Neural Network Lab
Neural Network Binary Classification
The differences between neural network binary classification and multinomial classification are surprisingly tricky. McCaffrey looks at two approaches to implement neural network binary classification.
In a classification problem, the goal is to predict the value of a variable that can take one of several discrete values. For example, you might want to predict the political inclination (conservative, moderate, liberal) of a person based on their age, income and other features. Or you might want to predict the sex (male, female) of a person based on age, height, empathy and so on.
Problems where the variable to predict can take one of just two possible values (such as male or female) are called binary classification problems. Problems where the variable to predict can take one of three or more values are described using several different terms, including multiclass classification and multinomial classification.
The differences between neural network binary classification and multinomial classification are surprisingly tricky. In this article I explain two different approaches to implement neural network binary classification.
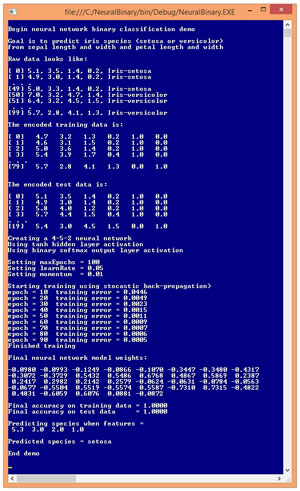
The best way to see where this article is headed is to examine the screenshot of a demo program shown in Figure 1. The goal of the demo program is to predict the species of an iris flower (Iris setosa or Iris versicolor) using the flower's sepal (a leaf-like structure) length and width, and petal length and width.
 [Click on image for larger view.]
Figure 1. Neural Network Binary Classification in Action
[Click on image for larger view.]
Figure 1. Neural Network Binary Classification in Action
The demo data is part of a famous data set called Fisher's Iris Data. The full data set has three species, setosa, versicolor and virginica. The program uses just two species (setosa and versicolor) in order to demonstrate binary classification. There are 50 examples of each species so the demo has a total of 100 data items.
The raw data was preprocessed by encoding each species using two numeric values: setosa as (1, 0) and versicolor as (0, 1). As you'll see shortly, the important alternative approach in neural network binary classification is to encode the variable to predict using just one value, for example, setosa as 0 and versicolor as 1. Understanding the differences between the two approaches for binary classification -- using two output nodes or one output node -- is the main focus of this article.
There is no standard terminology to describe the two approaches to neural network binary classification. I'll refer to them as the two-node technique and the one-node technique. The one-node technique is more common, but I prefer the two-node technique.
Using either the one-node technique or the two-node technique, the order of encoding is arbitrary but you must be consistent. For example, the demo could have encoded setosa as (0, 1) and versicolor as (1, 0). And if the demo had used the one-node technique, either setosa or versicolor could have been encoded as 0 and the other species as 1.
In addition to preprocessing the raw data by encoding Iris species using the two-node technique, the data was randomly split into a training set and a test set. The training set has 80 items (80 percent of the total number of data items), 40 of each of the two species. The test set has 20 items, 10 of each species.
The demo creates a 4-5-2 neural network. There are four input nodes, one for each predictor variable. The demo input data was not normalized because the values of the predictor variables all have roughly the same magnitude so no one feature will dominate the others. The number of hidden nodes, 5, was selected using trial and error. There are two output nodes because the demo is using the two-node technique for binary classification.
A fully connected 4-5-2 neural network has (4 * 5) + 5 + (5 * 2) + 2 = 37 weights and biases. The demo program uses the back-propagation algorithm to find the values of the weights and biases so that the computed output values (using training data input values) most closely match the known correct output values in the training data.
As it turns out, Fisher's Iris data is very easy to classify. The demo program is able to find weights and bias values so that prediction accuracy on both the training data and the test data is 100 percent. The demo finished by using the resulting trained model to predict the species of an Iris flower with somewhat ambiguous feature values of (5,3, 3.0, 2.0, 1.0), and concludes the species of the unknown flower is setosa.
This article assumes you have at least intermediate-level developer skills and a basic understanding of neural networks, but does not assume you are an expert. The demo program is too long to present in its entirety here, but complete source code is available in the download that accompanies this article. All normal error checking has been removed to keep the main ideas of neural network binary classification as clear as possible.
Two-Node Technique for Binary Classification
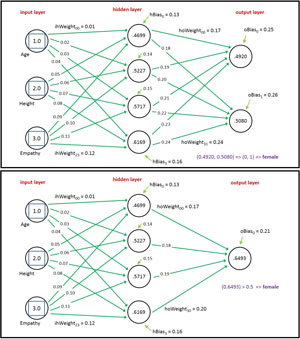
There are two ways to design a binary neural network classifier, the two-node technique used by the demo program, and the one-node technique. The two approaches are illustrated in Figure 2. Both diagrams in Figure 2 correspond to a problem where the goal is to predict the sex of a person based on their age, height and some measure of empathy.
 [Click on image for larger view.]
Figure 2. Two Approaches for Binary Classification
[Click on image for larger view.]
