third part of Listing 3, first I created five Person objects and stored them into a List<> collection:
Console.WriteLine("3. Filtering a List<> using yield-return\n");
List<Person> pList = new List<Person>();
pList.Add(new Person("Adam", 19));
pList.Add(new Person("Barb", 18));
pList.Add(new Person("Abby", 33));
pList.Add(new Person("Dave", 44));
pList.Add(new Person("Alan", 17));
Console.WriteLine("Original List<> contents (name, age): ");
for (int i = 0; i < pList.Count; ++i)
Console.WriteLine(pList[i].ToString());
At this point I could call the name filter:
foreach (Person p in Person.GetStartWithA(pList))
Console.WriteLine(p.ToString());
The output would be:
Adam 19
Abby 33
Alan 17
Or I could call the age filter like this:
foreach (Person p in Person.GetYoung(pList))
Console.WriteLine(p.ToString());
The output would be:
Adam 19
Barb 18
Alan 17
The calling pattern should be familiar by now: a foreach statement is used to consume one Person object at a time. Now suppose I want to apply both filters in order to select Person objects where the name starts with "A," and also the age is less than 20. I could use the crude but effective approach in Listing 4,
I first apply the name filter and store the results of that filter into a List collection named list1. Then I iterate through list1 using the age filter. This approach works, but if the original collection of Person objects is very, very large you could be using large amounts of memory for the intermediate list.
Here's an alternative approach to produce the output shown in the third scenario in Figure 1:
Console.WriteLine("Filtered List<> contents:");
foreach (Person p in Person.GetYoung(Person.GetStartWithA(pList)))
Console.WriteLine(p.ToString());
Here I chain the filters together and am able to avoid using a potentially large intermediate collection. Very neat! The foreach statement first calls the inner name filter which selects a Person where name starts with "A." That result is chained to the outer age filter, which selects the Person object if the age is less than 20.
Processing collections of objects is a scenario where using the yield-return mechanism can sometimes provide a technical advantage over using a traditional coding pattern. If you find yourself writing a method that accepts a collection (typically a List<>) of objects as an input parameter and returns a large collection so that the return collection can be used by another method or code, consider refactoring your code to use the yield-return mechanism in order to avoid large intermediate collections.
When C# Yield-Return Makes Sense
There are three relatively common programming scenarios to consider using the C# yield-return mechanism (and all three scenarios can be coded without using yield-return.) The first is generating a sequence of strings, numeric values or objects (usually strings in practice) where the next item in the sequence depends on one or more of the previous items. There's usually no significant technical advantage when using yield-return, but yield-return may create a cleaner calling interface.
The second scenario is sequentially processing a text file where different kinds of lines are handled differently. Again, there's typically no significant technical advantage when using yield-return, but the calling interface is usually cleaner.
The third scenario is filtering a large collection (typically a List<>) of objects. In this scenario there's often a technical advantage to using yield-return, because you can often avoid creating large intermediate collections. Additionally, the calling interface allows to easily chain together multiple filters, creating very clean code.
The three programming scenarios I've decribed here are by no means the only ones where using the C# yield-return mechanism can be used, but they're among the most common. If you keep alert for these scenarios in your coding environment and use yield-return, you're likely to discover other interesting scenarios where using yield-return can be useful.
About the Author
Dr. James McCaffrey works for Microsoft Research in Redmond, Wash. He has worked on several Microsoft products including Azure and Bing. James can be reached at [email protected].