Neural Network Lab
The Neural Network Input-Process-Output Mechanism
Understanding the feed-forward mechanism is required in order to create a neural network that solves difficult practical problems such as predicting the result of a football game or the movement of a stock price.
An artificial neural network models biological synapses and neurons and can be used to make predictions for complex data sets. Neural networks and their associated algorithms are among the most interesting of all machine-learning techniques. In this article I'll explain the feed-forward mechanism, which is the most fundamental aspect of neural networks. To get a feel for where I'm headed, take a look at the demo program in Figure 1 and also a diagram of the demo neural network's architecture in Figure 2.
 [Click on image for larger view.]
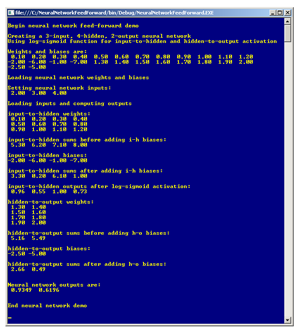
Figure 1. Neural network feed-forward demo.
[Click on image for larger view.]
Figure 1. Neural network feed-forward demo.
If you examine both figures you'll see that, in essence, a neural network accepts some numeric inputs (2.0, 3.0 and 4.0 in this example), does some processing and produces some numeric outputs (0.93 and 0.62 here). This input-process-output mechanism is called neural network feed-forward. Understanding the feed-forward mechanism is required in order to create a neural network that solves difficult practical problems such as predicting the result of a football game or the movement of a stock price.
 [Click on image for larger view.]
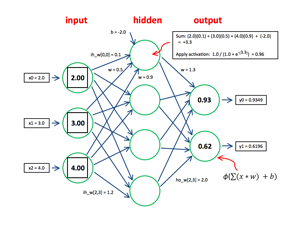
Figure 2. Neural network architecture.
[Click on image for larger view.]
Figure 2. Neural network architecture.
If you're new to neural networks, your initial impression is likely something along the lines of, "This looks fairly complicated." And you'd be correct. However, I think the demo program and its explanation presented in this article will give you a solid foundation for understanding neural networks. This article assumes you have expert-level programming skills with a C-family language. I coded the demo program using C#, but you shouldn't have too much trouble refactoring my code to another language such as Visual Basic or Python.
Architecture
The demo can be characterized as a fully connected three-input, four-hidden, two-output neural network. Unfortunately, neural network terminology varies quite a bit. The neural network shown in Figure 2 is most often called a two-layer network (rather than a three-layer network, as you might have guessed) because the input layer doesn't really do any processing. I suggest this by showing the input nodes using a different shape (square inside circle) than the hidden and output nodes (circle only).
Each node-to-node arrow in Figure 2 represents a numeric constant called a weight. For example, assuming nodes are zero-indexed starting from the top of the diagram, the weight from input node 2 to hidden node 3 has value 1.2. Each hidden and output node, but not any input node, has an additional arrow that represents a numeric constant called a bias. For example, the bias for hidden node 0 has value -2.0. Because of space limitations, Figure 2 shows only one of the six bias arrows.
For a fully connected neural network, with numInputs input nodes, numHidden hidden nodes and numOutput output nodes, there will be (numInput * numHidden) + (numHidden * numOutput) weight values. And there will be (numHidden + numOutput) bias values. As you'll see shortly, biases are really just a special type of weights, so for brevity, weights and biases are usually collectively referred to as simply weights. For the three-input, four-hidden, two-output demo neural network, there are a total of (3 * 4) + (4 * 2) + (4 + 2) = 20 + 6 = 26 weights.
The demo neural network is deterministic in the sense that for a given set of input values and a given set of weights and bias values, the output values will always be the same. So, a neural network is really just a form of a function.
Computing the Hidden-Layer Nodes
Computing neural network output occurs in three phases. The first phase is to deal with the raw input values. The second phase is to compute the values for the hidden-layer nodes. The third phase is to compute the values for the output-layer nodes.
In this example, the demo does no processing of input, and simply copies raw input into the neural network input-layer nodes. In some situations a neural network will normalize or encode raw data in some way.
