In-Depth
Supercomputing with the .NET Task Parallel Library
Huge volumes of data need near-supercomputer power to process and analyze it all. You can get there with the .NET Task Parallel Library.
- By William L. Bain
- 04/20/2017
As Web and mobile applications face the challenge of quickly analyzing huge volumes of live data, developers are turning to data-parallel computing techniques to tackle these daunting computations. The Microsoft .NET Task Parallel Library (TPL) provides powerful operators for parallel computing on a multi-core server, but where should developers turn to handle data sets that outstrip the resources of a single server?
In this article, I'll show how a distributed, in-memory data grid with an integrated compute engine can enable applications to run familiar TPL-based, data-parallel applications on a cluster of servers and achieve near-supercomputer-level performance.
Big Memory, Big Compute
Even though today’s desktop computers and servers can hold gigabytes of data in memory and crunch that data with tens of cores, it’s often not enough for real-world applications that handle massive amounts of live data. Consider a large ecommerce site or mobile app that handles 1 million simultaneous users. If each user requires 100KB of live state information, that’s 100GB of data that must be held in memory and kept up-to-date as events flow in from users. Moreover, you might want to analyze that data in real time to look for patterns and trends that need a quick response. For example, an ecommerce site might want to see how well a special offer is doing to decide whether to extend it or kill it. Trying to query and then sift through all that data from a single server can quickly become impractical.
The answer, of course, is to scale out the computation across a cluster of servers, which together have enough DRAM to hold the application’s state and enough cores to process it quickly. Traditional parallel supercomputers often package up server blades within a single box with a fat power cord and a big price tag. For most purposes, a cluster of commodity servers or cloud instances works just as well and can be much cheaper. By combining the memory and processor cores from off-the-shelf servers, you can create an impressive amount of computing power to tackle big applications. The challenge, of course, is to keep the programming model simple.
The Power of the TPL
Using a cluster of servers begs the question: How do you map your application data and application code across the cluster without starting from scratch? You definitely want to avoid the complexity of rewriting the application to distribute the work across a cluster. The answer is to leverage familiar concepts from the .NET TPL and apply them to data-parallel computing on a cluster.
Let’s take a look at how the TPL Parallel.ForEach operator enables you to harness multiple cores in parallel to analyze items within a collection. As a simple example, consider a customer’s shopping cart object defined in C#, as shown in Listing 1.
Listing 1: Customer Shopping Cart
class ShoppingCartItem
{
public string Name { get; set; }
public decimal Price { get; set; }
public int Quantity { get; set; }
}
class ShoppingCart
{
public string CustomerId { get; set; }
public IList<ShoppingCartItem> Items { get; } = new List<ShoppingCartItem>();
public decimal TotalValue
{
get { return Items.Sum((item) => item.Quantity * item.Price); }
}
public decimal ItemCount
{
get { return Items.Sum((item) => item.Quantity); }
}
}
var myCart = new ShoppingCart() { CustomerId = "cust17023" };
myCart.Items.Add(new ShoppingCartItem()
{
Name = "Acme Widget",
Price = 199.99m,
Quantity = 2
});
myCart.Items.Add(new ShoppingCartItem()
{
Name = "Acme Snow Globe",
Price = 2.99m,
Quantity = 400
});
Let’s assume that you have a collection of shopping carts that you want to analyze to determine the percentage of carts that contain an Acme Snow Globe, which is on sale for half-price. This will help you understand whether the sale is getting a response from shoppers. You can scan all shopping carts in parallel using Parallel.ForEach, as shown in Listing 2.
Listing 2: Scanning the Shopping Cart Using Parallel.ForEach
var carts = new List<ShoppingCart>(); // Collection of carts
// <snip> collection is filled with carts...
private class Result
{
public int numMatches;
public int numCarts;
}
var productName = "Acme Snow Globe"; // Product to find in the carts
var finalResult = new Result(); // Result of the computation
Parallel.ForEach<ShoppingCart, Result>(
carts, // Source collection
() => new Result(), // Thread-local result initialization
(cart, loopState, result) => // Body of analysis logic
{
// See if the selected product is in the cart:
if (cart.Items.Any(item => item.Name.Equals(productName)))
result.numMatches++;
result.numCarts++;
return result;
},
(threadLocalResult) => // Merge logic
{
Interlocked.Add(ref finalResult.numMatches, threadLocalResult.numMatches);
Interlocked.Add(ref finalResult.numCarts, threadLocalResult.numCarts);
});
float resultPct = (float)finalResult.numMatches / finalResult.numCarts * 100;
Console.WriteLine($"{resultPct} percent of carts contain {productName}");
The Parallel.ForEach operator uses all available cores to speed up the analysis of the shopping carts. For each thread that it spawns to analyze the carts (generally, one thread per core), it first creates a thread-local result of type Result and initializes it with the result-initialization logic. It partitions the shopping carts across the threads and then runs the analysis logic for each cart assigned to the thread. As results are generated, they’re merged into the thread-local result within the analysis logic. Finally, Parallel.ForEach merges the thread-local results into the global result called finalResult using the merge logic.
