Modern C++
Compiler Basics, Part 3: Syntax Analysis
Kenny Kerr continues his series about compiler fundamentals by introducing the syntax analysis, grammars, and the act of parsing or interpreting source code.
Have you ever thought of writing your own compiler? I'm writing a series of articles on compiler basics. Check out Part 1, where I begin by demonstrating a simple yet efficient way of reading the original source code into memory using a memory-mapped file. In Part 2, I cover lexical analysis. That's the process of turning some source code into a stream of tokens.
In this third installment, I want to introduce the concept of syntax analysis. This is where the compiler begins to make sense of the tokens by enforcing a syntax or grammar that I might define. This is often called parsing, so this month I'm going to show you how to write a simple parser for some mathematical expressions.
I'm trying to keep this series on compiler basics practical, but a bit of theory is required at this point. I know various facts quite instinctively about mathematical expressions because we've all been taught them from an early age. For example, 1 + 2 × 3 is the same as 1 + (2 × 3), rather than (1 + 2) × 3. I need to ensure that the compiler can understand such expressions correctly, and not interpret them in a way that isn't consistent with accepted rules. Of course, the computer never went to school and knows nothing of these conventions. Before I start writing the code, it helps to define a simple grammar that I intend to implement. This grammar will describe the expressions in a way I can then follow up with a meaningful implementation. While I wrote the FileMap and Scanner classes from the first two parts of this series without any real planning, writing a parser without any forethought as to the grammar it ought to support will inevitably lead to a lot of time wasted in debugging.
A grammar needn't be anything fancy -- it's just a set of rules the parser will logically follow to match tokens to meaningful grammatical expressions. First, I'll begin by defining a number.
Number:
• Floating-point value
That's pretty simple. This maps most directly to the tokens my Scanner class produces, and specifically the value that may be retrieved when the Scanner's Read method returns the Token::Number constant. Next are the primary expressions.
Primary:
• Number
• ( Expression )
Here, you begin to see the grammar taking shape. A primary expression is either a number, as previously defined by the grammar, or some expression within parentheses. These parentheses map to the Token::LeftParenthesis and Token::RightParenthesis constants, while the expression itself still needs to be defined within my grammar.
So far I have two rules, sometimes called productions. A Number can only have the form of a floating-point value, while a Primary can be either a Number or an expression enclosed within parentheses. These are often called alternatives.
Finally, I need to deal with the mathematical operators. While parentheses let me override any natural order or precedence, I'd still like the parser – and, by definition, this grammar -- to embody this same operator precedence such that parentheses aren't required for obvious expressions. So, I'll distinguish between terms and expressions with terms representing those operations with a higher precedence.
Term:
• Primary
• Term × Primary
• Term ÷ Primary
Thus, a Term can be a Primary, or a Term multiplied by a Primary, or a Term divided by a Primary. Notice how a Term is defined in terms of itself. This allows 2 × 3 to be considered a term. You can substitute any valid alternative.
The mathematical operators that remain then become Expressions and represent the lowest precedence.
Expression:
• Term
• Expression + Term
• Expression – Term
By separating Terms and Expressions, the parser can decide to first evaluate Terms and then Expressions, regardless of the order in which they actually appear in the mathematical expression. Had I failed to define such a grammar, it would have been far less obvious that this distinction needs to be made within the parser's implementation. Here's the final grammar as a whole:
Expression:
• Term
• Expression + Term
• Expression – Term
Term:
• Primary
• Term × Primary
• Term ÷ Primary
Primary:
• Number
• ( Expression )
Number:
• Floating-point value
Now you can begin to see that because one alternative for a Primary is an Expression within parentheses, you can use the parentheses to override the natural operator precedence the parser would provide if the parentheses aren't present. Given that an Expression may be a Term, a Term may be a Primary, and a Primary may be a Number, I can begin by implementing the Expression rules because that's where the evaluation of the expression will naturally begin from a procedural standpoint.
As I did in the first two installments, I'll begin with some idealistic code, shown in Listing 1.
