Modern C++
An API for Simple HTTP Requests
Yes, sometimes you need sophisticated libraries that handle HTTP requests asynchronously, but in other situations that can be overkill. An old Internet Explorer API may have a solution.
I've written in the past about HTTP, how to perform asynchronous HTTP requests efficiently and how to use WebSockets in various ways, but sometimes it pays to keep it simple. There's certainly a growing need for more sophisticated libraries that handle HTTP requests and that do so in an asynchronous manner, allowing developers to write responsive applications more easily. On the other hand, such libraries tend to be more difficult to use in simple scenarios where I might not need asynchrony. What if I just need a console application to download a file from the Web? A sophisticated asynchronous programming model is often overkill and can add a lot of complexity. Also, responsiveness isn't really an issue, although some form of progress reporting might still be important. It turns out that, in these situations, some older APIs can come in handy.
URLDownloadToCacheFile is one such API and comes courtesy of Internet Explorer. This function is ideally suited to console applications because it doesn't imply any particular threading model. It blocks while the file is downloaded and provides progress reporting using a callback. I'm going to show you how to use it to write a console application to download a given HTTP resource, present progress and download the file. The idea is to produce an executable that I can run as follows:
download.exe http://live.sysinternals.com/procexp.exe
This command should download Process Explorer from Sysinternals, provide some feedback on its progress and then launch the application before coming to an end (see Figure 1).
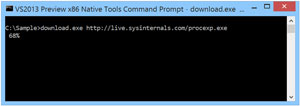 [Click on image for larger view.]
Figure 1. Downloading Process Explorer from Sysinternals
[Click on image for larger view.]
Figure 1. Downloading Process Explorer from Sysinternals
Because the Windows API is predominantly a Unicode API, I'll begin with the Unicode variant of the standard entry point function:
int wmain(int argc, wchar_t ** argv)
{
}
I'll just weed out the obvious lack of a URL:
if (argc < 2)
{
wprintf(L"How about a URL?\n");
return 0;
}
Console applications aren't particularly flashy, but users do appreciate a little attention to detail nonetheless. It isn't hard to add a few small touches to improve the overall experience. The first thing I'll do is get hold of the handle for the standard output device:
HANDLE console = GetStdHandle(STD_OUTPUT_HANDLE);
This allows me to do things like hide the cursor while the download is in progress and even move the cursor around. It isn't particularly obvious how this is done, so I'll just add a helper function or two to take care of it. First up is the ShowCursor function to show or hide the console's cursor:
static void ShowCursor(HANDLE console,
bool visible = true)
{
}
Inside this helper function, I first need to call the GetConsoleCursorInfo function to get the cursor's current size and visibility:
CONSOLE_CURSOR_INFO info;
VERIFY(GetConsoleCursorInfo(console,
&info));
In this way, I'm careful not to make any assumptions about the state of the cursor. I can then update the bVisible member as needed and call the SetConsoleCursorInfo function to apply the change:
info.bVisible = visible;
VERIFY(SetConsoleCursorInfo(console,
&info));
Next is the GetPosition helper function to retrieve the current coordinates of the cursor within the console:
static COORD GetPosition(HANDLE console)
{
}
The COORD structure just provides the X and Y position of the cursor. My console application doesn't really care what the coordinates are, but will use them to restore the cursor position after printing progress messages to the console. Setting the cursor position is simple enough, but getting the current position involves getting a set of screen and console attributes and pulling out the cursor position:
CONSOLE_SCREEN_BUFFER_INFO info;
VERIFY(GetConsoleScreenBufferInfo(console,
&info));
return info.dwCursorPosition;
Before I can call the URLDownloadToCacheFile function to download the file, I need to implement the callback. This callback takes the form of a COM-style interface implementation. My application needs to provide the function with an IBindStatusCallback interface pointer. Implementing COM interfaces can be tedious, but the Windows Runtime C++ Template Library (WRL) hides much of the tedium behind an elegant and modern C++ class template called RuntimeClass. If you aren't familiar with the WRL, don't be fooled by its name; although it's designed to support the implementation of Windows Runtime components, it's mostly just an excellent library for implementing and using COM classes and interfaces. I just need to tell the RuntimeClass class template that I'm after classic COM semantics and give it a list of interfaces I intend to implement:
struct ProgressCallback :
..RuntimeClass<RuntimeClassFlags<ClassicCom>,
IBindStatusCallback>
{
};