Each hidden-layer node is computed independently. Notice that each hidden node has three weight arrows pointing into it, one from each input node. Additionally, there's a single bias arrow into each hidden node. Understanding hidden node computation is best explained using a concrete example. In Figure 2, hidden node 0 is at the top of the diagram. The first step is to sum each input times each input's associated weight: (2.0)(0.1) + (3.0)(0.5) + (4.0)(0.9) = 5.3. Next the bias value is added: 5.3 + (-2.0) = 3.3. The third step is to feed the result of step two to an activation function. I'll describe this in more detail shortly, but for now: 1.0 / (1.0 + Exp(-3.3)) = 0.96. The values for hidden nodes 1, 2 and 3 are computed similarly and are 0.55, 1.00 and 0.73, as shown in Figure 1. These values now serve as inputs for the output layer.
Computing the Output-Layer Nodes
The output-layer nodes are computed in the same way as the hidden-layer nodes, except that the values computed into the hidden-layer nodes are now used as inputs. Notice there are a lot of inputs and outputs in a neural network, and you should not underestimate the difficulty of keeping track of them.
The sum part of the computation for output-layer node 0 (the topmost output node in the diagram) is: (0.96)(1.3) + (0.55)(1.5) + (1.00)(1.7) + (0.73)(1.9) = 5.16. Adding the bias value: 5.16 + (-2.5) = 2.66. Applying the activation function: 1.0 / (1.0 + Exp(-2.66)) = 0.9349 or 0.93 rounded. The value for output-layer node 1 is computed similarly, and is 0.6196 or 0.62 rounded.
The output-layer node values are copied as is to the neural network outputs. In some cases, a neural network will perform some final processing such as normalization.
Neural network literature tends to be aimed more at researchers than software developers, so you'll see a lot of equations with Greek letters such as the one in the lower-right corner of Figure 2. Don't let these equations intimidate you. The Greek letter capital phi is just an abbreviation for the activation function (many other Greek letters, such as kappa and rho, are used here too). The capital sigma just means "add up some terms." The lowercase x and w represent inputs and weights. And the lowercase b is the bias. So the equation is just a concise way of saying: "Multiply each input times its weight, add them up, then add the bias, and then apply the activation function to that sum."
The Bias As a Special Weight
Something that often confuses newcomers to neural networks is that the vast majority of articles and online references treat the biases as weights. Take a close look at the topmost hidden node in Figure 2. The preliminary sum is the product of three input and three weights, and then the bias value is added: (2.0)(0.1) + (3.0)(0.5) + (4.0)(0.9) + (-2.0) = 3.30. But suppose there was a dummy input layer node with a value of 1.0 that was added to the neural network as input x3. If each hidden-node bias is associated with the dummy input value, you get the same result: (2.0)(0.1) + (3.0)(0.5) + (4.0)(0.9) + (1.0)(-2.0) = 3.30.
Treating biases as special weights that are associated with dummy inputs that have constant value 1.0 simplifies writing research-related articles, but with regard to actual implementation I find the practice confusing, error-prone and hack-ish. I always treat neural network biases as biases rather than as special weights with dummy inputs.
Activation Functions
The activation function used in the demo neural network is called a log-sigmoid function. There are many other possible activation functions that have names like hyperbolic tangent, Heaviside and Gaussian. It turns out that choosing activation functions is extremely important and surprisingly tricky when constructing practical neural networks. I'll discuss activation functions in detail in a future article.
The log-sigmoid function in the demo is implemented like so:
private static double LogSigmoid(double z)
{
if (z < -20.0) return 0.0;
else if (z > 20.0) return 1.0;
else return 1.0 / (1.0 + Math.Exp(-z));
}
The method accepts a type double input parameter z. The return value is type double with value between 0.0 and 1.0 inclusive. In the early days of neural networks, programs could easily generate arithmetic overflow when computing the value of the Exp function, which gets very small or very large, very quickly. For example, Exp(-20.0) is approximately 0.0000000020611536224386. Even though modern compilers are less susceptible to overflow problems, it's somewhat traditional to specify threshold values such as the -20.0 and +20.0 used here.