Figure 2. Two Approaches for Binary Classification
In the top diagram in Figure 2, output value male is encoded as (1, 0) and female is encoded as (0, 1). For the given set of input values (1.0, 2.0, 3.0) and indicated weights and biases, the two output node values are (0.4920, 0.5080). The larger of the two output node values is in the second position (just barely) so the computed output values map to (0, 1) and so the neural network predicts the person is female.
Neural network classifiers that have two or more output nodes use softmax activation. For the neural network in the top diagram in Figure 2, the top-most output node's preliminary value is computed like so:
pre[0] = (0.4699)(0.17) + (0.5227)(0.19) + (0.5717)(0.21) + (0.6169)(0.23) + 0.25 = 0.6911
Similarly, the preliminary value of the bottom output node is:
pre[1] = (0.4699)(0.18) + (0.5227)(0.20) + (0.5717)(0.22) + (0.6169)(0.24) + 0.26 = 0.7230
To compute the final output node values using softmax activation, first the sum of the Exp function of each preliminary value is computed:
sum = Exp(0.6911) + Exp(0.7230) = 4.0565
The Exp function of some value is just Euler's number, e = 2.71828..., raised to the value. Next, the Exp of each preliminary output node value is divided by the scaling sum to give the final output values:
output[0] = Exp(pre[0]) / sum = 1.9959 / 4.0565 = 0.4920
output[1] = Exp(pre[1]) / sum = 2.0606 / 4.0565 = 0.5080
The point of softmax activation is to scale the output node values so that they sum to 1.0. Then the output values can be loosely interpreted as probabilities and easily mapped to one of the encoded classes to predict.
One-Node Technique
The one-node technique for neural network binary classification is shown in the bottom diagram in Figure 2. Here, male is encoded as 0 and female is encoded as 1 in the training data. The value of the single output node is 0.6493. Because this value is closer to 1 than to 0, the neural network predicts the person is female.
When using the one-node technique for binary classification, the single output node value is computed using log-sigmoid activation. The preliminary single output node value is computed as:
pre[0] = (0.4699)(0.17) + (0.5227)(0.18) + (0.5717)(0.19) + (0.6169)(0.20) + 0.21 = 0.6160
The final value of the output node is computed by applying log-sigmoid:
output[0] = 1.0 / (1.0 + Exp( -0.6160 )) = 0.6493
Although it's not immediately obvious, the result of the log-sigmoid activation function will always be a value between 0.0 and 1.0 and so the output value can be loosely interpreted as the probability of the class that is encoded as 1 (female).
Equivalently, when using the one-node technique, if the output value is less than 0.5 the predicted class is the one corresponding to 0, and if the output value is greater than 0.5 the predicted class is the one corresponding to 1. (For an output value of exactly equal to 0.5 you can flip a coin.)
Which Approach Is Better?
So, which design for neural network binary classification -- the one-node technique or the two-node technique -- is better? At first thought, the one-node technique would seem to be preferable because it requires fewer weights and biases, and therefore should be easier to train than a neural network that uses the two-node technique. And, in fact, the one-node technique is the most common approach used for neural network binary classification.
However, in most situations I prefer the two-node technique. The problem with the one-node technique is that it requires a large amount of additional code. The two-node technique code is exactly the same for a binary classification problem or a multinomial classification problem.
For example, the demo program has a method ComputeOutputs that accepts training data input values and computes and stores the output node values. Method ComputeOutputs resembles:
public double[] ComputeOutputs(double[] xValues)
{
// Use xValues to compute hidden node values.
// Use hidden node values to compute
// preliminary output node values.
// Apply softmax activation to get final
// output node values.
}
This code works for either binary or multinomial classification if you use the two-node technique for binary problems. But if you use the one-node technique you must add branching logic along the lines of:
public double[] ComputeOutputs(double[] xValues)
{
// Use xValues to compute hidden node values.
// Use hidden node values to compute
// preliminary output node values.
// if numOutput == 1
// Apply log-sigmoid activation
// else if numInput >= 2
// Apply softmax activation.
}
You'd have to add branching logic like this to several of the neural network methods. In particular, the methods that compute final accuracy, training error, and output predictions would have to be modified.
The Demo Program
To create the demo program, I launched Visual Studio, selected the C# console application program template, and named the project NeuralBinary. The demo has no significant Microsoft .NET Framework version dependencies, so any relatively recent version of Visual Studio will work. After the template code loaded, in the Solution Explorer window I renamed file Program.cs to NeuralBinaryProgram.cs and allowed Visual Studio to automatically rename class Program.
The overall structure of the demo program, with a few minor edits to save space, is presented in Listing 1. I removed unneeded using statements that were generated by the Visual Studio console application template, leaving just the one reference to the top-level System namespace.