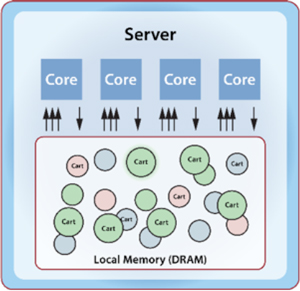
Figure 1 depicts the execution of Parallel.ForEach across all processor cores, with each core processing a partition of the shopping cart objects and returning a merged result.
 [Click on image for larger view.]
Figure 1. How Parallel.ForEach Executes Across All Processor Cores
[Click on image for larger view.]
Figure 1. How Parallel.ForEach Executes Across All Processor Cores
By running the analysis method in parallel on all shopping carts using multiple processor cores, Parallel.ForEach performs a data-parallel computation that accelerates performance. Using N cores, it can approach N-fold speedup over the time it would take to analyze each shopping cart sequentially. However, what if the collection of shopping carts is too big to fit within a single server or if the cores reach 100 percent CPU utilization and the analysis takes too long to complete?
Using an In-Memory Data Grid to Scale
Once the workload exceeds the capacity of a single server, the next step is to distribute it across a cluster of servers. This lets you take advantage of the combined memory and CPU power of many servers. It also lets you add servers on demand as the size of the workload grows. By doing this, you can scale the processing throughput as needed to keep the analysis time fast. The challenge is to structure the code with minimal changes so that a deep dive into the techniques of parallel supercomputing can be avoided. To do so, you can make use of a distributed software technology called an in-memory data grid (IMDG).
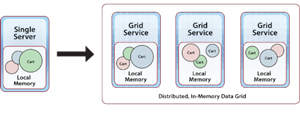
IMDGs, also called "distributed caches," have evolved for more than a decade to address the need for scalable, in-memory storage. An IMDG is a distributed orchestration layer that runs on a cluster of servers and stores serialized objects in the combined memory (DRAM) of the servers. It automatically distributes the objects evenly across all servers and provides APIs that make them uniformly accessible by client applications. Because objects are stored out-of-process, they’re identified by string or numerical keys. Figure 2 depicts how an IMDG can distribute a collection of shopping cart objects across a cluster of grid servers.
 [Click on image for larger view.]
Figure 2. IMDGs Distribute Shopping Cart Object Collections Across Grid Server Cluster
[Click on image for larger view.]
Figure 2. IMDGs Distribute Shopping Cart Object Collections Across Grid Server Cluster
IMDGs typically provide APIs for storing, reading, updating and deleting objects in the grid. Objects are organized by type into name spaces (analogous to in-memory collections). For example, a shopping cart can be added to the carts name space in a grid using the customer’s identifier as a key:
var carts = CacheFactory.GetCache("carts");
carts.Add(myCart.CustomerId, myCart); // CustomerId serves as key
An IMDG provides exactly the orchestration software needed to distribute a large collection of objects across a cluster of servers for analysis. The IMDG takes care of all the details of shipping objects to remote servers, distributing them evenly across the cluster, and letting the application access them individually using keys. The next step is to distribute the actual analysis workload. An IMDG with an integrated compute engine can do just that.
Distributing Parallel.ForEach Across a Cluster
If suitably modified for distributed execution, the TPL Parallel.ForEach operator can provide an excellent basis for structuring a data-parallel computation on an IMDG. Other than for a few details, the only significant change required is to remap the target of the computation from an in-memory collection to a distributed name space of objects hosted by the IMDG. By doing this, virtually the same computation now can run across a very large set of objects and deliver throughput that scales as servers are added to the grid.
Using a new distributed ForEach operator, the Parallel.ForEach computation can be restructured for distributed execution on the carts name space within an IMDG, as shown in Listing 3.