Listing 1: Idealistic Code
int main()
{
FileMap file(L"C:\\temp\\Sample.b");
if (!file)
{
printf("Error: failed to open file\n");
return 1;
}
Scanner scanner(file.Begin(), file.End());
float result = 0.0f;
if (ScanExpression(scanner, result))
{
printf("Result: %.2f\n", result);
}
else
{
printf("Error: failed to parse\n");
}
}
You can see the FileMap and Scanner classes. I've now added a ScanExpression function that I provide with a reference to the scanner, as well as a reference to a floating-point variable that should receive the result of the expression. If all goes well, the ScanExpression function returns true and the result is printed out. Here, again, are the rules, or alternatives, for Expressions:
Expression:
• Term
• Expression + Term
• Expression – Term
Thus, I can begin my ScanExpression implementation by scanning for a Term:
bool ScanExpression(Scanner & scanner, float & value)
{
if (!ScanTerm(scanner, value)) return false;
// ...
}
If that fails, I know the scanner produced invalid syntax, so I return false. Next, I need to deal with an indeterminate number of alternatives:
for (;;)
{
Token const token = scanner.Read();
// ...
}
While there are only two grammatical alternatives, there may be any number of them in the token stream. The first grammatical alternative deals with addition:
if (Token::Add == token)
{
float other = 0.0f;
if (!ScanTerm(scanner, other)) return false;
value += other;
}
Here, you can see two things happening. The first is that I'm parsing the addition, but the second is that I'm actually interpreting the results. I'm evaluating the result of the expression immediately, rather than generating some other representation for the source code. The other grammatical alternative deals with subtraction:
else if (Token::Subtract == token)
{
float other = 0.0f;
if (!ScanTerm(scanner, other)) return false;
value -= other;
}
Here, again, I'm immediately evaluating the expression as the tokens arrive, and at each stop along the way I've relied on a ScanTerm function that will presumably deal with parsing the operands. Before I can get to that, however, I need to deal with two edge cases. The first involves invalid tokens and that's straightforward:
else if (Token::Invalid == token)
{
return false;
}
I simply give up scanning the expression if an invalid token is encountered. The second is a little more involved. What happens if ScanExpression is parsing 1 + 2 + 3 × 4 in its endless loop? At some point, the scanner will read the multiplication symbol and return the Token::Multiply constant. The ScanExpression function has now consumed a token it can't deal with. There are a number of ways to deal with this. Here, I'll just suggest the simplest, which is to backtrack the scanner:
else
{
scanner.Backtrack();
return true;
}
The Scanner class from Part 2 of this series doesn't have a Backtrack method, but it's simple enough to implement. I need to return the scanner to the position it held prior to the most recent call to the Read method. That way I can return and allow any calling function to attempt to read and interpret the token. I'll simply add an m_prev member variable to the Scanner class to go along with its m_next variable:
char const * m_prev = nullptr;
I just need to ensure that the Scanner constructor initializes this new member properly. It, too, can start off pointing to the beginning of the sequence:
Scanner(char const * const begin,
char const * const end) throw() :
m_end(end),
m_next(begin),
m_prev(begin)
{}
I'll then update the m_prev member variable every time the Read method is called so that it points to the location immediately preceding any new token:
Token Read() throw()
{
SkipWhitespace();
m_prev = m_next;
// ...
}
While I could've placed it at the very beginning of the Read method, this minor tweak saves the Scanner from having to rescan over any whitespace. Finally, I can add the Backtrack method itself -- nice and simple:
void Backtrack() throw()
{
m_next = m_prev;
}
Now my ScanExpression function can greedily consume as much of the token stream as it possibly can, and backtrack at the last moment when it discovers a token with which it can't deal. Keep in mind that while backtracking is a very efficient operation, it does mean that any previously scanned token has to be scanned again. There's always room for improvement. Here are the rules for Terms again:
Term:
• Primary
• Term × Primary
• Term ÷ Primary
The ScanTerm function that ScanExpression defers to follows much the same pattern:
bool ScanTerm(Scanner & scanner, float & value)
{
if (!ScanPrimary(scanner, value)) return false;
for (;;)
{
Token const token = scanner.Read();
// ...