Overall Program Structure
The overall program structure and Main method of the demo program (with some minor edits and WriteLine statements removed) is presented in Listing 1. I used Visual Studio 2012 to create a C# console application named NeuralNetworkFeedForward. The program has no significant Microsoft .NET Framework dependencies, and any version of Visual Studio should work. I renamed file Program.cs to the more descriptive FeedForwardPrograms.cs and Visual Studio automatically renamed class Program, too. At the top of the template-generated code, I removed all references to namespaces except the System namespace.
Listing 1. Feed-Forward demo program structure.
using System;
namespace NeuralNetworkFeedForward
{
class FeedForwardProgram
{
static void Main(string[] args)
{
try
{
Console.WriteLine("\nBegin neural network feed-forward demo\n");
Console.WriteLine("Creating a 3-input, 4-hidden, 2-output NN");
Console.WriteLine("Using log-sigmoid function");
const int numInput = 3;
const int numHidden = 4;
const int numOutput = 2;
NeuralNetwork nn = new NeuralNetwork(numInput, numHidden, numOutput);
const int numWeights = (numInput * numHidden) +
(numHidden * numOutput) + numHidden + numOutput;
double[] weights = new double[numWeights] {
0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2,
-2.0, -6.0, -1.0, -7.0,
1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2.0,
-2.5, -5.0 };
Console.WriteLine("\nWeights and biases are:");
ShowVector(weights, 2);
Console.WriteLine("Loading neural network weights and biases");
nn.SetWeights(weights);
Console.WriteLine("\nSetting neural network inputs:");
double[] xValues = new double[] { 2.0, 3.0, 4.0 };
ShowVector(xValues, 2);
Console.WriteLine("Loading inputs and computing outputs\n");
double[] yValues = nn.ComputeOutputs(xValues);
Console.WriteLine("\nNeural network outputs are:");
ShowVector(yValues, 4);
Console.WriteLine("\nEnd neural network demo\n");
Console.ReadLine();
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
Console.ReadLine();
}
} // Main
public static void ShowVector(double[] vector, int decimals) { . . }
public static void ShowMatrix(double[][] matrix, int numRows) { . . }
} // Program
public class NeuralNetwork
{
private int numInput;
private int numHidden;
private int numOutput;
private double[] inputs;
private double[][] ihWeights; // input-to-hidden
private double[] ihBiases;
private double[][] hoWeights; // hidden-to-output
private double[] hoBiases;
private double[] outputs;
public NeuralNetwork(int numInput, int numHidden,
int numOutput) { . . }
private static double[][] MakeMatrix(int rows, int cols) { . . }
public void SetWeights(double[] weights) { . . }
public double[] ComputeOutputs(double[] xValues) { . . }
private static double LogSigmoid(double z) { . . }
} // Class
} // ns
The heart of the program is the definition of a NeuralNetwork class. That class has a constructor, which calls helper MakeMatrix; public methods SetWeights and ComputeOutputs; and private method LogSigmoid, which is used by ComputeOutputs.
The class containing the Main method has two utility methods, ShowVector and ShowMatrix. The neural network is instantiated using values for the number of input-, hidden- and output-layer nodes:
const int numInput = 3;
const int numHidden = 4;
const int numOutput = 2;
NeuralNetwork nn = new NeuralNetwork(numInput,
numHidden, numOutput);
Next, 26 arbitrary weights and bias values are assigned to an array:
const int numWeights = (numInput * numHidden) +
(numHidden * numOutput) +
numHidden + numOutput;
double[] weights = new double[numWeights] {
0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2,
-2.0, -6.0, -1.0, -7.0,
1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2.0,
-2.5, -5.0 };
The weights and bias values are stored so that the first 12 values are the input-to-hidden weights, the next four values are the input-to-hidden biases, the next eight values are the hidden-to-output weights, and the last two values are the hidden-to-output biases. Assuming an implicit ordering isn't a very robust strategy, you might want to create four separate arrays instead.
