Z Code
Windows Cloud: Choosing Between Windows Azure and SQL Azure Table Storage
Both are equally good cloud storage mechanisms -- here's the pros and cons of each so you can make the best decision for your projects.
- By Joseph Fultz
- 03/09/2012
I find many of my customers and colleagues have a hard time
deciding what storage mechanism to use in the cloud. Often, the point of
confusion is understanding the differences between Windows Azure Table
Storage and SQL Azure.
I can't tell anyone which technology choice to make, but I will provide
some guidelines for making the decision when evaluating the needs of the
solution and the solution team against the features and the constraints
for both Windows Azure Table Storage and SQL Azure. Additionally, I'll add
in a sprinkle of code so you can get the developer feel for working with
each.
Data Processing
SQL Azure and other relational databases usually
provide data-processing capabilities on top of a storage system.
Generally, RDBMS users are more interested in data processing than the raw
storage and retrieval aspects of a database.
For example, if you want to find out the total revenue for the company
in a given period, you might have to scan hundreds of megabytes of sales
data and calculate a SUM. In a database, you can send a single query (a
few bytes) to the database that will cause the database to retrieve the
data (possibly many gigabytes) from disk into memory, filter the data
based on the appropriate time range (down to several hundred megabytes in
common scenarios), calculate the sum of the sales figures and return the
number to the client application (a few bytes).
To do this with a pure storage system requires the machine running the
application code to retrieve all of the raw data over the network from the
storage system, and then the developer has to write the code to execute a
SUM on the data. Moving a lot of data from storage to the app for data
processing tends to be very expensive and slow.
SQL Azure provides data-processing capabilities through queries,
transactions and stored procedures that are executed on the server side,
and only the results are returned to the app. If you have an application
that requires data processing over large data sets, then SQL Azure is a
good choice. If you have an app that stores and retrieves (scans/filters)
large datasets but does not require data processing, then Windows Azure
Table Storage is a superior choice.
—Tony Petrossian, Principal Program Manager,
Windows Azure
Reviewing the Options
Expanding the scope briefly to include the other storage mechanisms in
order to convey a bit of the big picture, at a high level it's easy to
separate storage options into these big buckets:
- Relational data access: SQL Azure
- File and object access: Windows Azure Storage
- Disk-based local cache: role local storage
However, to further qualify the choices, you can start asking some
simple questions such as:
- How do I make files available to all roles commonly?
- How can I make files available and easily update them?
- How can I provide structured access semantics, but also provide
sufficient storage and performance?
- Which provides the best performance or best scalability?
- What are the training requirements?
- What is the management story?
The path to a clear decision starts to muddy and it's easy to get lost
in a feature benefit-versus-constraint comparison. Focusing back on SQL
Azure and Windows Azure Table Storage, I'm going to describe some ideal
usage patterns and give some code examples using each.
SQL Azure Basics
SQL Azure provides the base functionality of a relational database for
use by applications. If an application has data that needs to be hosted in
a relational database management system (RDBMS), then this is the way to
go. It provides all of the common semantics for data access via SQL
statements. In addition, SQL Server Management Studio (SSMS) can hook
directly up to SQL Azure, which provides for an easy-to-use and well-known
means of working with the database outside of the code.
For example, setting up a new database happens in a few steps that need
both the SQL Azure Web Management Console and SSMS. Those steps are:
- Create database via Web
- Create rule in order to access database from local computer
- Connect to Web database via local SSMS
- Run DDL within context of database container
If an application currently uses SQL Server or a similar RDBMS back
end, then SQL Azure will be the easiest path in moving your data to the
cloud.
SQL Azure is also the best choice for providing cloud-based access to
structured data. This is true whether the app is hosted in Windows Azure
or not. If you have a mobile app or even a desktop app, SQL Azure is the
way to put the data in the cloud and access it from those
applications.
Using a database in the cloud is not much different from using one
that's hosted on-premises—with the one notable exception that
authentication needs to be handled via SQL Server Authentication. You
might want to take a look at Microsoft Project Code-Named "Houston," which
is a new management console being developed for SQL Azure, built with
Silverlight. Details on this project are available at sqlazurelabs.cloudapp.net/houston.aspx.
SQL Azure Development
Writing a quick sample application that's just a Windows Form hosting
a datagrid that displays data from the Pubs database is no more
complicated than it was when the database was local. I fire up the wizard
in Visual Studio to add a new data source and it walks me through creating
a connection string and a dataset. In this case, I end up with a
connection string in my app.config that looks like this:
<add name="AzureStrucutredStorageAccessExample.Properties.Settings.pubsConnectionString"
connectionString="Data Source=gfkdgapzs5.database.windows.net;Initial Catalog=pubs;
Persist Security Info=True;User ID=jofultz;Password=[password]"
providerName="System.Data.SqlClient" />
Usually Integrated Authentication is the choice for database security,
so it is feels a little awkward using SQL Server Authentication again. SQL
Azure minimizes exposure by enforcing an IP access list to which you will
need to add an entry for each range of IPs that might be connecting to the
database.
