In-Depth
Why I'm Excited About DocumentDB
DocumentDB brings together the best of No-SQL and the cloud, to give you a robust scalable data persistence engine. Here's what you need to know to start developing projects with it.
- By Brian Korzynski
- 07/22/2015
DocumentDB is a new document database offering from Microsoft Azure. It brings together the best of No-SQL and the cloud, to give you a robust scalable data persistence engine. If you're already familiar with document databases such as MongoDB or RavenDB, it works similarly. If you haven't played around with them yet, then DocumentDB is a good one to start with, because you don't have to worry about provisioning a server or configuring the installation.
Before we get too far we first need to discuss how DocumentDB is laid out so that you know what the different portions are when we refer to them later on. The database itself acts as a container of collections. Collections are simply a grouping of documents, and documents are serialized data records (see Figure 1). I tend to think of documents as rows and collections as tables in a relational database sense. If you aren't familiar with document databases, you'll typically have the entire object graph serialized to a single document instead of splitting out the data into separate tables. More on this later.
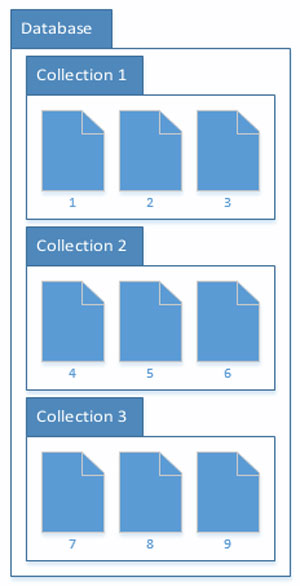 Figure 1. Documents and Collections
Figure 1. Documents and Collections
Because DocumentDB is still a new technology, you have to go into the preview portal (see Figure 2) to set things up.
 [Click on image for larger view.]
Figure 2. DocumentDB Preview Portal
[Click on image for larger view.]
Figure 2. DocumentDB Preview Portal
Once there, follow the steps as outlined in Figure 3 to create the account that you'll use for the database.
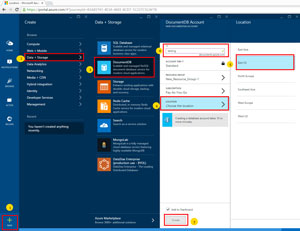 [Click on image for larger view.]
Figure 3. Steps to Create an Account
[Click on image for larger view.]
Figure 3. Steps to Create an Account
After creating the database account you can now create the database itself (see Figure 4).
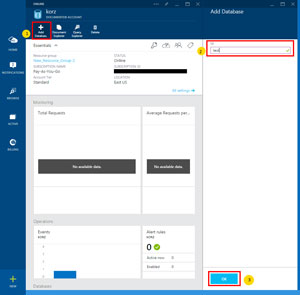 [Click on image for larger view.]
Figure 4. Creating a Database
[Click on image for larger view.]
Figure 4. Creating a Database
Once the database is created, you'll need both the URI and the Primary Key, as shown in Figure 5, so that you can work with the database within code. This will allow you to do things like create collections or perform CRUD operations with documents.
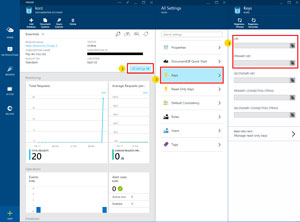 [Click on image for larger view.]
Figure 5. Creating the URI and Primary Key
[Click on image for larger view.]
Figure 5. Creating the URI and Primary Key
Within the solution of the sample code, there is a project called DocumentDb.CreateDatabase that shows you how you can do several things to administer a database. Use this to create your collection within the database. In order to run this, simply copy in your URI and Primary Key from the portal to the EndpointUrl and AuthorizationKey, respectively. Then you can run the CreateCollection method against the database you just created. Note that this code is setup to first create a database. If you want to use the database you just created please refer to the FindDatabase method within the DocumentDb project (Program.cs). This was done intentionally to show you how you can use the client to either create a database or find an existing one.