After the weights are created, they're copied into the neural network object, and then three arbitrary inputs are created:
nn.SetWeights(weights);
double[] xValues = new double[] { 2.0, 3.0, 4.0 };
Method ComputeOutputs copies the three input values into the neural network, then computes the outputs using the feed-forward mechanism, and returns the two output values as an array:
double[] yValues = nn.ComputeOutputs(xValues);
Console.WriteLine("\nNeural network outputs are:");
ShowVector(yValues, 4);
Console.WriteLine("\nEnd neural network demo\n");
The Neural Network Data Fields and Constructor
The NeuralNetwork class has three data fields that define the architecture:
private int numInput;
private int numHidden;
private int numOutput;
The class has four arrays and two matrices to hold the inputs, weights, biases and outputs:
private double[] inputs;
private double[][] ihWeights;
private double[] ihBiases;
private double[][] hoWeights;
private double[] hoBiases;
private double[] outputs;
In matrix ihWeights[i,j], index i is the 0-based index of the input-layer node and index j is the index of the hidden-layer node. For example, ihWeights[2,1] is the weight from input node 2 to hidden node 1. Similarly, matrix hoWeights[3,0] is the weight from hidden node 3 to output node 0. C# supports a true two-dimensional array type, and you may want to use it instead of implementing a matrix as an array of arrays.
The constructor first copies its input arguments into the associated member fields:
this.numInput = numInput;
this.numHidden = numHidden;
this.numOutput = numOutput;
Then the constructor allocates the inputs, outputs, weights and biases arrays, and matrices. I tend to leave out the .this qualifier for member fields:
inputs = new double[numInput];
ihWeights = MakeMatrix(numInput, numHidden);
ihBiases = new double[numHidden];
hoWeights = MakeMatrix(numHidden, numOutput);
hoBiases = new double[numOutput];
outputs = new double[numOutput];
Helper method MakeMatrix is just a convenience to keep the constructor code a bit cleaner and is defined as:
private static double[][] MakeMatrix(int rows, int cols)
{
double[][] result = new double[rows][];
for (int i = 0; i < rows; ++i)
result[i] = new double[cols];
return result;
}
Setting the Weights and Biases
Class NeuralNetwork method SetWeights transfers a set of weights and bias values stored in a linear array into the class matrices and arrays. The code for method SetWeights is presented in Listing 2.
Listing 2. The SetWeights method.
public void SetWeights(double[] weights)
{
int numWeights = (numInput * numHidden) +
(numHidden * numOutput) + numHidden + numOutput;
if (weights.Length != numWeights)
throw new Exception("Bad weights array");
int k = 0; // Points into weights param
for (int i = 0; i < numInput; ++i)
for (int j = 0; j < numHidden; ++j)
ihWeights[i][j] = weights[k++];
for (int i = 0; i < numHidden; ++i)
ihBiases[i] = weights[k++];
for (int i = 0; i < numHidden; ++i)
for (int j = 0; j < numOutput; ++j)
hoWeights[i][j] = weights[k++];
for (int i = 0; i < numOutput; ++i)
hoBiases[i] = weights[k++];
}
Neural networks that solve practical problems train the network by finding a set of weights and bias values that best correspond to training data, and will often implement a method GetWeights to allow the calling program to fetch the best weights and bias values.
Computing the Outputs
Method ComputeOutputs implements the feed-forward mechanism and is presented in Listing 3. Much of the code consists of display messages to show intermediate values of the computations. In most situations you'll likely want to comment out the display statements.
Listing 3. Method ComputeOutputs implements the feed-forward mechanism.