Going back to my purposefully trivial example, by choosing the
Titleview View out of the Pubs database, I also get some generated code in
the default-named dataset pubsDataSet, as shown in Figure
1.
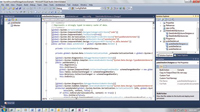
[Click on image for larger view.] |
| Figure 1. Automatically Generated Code for Accessing SQL
Azure |
I do some drag-and-drop operations by dragging a DataGridView onto the
form and configure the connection to wire it up. Once it's wired up, I run
it and end up with a quick grid view of the data, as shown in
Figure 2.
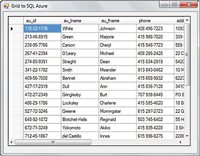
[Click on image for larger view.] |
| Figure 2. SQL Azure Data in a Simple Grid |
I'm not attempting to sell the idea that you can create an enterprise
application via wizards in Visual Studio, but rather that the data access
is more or less equivalent to SQL Server and behaves and feels as
expected. This means that you can generate an entity model against it and
use LINQ just as I might do so if it were local instead of hosted (see
Figure 3).
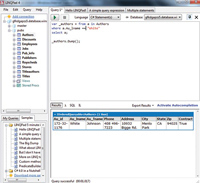
[Click on image for larger view.] |
| Figure 3. Using an Entity Model and LINQ |
A great new feature addition beyond the scope of the normally available
SQL Server-based local database is the option (currently available via sqlazurelabs.com) to expose the data
as an OData feed. You get REST queries such as this:
https://odata.sqlazurelabs.com/
OData.svc/v0.1/gfkdgapzs5/pubs/
authors?$top=10
This results in either an OData response or, using the $format=JSON
parameter, a JSON response. This is a huge upside for application
developers, because not only do you get the standard SQL Server behavior,
but you also get additional access methods via configuration instead of
writing a single line of code. This allows for the focus to be placed on
the service or application layers that add business value versus the
plumbing to get data in and out of the store across the wire.
If an application needs traditional relational data access, SQL Azure
is most likely the better and easier choice. But there are a number of
other reasons to consider SQL Azure as the primary choice over Windows
Azure Table Storage.
The first reason is if you have a high transaction rate, meaning there
are frequent queries (all operations) against the data store. There are no
per-transaction charges for SQL Azure.
SQL Azure also gives you the option of setting up SQL Azure Data Sync
(sqlazurelabs.com/SADataSync.aspx)
between various Windows Azure databases, along with the ability to
synchronize data between local databases and SQL Azure installations (microsoft.com/windowsazure/developers/sqlazure/datasync/).
I'll cover design and use of SQL Azure and DataSync with local storage in
a future column, when I cover branch node architecture using SQL
Azure.
Windows Azure Table Storage
Now you've seen the advantages of using SQL Azure for your storage. So
when is it more beneficial to rely on Windows Azure Table Storage? Here
are a number of scenarios where SQL Azure might not be the right
choice.
If an application is being overhauled for moving to the Web or the
data storage layer implementation isn't completed, you probably want to
take a look at Windows Azure Table Storage. Likewise, Windows Azure Table
Storage makes sense if you don't need a relational store or access is
limited to a single table at a time and doesn't require joins. In this
case, your data sets would be small and joins could be handled client-side
by LINQ.
You'll also want to take a look at Windows Azure Table Storage if you
have more data than the maximum amount supported by SQL Azure (which is
currently 50GB for a single instance). Note that size limitation can be
overcome with some data partitioning, but that could drive up the SQL
Azure costs. The same space in Windows Azure Table Storage would probably
be less expensive and has partitioning built-in by a declared partition
key.
In addition, due to the per-transaction charges for Windows Azure
Table Storage, data with a lower-access frequency or data that can be
easily cached would be a good choice.
Some other things that make Windows Azure Table Storage appealing
include if the application needs some structured style access such as
indexed lookup, but stores primarily objects or Binary Large Objects
(BLOBs)/Character Large Objects (CLOBs); if your app would benefit from
supporting type variability for the data going into the table; or if the
existing data structure (or lack therof) in your SQL Server installation
makes it difficult to migrate.
Using Windows Azure Table Storage
At first, working with Windows Azure Table Storage may seem a little
unwieldy due to assumptions made by relating "table storage" to a SQL
database. The use of "table" in the name doesn't help. When thinking about
Windows Azure Table Storage, I suggest that you think of it as object
storage.
As a developer, don't focus on the storage structure or mechanism;
instead, focus on the object and what you intend to do with it. Getting
the objects set up in Windows Azure Table Storage is often the biggest
hurdle for the developer, but accessing Windows Azure Table Storage via
objects is natural, particularly if you employ LINQ.