The DocumentDb project in the solution shows how you can perform basic data operations (Create, Read, Update, Delete) against a database, using a pseudo-realistic example. Again, just like with the create database application, you'll need to copy in the URI and Primary Key. For this example, I included the Microsoft Azure DocumentDB Client Library (via NuGet) so the Azure SDK can be used to create a client to interact with the database. You'll see this used throughout.
Just like with any good application, you need to start with your data objects with which you'll be working. In my example, I have a Customer object that has a collection of Orders. While this example is contrived, it demonstrates how you can build up any object graph and you can see how it gets serialized and stored within the database. Note that the Id property of the Customer object has a JsonProperty attribute around it. This is because DocumentDB always looks for a field exactly called id. If it doesn't find it, it will automatically create one and use it. Adding the JsonProperty attribute allows you to specify whatever you like for the ID within code and then map to id when serialized.
The starting point of the application (Program.cs) shows how to create the client, find the database and collection, then use the CustomerRepository to perform CRUD operations with documents. Once both the database and the collection are found, the SelfLink of the collection is grabbed and, in addition to the client, gets passed into the repository. Storing the SelfLink within the application configuration allows you to tell the client where to find the collection without having to look it up every time you run the application. From there, the repository and sample data are created, and then the repository is tested. After you run the Create method of the repository you can preview the data within the portal (see Figure 6). This shows how the Customer object graph gets serialized to JSON.
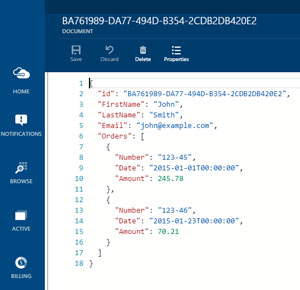 [Click on image for larger view.]
Figure 6. Previewing Data Within the Portal
[Click on image for larger view.]
Figure 6. Previewing Data Within the Portal
Next, take a look at the CustomerRepository. The client provides methods for persisting data to the database. The create (CreateDocumentAsync) and delete (DeleteDocumentAsync) operations are straightforward. However, the read and update methods are a little trickier. To read, you need to create a document query (CreateDocumentQuery) that will then be run against the database in order to find documents. This procedure is followed whether you're finding an exact document by id, finding all documents or finding documents that meet a certain set of criteria. The nice thing about this is that it fully supports LINQ so you can write database queries just like you do with Entity Framework. When updating, records get replaced (ReplaceDocumentAsync) instead of updated. Note that all of these methods are asynchronous, but I'm forcing them to be synchronous to make the application easier to follow.
There are many advantages to using DocumentDB. First, it's cloud-based. This means you get all of the goodness the cloud has to offer, such as high availability, high scalability and predictable pricing. It stores its data in JSON, which is ubiquitous in today's applications. Also, because more modern technologies are utilizing JavaScript, DocumentDB fully supports JavaScript for transactions and for things such as triggers. The provided SDK makes it very easy to get up and running in no time.
However, there are a few disadvantages. It isn't the perfect solution for all problems. One reason is that it's write-optimized, and this could be a huge performance problem if your application does more reading than writing. Another problem is that the technology is still new, so it isn't as rich as other document database systems that you might already be using.
Previously, DocumentDB was really expensive, but recently Microsoft released a new pricing scheme to make it cheaper and easier to follow. At the time of this article, you pay for the amount of bandwidth you need per collection. Collections are capped at 10GB -- if you have more data than that, you need to split it across different collections. So if you only send 250 requests per second, then it will cost you $0.034 per hour. For more details on pricing go to DocumentDB pricing site.
DocumentDB is an easy-to-use document database in Azure that functions the same as other document databases you might have used. So how will you incorporate it in your applications today?
About the Author
Brian Korzynski is the lead developer of UseTech Design, a .NET consulting firm based in Troy, MI, and has been involved in a number of projects, from database development with WinForms to enterprise-level Web applications. He specializes in software engineering, architecture, .NET, SQL Server, MVC, and mathematics.