public double[] ComputeOutputs(double[] xValues)
{
if (xValues.Length != numInput)
throw new Exception("Bad inputs");
double[] ihSums = new double[this.numHidden]; // Scratch
double[] ihOutputs = new double[this.numHidden];
double[] hoSums = new double[this.numOutput];
for (int i = 0; i < xValues.Length; ++i) // xValues to inputs
this.inputs[i] = xValues[i];
Console.WriteLine("input-to-hidden weights:");
FeedForwardProgram.ShowMatrix(this.ihWeights, -1);
for (int j = 0; j < numHidden; ++j) // Input-to-hidden weighted sums
for (int i = 0; i < numInput; ++i)
ihSums[j] += this.inputs[i] * ihWeights[i][j];
Console.WriteLine("input-to-hidden sums before adding i-h biases:");
FeedForwardProgram.ShowVector(ihSums, 2);
Console.WriteLine("input-to-hidden biases:");
FeedForwardProgram.ShowVector(this.ihBiases, 2);
for (int i = 0; i < numHidden; ++i) // Add biases
ihSums[i] += ihBiases[i];
Console.WriteLine("input-to-hidden sums after adding i-h biases:");
FeedForwardProgram.ShowVector(ihSums, 2);
for (int i = 0; i < numHidden; ++i) // Input-to-hidden output
ihOutputs[i] = LogSigmoid(ihSums[i]);
Console.WriteLine("input-to-hidden outputs after log-sigmoid activation:");
FeedForwardProgram.ShowVector(ihOutputs, 2);
Console.WriteLine("hidden-to-output weights:");
FeedForwardProgram.ShowMatrix(hoWeights, -1);
for (int j = 0; j < numOutput; ++j) // Hidden-to-output weighted sums
for (int i = 0; i < numHidden; ++i)
hoSums[j] += ihOutputs[i] * hoWeights[i][j];
Console.WriteLine("hidden-to-output sums before adding h-o biases:");
FeedForwardProgram.ShowVector(hoSums, 2);
Console.WriteLine("hidden-to-output biases:");
FeedForwardProgram.ShowVector(this.hoBiases, 2);
for (int i = 0; i < numOutput; ++i) // Add biases
hoSums[i] += hoBiases[i];
Console.WriteLine("hidden-to-output sums after adding h-o biases:");
FeedForwardProgram.ShowVector(hoSums, 2);
for (int i = 0; i < numOutput; ++i) // Hidden-to-output result
this.outputs[i] = LogSigmoid(hoSums[i]);
double[] result = new double[numOutput]; // Copy to this.outputs
this.outputs.CopyTo(result, 0);
return result;
}
Method ComputOutputs uses three scratch arrays for computations:
double[] ihSums = new double[this.numHidden]; // Scratch
double[] ihOutputs = new double[this.numHidden];
double[] hoSums = new double[this.numOutput];
An alternative design is to place these scratch arrays as class data members instead of method local variables. In the demo program, method ComputeOutputs is only called once. But a neural network that solves a practical problem will likely call ComputeOutputs many thousands of times; so, depending on compiler optimization, there may be a significant penalty associated with thousands of array instantiations. However, if the scratch arrays are declared as class members, you'll have to remember to zero each one out in ComputeOutputs, which also has a performance cost.
Method ComputeOutputs uses the LogSigmoid activation method for both input-to-hidden and hidden-to-output computations. In some cases different activation functions are used for the two layers. You may want to consider passing the activation function in as an input parameter using a delegate.
Wrapping Up
For completeness, utility display methods ShowVector and ShowMatrix are presented in Listing 4.
Listing 4. Utility display methods.
public static void ShowVector(double[] vector, int decimals)
{
for (int i = 0; i < vector.Length; ++i)
{
if (i > 0 && i % 12 == 0) // max of 12 values per row
Console.WriteLine("");
if (vector[i] >= 0.0) Console.Write(" ");
Console.Write(vector[i].ToString("F" + decimals) + " "); // 2 decimals
}
Console.WriteLine("\n");
}
public static void ShowMatrix(double[][] matrix, int numRows)
{
int ct = 0;
if (numRows == -1) numRows = int.MaxValue; // if numRows == -1, show all rows
for (int i = 0; i < matrix.Length && ct < numRows; ++i)
{
for (int j = 0; j < matrix[0].Length; ++j)
{
if (matrix[i][j] >= 0.0) Console.Write(" ");
Console.Write(matrix[i][j].ToString("F2") + " ");
}
Console.WriteLine("");
++ct;
}
Console.WriteLine("");
}
In order to fully understand the neural network feed-forward mechanism, I recommend experimenting by modifying the input values and the values of the weights and biases. If you're a bit more ambitious, you might want to change the demo neural network's architecture by modifying the number of nodes in the input, hidden or output layers.
The demo neural network is fully connected. An advanced but little-explored technique is to create a partially connected neural network by virtually severing the weight arrows between some of a neural network's nodes. Notice that with the design presented in this article you can easily accomplish this by setting some weight values to 0.
Some complex neural networks, in addition to sending the output from one layer to the next, may send their output backward to one or more nodes in a previous layer. As far as I've been able to determine, neural networks with a feedback mechanism are almost completely unexplored.
It's possible to create neural networks with two hidden layers. The design presented here can be extended to support multi-hidden-layer neural networks. Again, this is a little-explored topic.