To work with Windows Azure Table Storage, start by adding a reference
to System.Data.Services.Client to your project. In addition, add a
reference to Microsoft.WindowsAzure.StorageClient.dll if you aren't
working in a Visual Studio Cloud template (which provides this reference
for you).
Next, create an object/entity with which you can work (stealing from
the Authors table):
public class TableStorageAuthor:
Microsoft.WindowsAzure.StorageClient.TableServiceEntity {
public int Id {get; set;}
public string LastName { get; set; }
public string FirstName { get; set; }
public string Phone { get; set; }
public string Address { get; set; }
public string City { get; set; }
public string State { get; set; }
public string Zip {get; set;}
}
You can define a data service client context using TableServiceContext
to handle connecting to the store and do the Create/Read/Update/Delete
(CRUD) operations as shown in Listing 1. The
TableStorageAuthor class is used as the template class to declare the
AuthorData element for which a table query method for the Authors table is
returned. It's also used as a parameter type to the implemented Add
operation.
Create the target table:
TableClient.CreateTableIfNotExist("Authors");
Using a familiar object creation and property assignment paradigm,
create some data and add it to the table that was created in storage (see
Listing 2).
Once all of the data is there it can be manipulated with LINQ. For
example, a select for the entities would be:
AuthorDataServiceContext ctx =
new AuthorDataServiceContext(
StorageAccount.TableEndpoint,
StorageAccount.Credentials);
var authors =
from a in ctx.AuthorData
select a;
foreach (TableStorageAuthor ta in authors) {
Debug.WriteLine(ta.FirstName + " " + ta.LastName);
}
I didn't implement update and delete, but they would be similar. The
only thing that might be a little different from those that have used LINQ
with the Entity Framework is the code to create the TableServiceContext
and the subsequent code to construct and use it. If you've been working
with REST and the DataServiceContext, doing this work will be quite
natural.
By using the TableServiceContext, TableServiceEntity and LINQ, you get
about the same feel as using the Entity Framework and LINQ with SQL
Azure—albeit with a little more hand-coding on the Windows Azure Table
Storage side.
Solution-Based Evaluation
As mentioned before, if the application has a relational store already
established, it's likely best to migrate that to SQL Azure with a little
help from a tool like the SQL Azure Migration Wizard. However, if that's
not the case, or the cloud piece of the application doesn't need the full
functionality of an RDBMS, then take a look at the matrix in
Table 1 and see which columns meet most of the needs of
the solution requirements and architecture.
Table 1 Comparing SQL Azure and Windows Azure Table
Storage
| Feature |
SQL Azure |
Common Benefit(s) |
Windows Azure Table
Storage |
| Select semantics |
Cross-table queries |
Primary key-based lookup |
Single key lookup (by partition) |
| Performance and scale |
High performance via multiple indices, normalized
data structures and so on, and scalable via manual partitioning
across SQL Azure instances |
|
Automatic mass scale by partition and consistent
performance even at large scale |
| User experience |
Well-known management tools and traditional
database design |
Familiar high-level developer experience |
Direct serialization; no ORM necessary; simplified
design model by removing relational model |
| Storage style |
Traditional relational design model |
Data storage for all types of data |
Type variability in a single table |
| Cost factors |
No transaction cost, pay by database size |
Network traffic cost outside of same datacenter |
No space overhead cost, pay for what is used |
| Data loading and sync |
Synchronizing between local and cloud-based stores;
data easily moved in and out by traditional extract, transform and
load (ETL) mechanisms; synchronizing between SQL Azure databases in
different datacenters |
|
|
It's important to note that for some of the items in Table 1 (for example, those related to management and data loading for
Windows Azure Table Storage) there are already third-party solutions
entering the market to provide the missing functionality. As such, the
cost and functionality of such tools will need to be considered for
significant projects.
I expect that many applications will need a hybrid data approach to
make the best use of technology. For example, Windows Azure Table Storage
would be used to optimize fetch times while still providing mass scale for
resources such as documents, videos, images and other such media. However,
to facilitate searching metadata for the item, related data and object
pointers would be stored in SQL Azure. Such a design would also reduce the
transaction traffic against Windows Azure Table Storage. This type of
complementary design would provide the following benefits:
- Keep the throughput high for queries to find resources
- Keep the SQL Azure database size down, so cost for it remains a
minimum
- Minimize the cost of storage by storing the large files in Windows
Azure Table Storage versus SQL Azure (though BLOB storage is preferred
for files)
- Maintain a fast retrieval performance by having such resources fetch
by key and partition, and offloading the retrieval query from the SQL
Azure database
- Allow for automatic and mass scale for the data kept in Windows
Azure Table Storage
Simply put: Your design should allow each storage mechanism to provide
the part of the solution that it's best at performing, rather than trying
to have one do the job of both. Either way, you're still looking to the
cloud for an answer.