RuntimeClass takes care of implementing reference counting and provides the prerequisite implementation of QueryInterface. Implementing IUnknown isn't particularly difficult, but it can be tedious and even error-prone as more interfaces are added to a class. Using RuntimeClass, it's as simple as adding additional template parameters listing the interfaces you intend to implement. Before I get to that implementation, I'll just add a simple constructor. In that way, I can pass the console handle and cursor position to the ProgressCallback object:
HANDLE m_console;
COORD m_position;
ProgressCallback(HANDLE console,
COORD position) :
..m_console(console),
..m_position(position)
{}
Inside my application's wmain function, I can simply create a ProgressCallback object on the stack:
ProgressCallback callback(console,
GetPosition(console));
Normally I'd use the WRL make function template to create an instance of the class on the heap, but because the lifetime of the callback is limited to a synchronous function call, I can simply create it on the stack. Of course, I still need to conclude its implementation. The IBindStatusCallback interface defines a number of methods, but only OnProgress is required in order for my application to keep track of the operation's progress. The remaining methods can be safely ignored. I just need to implement them by returning the E_NOTIMPL error code. The source code is available at the top of this article, so here I'll just focus on the one that actually needs implementing:
HRESULT __stdcall OnProgress(ULONG progress,
ULONG progressMax,
ULONG,
LPCWSTR) override
{
return S_OK;
}
The last two parameters provide more detailed status information about the ongoing operation. For my purposes, all I care about is the percentage of progress I can report to the user. It's possible that the API won't be able to provide reliable progress notifications if the server doesn't provide the necessary HTTP headers for the particular resource. I can handle that easily enough:
if (0 < progress && progress <= progressMax)
{
}
Keep in mind that the progressMax value might change from one call to the next, so don't rely on its exact value or that it will remain constant.
Given these values, I can derive a percentage value to indicate the progress to the user:
float percentF = progress * 100.0f / progressMax;
I'll then cap this value to avoid rounding errors and report it as an unsigned value:
unsigned percentU = min(100U, static_cast<unsigned>(percentF));
I can then use the SetConsoleCursorPosition function to set the console's cursor position before printing the percentage value:
VERIFY(SetConsoleCursorPosition(m_console,
m_position));
wprintf(L"%3d%%\n",
percentU);
In this way, the value reported in the console will appear to update in-place. Each successive progress update resets the cursor position and updates the value. That's it for my ProgressCallback class.
Back in my application's wmain function, I'm just going to hide the cursor for the duration of the download:
ShowCursor(console, false);
URLDownloadToCacheFile( ... );
ShowCursor(console);
In addition to the callback, the URLDownloadToCacheFile function expects a buffer where it will copy the file name where the resource is stored in the browser's cache:
wchar_t filename[MAX_PATH];
It's finally time to call the API function itself:
auto hr = URLDownloadToCacheFile(nullptr, // Caller
argv[1],
filename,
_countof(filename),
0, // Reserved
&callback);
The first parameter provides the controlling IUnknown of the caller. I won't need this. Instead, I'll just let the function call my application back via the callback interface provided in the last parameter. The second parameter provides the function with the URL to download: I'm simply passing along the command-line argument the user provided. The next two parameters let the function know where to copy the resulting file name. As I mentioned before, this function blocks until the download is complete. Of course, because it relies on the browser's cache, it may well serve up the resource directly from the cache, in which case no actual HTTP connection will be needed and the download will appear to complete very quickly indeed.
There are, of course, many additional benefits of using the Internet Explorer infrastructure to download content, from caching, integrated security and compression, to automatic redirect handling, proxy negotiation and much more. Still, it's possible that the operation will fail for a variety of reasons. The resulting HRESULT provides my application with more specific information:
if (S_OK != hr)
{
wprintf(L"Download error: 0x%x\n", hr);
}
I can also use the FormatMessage function to retrieve a descriptive error message corresponding to the given HRESULT. Assuming it succeeded, however, I can simply call the ShellExecute function to open or run the downloaded file:
ShellExecute(nullptr,
nullptr,
filename,
nullptr,
nullptr,
SW_SHOWDEFAULT);
Don't underestimate the amount of power at your fingertips. Internet Explorer is doing a great deal of heavy lifting on my behalf. That's one of the many benefits of working on the Windows OS. Until next time, keep it simple!
About the Author
Kenny Kerr is a computer programmer based in Canada, an author for Pluralsight and a Microsoft MVP. He blogs at kennykerr.ca and you can follow him on Twitter at twitter.com/kennykerr.