Listing 3: Parallel.ForEach Now Computes on Carts Name Space
string productName = "Acme Snow Globe"; // Product to find in the carts
Result finalResult; // Result of the computation
finalResult = carts.QueryObjects<ShoppingCart>().ForEach(
productName, // Parameter
() => new Result(), // Initialization of thread-local result
(cart, pName, result) => // Body of analysis logic
{
// See if the selected product is in the cart:
if (cart.Items.Any(item => item.Name.Equals(pName)))
result.numMatches++;
result.numCarts++;
return result;
},
(result1, result2) => // Merge logic
{
result1.numMatches += result2.numMatches;
result1.numCarts += result2.numCarts;
return result1;
});
Note that the ForEach operator actually runs as an extension method on a distributed query result generated by QueryObjects. This lets the application use a LINQ query expression to refine the set of objects supplied to ForEach for analysis.
To execute the distributed ForEach, the IMDG’s compute engine ships the initialization, analysis and merge logic, along with the parameter object, to all grid servers. It then executes the data-parallel operation across all cores in each server just as Parallel.ForEach would do on a single server. This leaves a merged result on each grid server, which distributed ForEach combines using a final, data-parallel merge operation to yield a single, globally merged result that’s returned from the invocation to the variable finalResult.
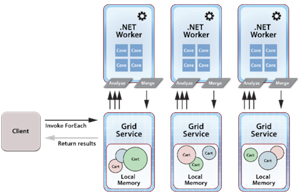
Note that in the execution of distributed ForEach shown in Figure 3, the IMDG’s compute engine spawns a .NET worker process on each grid server to run the computation.
 [Click on image for larger view.]
Figure 3. The IMDG Compute Engine Spawns .NET Worker Process on Each Grid Server
[Click on image for larger view.]
Figure 3. The IMDG Compute Engine Spawns .NET Worker Process on Each Grid Server
Because distributed ForEach must run across many servers, there are some small but interesting differences between this operator and Parallel.ForEach. The TPL Parallel.ForEach pattern for aggregation uses "localFinally" (merge) logic with a single parameter to synchronize combining thread-local results into a single, global result for the caller.
Because there’s no single, global result value that can be accessed in an IMDG, distributed ForEach defines its merge logic with two parameters that returns a single, merged result. Behind the scenes, the IMDG’s compute engine takes care of calling the merge logic as needed, combining results across threads and servers in parallel using a built-in binary merge tree to efficiently produce a single, globally merged result for return to the caller.
Unlike Parallel.ForEach, distributed ForEach cannot rely on lambda capture to supply parameters to the analysis logic. This would be problematic in a distributed environment because the captured values would have to be serialized and shipped to the IMDG’s servers. Instead, distributed ForEach defines an explicit, serializable parameter which is supplied to the analysis logic.
Scalability on Demand
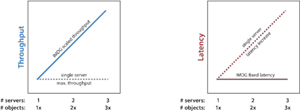
Distributed ForEach lets an application harness the power of an IMDG to scale performance on demand to handle large data sets. Figure 4 depicts the potential performance gains when using a server cluster instead of just a single server.
 [Click on image for larger view.]
Figure 4. Single Server vs. Server Cluster Latency and Throughput Performance
[Click on image for larger view.]
Figure 4. Single Server vs. Server Cluster Latency and Throughput Performance
Running on a single server, Parallel.ForEach hits its maximum performance when all CPUs reach 100 percent utilization. At this point, the number of objects processed per second (throughput) remains fixed, and the time required to complete the computation (latency) starts to climb as the workload grows in size and objects wait to be processed on a single server, as shown by the dotted lines in the graphs. If the server runs out of physical memory and starts paging, the latency can become substantially higher. By adding grid servers in proportion to the size of the workload, an IMDG can linearly increase throughput and thereby keep latency low and fixed (as indicated by the solid lines).
To achieve scalable performance, the IMDG partitions the objects evenly across a cluster of servers, and its compute engine runs the computation in parallel. With the distributed ForEach operator, the structure of the computation remains essentially the same, and the application transparently harnesses the cluster’s scalable computing power. The IMDG also mitigates the possibility of a network bottleneck by only moving parameters and merged results -- and not a huge data set -- across the network during a computation.
So Fast, and So Clean
After decades of computing on a single CPU, the Microsoft TPL has paved the way for developers to easily implement data-parallel computations that take full advantage of the power of today’s multi-core servers. The obvious next step is to harness the power of a cluster of servers (physical or virtual) to tackle the challenges of Big Data.
By marrying the clean, data-parallel semantics of the TPL Parallel.ForEach operator with the scalable in-memory storage and computing power offered by an IMDG, the distributed ForEach operator gives developers an easy-to-use and cost-effective bridge to near-supercomputer performance.
Note: A full Visual Studio 2015 solution for the code samples in this article can be downloaded from GitHub; the solution makes use of APIs in ScaleOut ComputeServer, which can be downloaded here.