}
}
ScanTerm, in turn, defers to a ScanPrimary function to deal with its operands, but is itself responsible for multiplication:
if (Token::Multiply == token)
{
float other = 0.0f;
if (!ScanPrimary(scanner, other)) return false;
value *= other;
}
It also deals with division:
else if (Token::Divide == token)
{
float other = 0.0f;
if (!ScanPrimary(scanner, other)) return false;
if (!other) return false;
value /= other;
}
Here, I'm naturally careful to avoid division by zero. But the ScanTerm function need not deal with invalid tokens, because it can simply backtrack and allow the caller to deal with it:
else
{
scanner.Backtrack();
return true;
}
This deals with both scenarios nicely. If an invalid token is encountered, ScanExpression can deal with it. If some other token is encountered, ScanExpression can also continue to process any additional tokens in the expression. All that's left is to deal with primary expressions:
Primary:
• Number
• ( Expression )
Because the Scanner class itself deals with parsing numbers, the implementation of the ScanPrimary function is relatively simple:
bool ScanPrimary(Scanner & scanner, float & value)
{
Token const token = scanner.Read();
// ...
}
It's only responsible for parsing a single primary. There are no operators to deal with, so there's no need for a loop. First, it must accept number tokens:
if (Token::Number == token)
{
value = scanner.GetNumber();
return true;
}
It must also accept expressions within parentheses. Here, the ScanPrimary function can rely on the ScanExpression function so that it can accept addition and subtraction within expressions. This provides for the primary use case of allowing operator precedence to be overridden:
else if (Token::LeftParenthesis == token)
{
if (!ScanExpression(scanner, value)) return false;
if (Token::RightParenthesis != scanner.Read()) return false;
return true;
}
Of course, ScanExpression calls ScanTerm and ScanTerm calls ScanPrimary, so "(1)" is perfectly acceptable. So, assuming a Token::LeftParenthesis is encountered, the ScanExpression function is called to parse the expression itself, and the scanner is called again to ensure that a Token::RightParenthesis follows. Finally, if any other token is encountered, the token sequence doesn't conform to the expected grammar and I can reject it:
else
{
return false;
}
Now, given the following expression:
> type c:\temp\Sample.b
1.2 + 3. * .4 / (4 + 5)
I can check with the Windows Calculator in scientific mode, shown in Figure 1, and I can see whether my parser concurs:
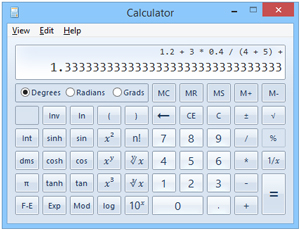 [Click on image for larger view.]
Figure 1. The Windows Calculator Confirms the Correct Code
[Click on image for larger view.]
Figure 1. The Windows Calculator Confirms the Correct Code
> Sample.exe
Result: 1.33
Looks good! Given a simple grammar, I was able to implement a decent interpreter for mathematical expressions. The parser divides the work of analyzing the source program into three functions -- or sets or rules -- that cooperate to get the job done. There is of course much more to be done. More questions come to mind: What about performance? What about repeatedly scanning tokens when backtracking? Is backtracking really necessary? What about some algebra? Join me next time where I'll consider comments, error handling, and in particular pinpointing where in the source code an error might occur. Listing 2 shows the three parsing functions for clarity.
Listing 2: The Three Parsing Functions
bool ScanExpression(Scanner & scanner, float & value)
{
if (!ScanTerm(scanner, value)) return false;
for (;;)
{
Token const token = scanner.Read();
if (Token::Add == token)
{
float other = 0.0f;
if (!ScanTerm(scanner, other)) return false;
value += other;
}
else if (Token::Subtract == token)
{
float other = 0.0f;
if (!ScanTerm(scanner, other)) return false;
value -= other;
}
else if (Token::Invalid == token)
{
return false;
}
else
{
scanner.Backtrack();
return true;
}
}
}
bool ScanTerm(Scanner & scanner, float & value)
{
if (!ScanPrimary(scanner, value)) return false;
for (;;)
{
Token const token = scanner.Read();
if (Token::Multiply == token)
{
float other = 0.0f;
if (!ScanPrimary(scanner, other)) return false;
value *= other;
}
else if (Token::Divide == token)
{
float other = 0.0f;
if (!ScanPrimary(scanner, other)) return false;
if (!other) return false;
value /= other;
}
else
{
scanner.Backtrack();
return true;
}
}
}
bool ScanPrimary(Scanner & scanner, float & value)
{
Token const token = scanner.Read();
if (Token::Number == token)
{
value = scanner.GetNumber();
return true;
}
else if (Token::LeftParenthesis == token)
{
if (!ScanExpression(scanner, value)) return false;
if (Token::RightParenthesis != scanner.Read()) return false;
return true;
}
else
{
return false;
}
}