News
Azure Data Explorer Heads Microsoft Cloud Analytics Updates
Microsoft has beefed up several data analytics offerings in its Azure cloud platform, headed by the general availability of Azure Data Explorer.
Azure Data Explorer fosters real-time analytics of streaming data. The company says it's capable of quickly executing queries on huge volumes of data emanating from applications, Web sites, devices connected to the Internet of Things (IoT) ecosystem and so on.
Corporate exec Julia White said it was "useful to query streaming data to identify trends, detect anomalies and diagnose problems."
Microsoft last month announced the streaming analytics tool had reached general availability, along with Azure Data Lake Storage. Also announced was a preview of new Mapping Data Flow capabilities in Azure Data Factory.
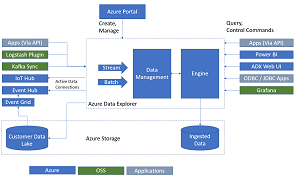 [Click on image for larger view.] Azure Data Explorer (source: Microsoft).
[Click on image for larger view.] Azure Data Explorer (source: Microsoft).
Azure Data Lake Storage, built on Azure Blob Storage, was described by White as "the first cloud storage that combines the best of hierarchical files system and blob storage." Blob storage is used to house unstructured object data, including text or binary data.
"Azure Data Lake Storage (ADLS) combines the scalability, cost effectiveness, security model, and rich capabilities of Azure Blob Storage with a high-performance file system that is built for analytics and is compatible with the Hadoop Distributed File System," said Jurgen Willis, director of Product Management, Azure Engineering, in his own post. "Customers no longer have to tradeoff between cost effectiveness and performance when choosing a cloud data lake."
Microsoft also announced Mapping Data Flow, a visual, no-code way to work with data transformations in its Azure Data Factory, a hybrid data integration service used to orchestrate and automate data movement, along with the data transformation functionality.
"With Mapping Data Flow in ADF, customers can visually design, build and manage data transformation processes without learning Spark or having a deep understanding of their distributed infrastructure," Willis said. "Mapping Data Flow combines a rich expression language with an interactive debugger to easily execute, trigger, and monitor ETL jobs and data integration processes."
White said the new capabilities complement the Azure Data Factory’s code-first experience, helping data engineers of all types to collaborate and build powerful hybrid data transformation pipelines. These pipelines are used to work with "activities" in Azure Data Factory that transform and process raw data so it can be used for predictions and business insights. These Big Data activities are centered around several Apache open source analytics projects, such as Hive, Pig, MapReduce, HDInsight Spark and so on.
About the Author
David Ramel is an editor and writer at Converge 360.