Listing 1: Demo Program Structure
using System;
namespace NeuralBinary
{
class NeuralBinaryProgram
{
static void Main(string[] args)
{
Console.WriteLine("Begin binary demo");
Console.WriteLine("Raw data looks like:\n");
Console.WriteLine("[ 0] 5.1, 3.5, 1.4, 0.2, Iris-setosa");
Console.WriteLine("[ 1] 4.9, 3.0, 1.4, 0.2, Iris-setosa");
Console.WriteLine(" . . .");
double[][] trainData = new double[80][];
trainData[0] = new double[] { 4.7, 3.2, 1.3, 0.2,
1, 0 };
...
trainData[79] = new double[] { 5.7, 2.8, 4.1, 1.3,
0, 1 };
double[][] testData = new double[20][];
testData[0] = new double[] { 5.1, 3.5, 1.4, 0.2,
1, 0 };
...
testData[19] = new double[] { 5.4, 3.0, 4.5, 1.5,
0, 1 };
Console.WriteLine("Training data is: ");
ShowMatrix(trainData, 4, 1, true);
Console.WriteLine("Test data is: ");
ShowMatrix(testData, 4, 1, true);
int numInput = 4;
int numHidden = 5;
int numOutput = 2;
Console.WriteLine("Creating a 4-5-2 network");
Console.WriteLine("Using tanh activation");
Console.WriteLine("Using softmax activation");
NeuralNetwork nn =
new NeuralNetwork(numInput, numHidden, numOutput);
int maxEpochs = 100;
double learnRate = 0.05;
double momentum = 0.01;
Console.WriteLine("maxEpochs = " + maxEpochs);
Console.WriteLine("learnRate = " + learnRate);
Console.WriteLine("momentum = " + momentum);
Console.WriteLine("Starting training");
double[] weights =
nn.Train(trainData, maxEpochs, learnRate, momentum);
Console.WriteLine("Finished training");
Console.WriteLine("Final model weights:");
ShowVector(weights, 4, 8, true);
double trainAcc = nn.Accuracy(trainData);
Console.WriteLine("Training accuracy = " +
trainAcc.ToString("F4"));
double testAcc = nn.Accuracy(testData);
Console.WriteLine("Test accuracy = " +
testAcc.ToString("F4"));
double[] unknown =
new double[] { 5.3, 3.0, 2.0, 1.0 };
Console.WriteLine("Predicting species when = ");
ShowVector(unknown, 1, unknown.Length, true);
string pred = nn.Predict(unknown);
Console.WriteLine("Predicted species = " + pred);
Console.WriteLine("End demo");
Console.ReadLine();
} // Main
public static void ShowMatrix(double[][] matrix,
int numRows, int decimals, bool indices) { . . }
public static void ShowVector(double[] vector,
int decimals, int lineLen, bool newLine) { . . }
} // Program
public class NeuralNetwork { . . }
} // ns
All the control logic is in the Main method and all the classification logic is in a program-defined NeuralNetwork class. Helper methods ShowData and ShowVector are used to display training and test data, and neural network weights.
The demo program sets up hardwired encoded training and test data:
double[][] trainData = new double[80][];
trainData[0] = new double[] { 4.7, 3.2, 1.3, 0.2, 1, 0 };
...
In non-demo scenarios, you'd probably load training and test data from a text file using a helper method named something like LoadData. The demo encodes setosa as (1, 0) and versicolor as (0, 1). When writing neural network code it's up to you to decide on an encoding scheme and remain consistent.
The eight key statements that create the binary classifier are:
int numInput = 4;
int numHidden = 5;
int numOutput = 2;
NeuralNetwork nn = new NeuralNetwork(numInput, numHidden, numOutput);
int maxEpochs = 100;
double learnRate = 0.05;
double momentum = 0.01;
double[] weights = nn.Train(trainData, maxEpochs, learnRate, momentum);
When you see neural network code where the number of output nodes is set to 2, you can be fairly sure that the system is using two-node binary classification because multinomial classification would have three or more output nodes and one-node binary classification would have one output node.
Making Predictions
The demo program predicts the species of an Iris flower that has more or less ambiguous values for sepal and petal length and width:
double[] unknown = new double[] { 5.3, 3.0, 2.0, 1.0 };
string pred = nn.Predict(unknown);
Console.WriteLine("Predicted species = " + pred);
Method Predict is defined as:
public string Predict(double[] xValues)
{
double[] computedY = this.ComputeOutputs(xValues);
int maxIndex = MaxIndex(computedY);
if (maxIndex == 0)
return "setosa";
else
return "versicolor";
}
Notice the Predict method is extremely problem-dependent, and the logic used works only for the two-node binary classification technique. It would be possible to pass encoding information to the NeuralNetwork class and use it to make a generalized Predict method.
Wrapping Up
Binary classification is arguably the most fundamental problem in machine learning. There are several alternatives to using a neural network. Logistic regression is perhaps the most common technique used for binary classification. Naive Bayes classification and decision tree classification are two other alternatives. Neural networks are more powerful than these alternatives, in both the mathematical sense and ordinary language sense, but neural networks are more complex than the alternatives.
Let me reiterate that although I prefer the two-node technique for neural network binary classification, most of my colleagues prefer the one-node technique. Their main argument is that a one-node binary classifier should be easier to train than the equivalent two-node classifier. However, I have not seen any research results that verify this notion. In fact, my experience has shown that in most cases using the two-node technique leads to either exactly the same model as the one-node technique or sometimes even a better model than the one-node technique.