The Data Science Lab
Data Prep for Machine Learning: Normalization
Dr. James McCaffrey of Microsoft Research uses a full code sample and screenshots to show how to programmatically normalize numeric data for use in a machine learning system such as a deep neural network classifier or clustering algorithm.
This article explains how to programmatically normalize numeric data for use in a machine learning (ML) system such as a deep neural network classifier or clustering algorithm. Suppose you are trying to predict election voting behavior from a file of people data. Your data would likely include things like each person's age in years and annual income in dollars. To use the data to train a neural network, you'd want to scale the data so that all numeric values are roughly in the same range, so that the large income values don't overwhelm the smaller age values.
In situations where the source data file is small, about 500 lines or less, you can usually normalize numeric data manually using a text editor or spreadsheet. But in almost all realistic scenarios with large datasets you must normalize your data programmatically.
Preparing data for use in a machine learning (ML) system is time consuming, tedious, and error prone. A reasonable rule of thumb is that data preparation requires at least 80 percent of the total time needed to create an ML system. There are three main phases of data preparation: cleaning; normalizing and encoding; and splitting. Each of the three phases has several steps.
A good way to understand data normalization and see where this article is headed is to take a look at the screenshot of a demo program in Figure 1. The demo uses a small text file named people_clean.txt where each line represents one person. There are five fields/columns: sex, age, region, income, and political leaning. The "clean" in the file name indicates that the data has been standardized by removing missing values, and editing bad data so that all lines have the same format, but numeric values have not yet been normalized.
The ultimate goal of a hypothetical ML system is to use the demo data to create a neural network model that predicts political leaning from sex, age, region, and income. The demo analyzes the age and income predictor fields, then normalizes those two fields using a technique called min-max normalization. The results are saved as a new file named people_normalized.
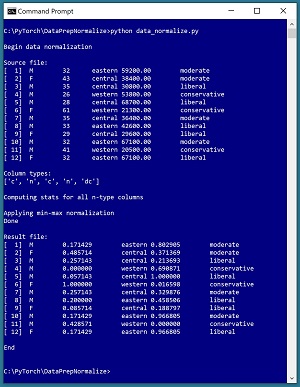 [Click on image for larger view.] Figure 1: Programmatically Normalizing Numeric Data
[Click on image for larger view.] Figure 1: Programmatically Normalizing Numeric Data
The demo is a Python language program but programmatic data normalization can be implemented using any language. The first five lines of the demo source data are:
M 32 eastern 59200.00 moderate
F 43 central 38400.00 moderate
M 35 central 30800.00 liberal
M 26 western 53800.00 conservative
M 28 central 68700.00 liberal
. . .
The demo begins by displaying the source data file. Next the demo scans through the age column and income column and computes four statistics that are needed for normalization: the smallest and largest value in each column, and the mean and standard deviation of the values in each column. These statistics are stored into an array of Dictionary objects, with one Dictionary for each numeric column.
There are several different types of data normalization. The three most common types are min-max normalization, z-score normalization, and constant factor normalization. The demo program uses min-max normalization but the program can be easily modified to use z-score or constant factor normalization. After applying min-max normalization, all age and income values are between 0.0 and 1.0.
This article assumes you have intermediate or better skill with a C-family programming language. The demo program is coded using Python but you shouldn't have too much trouble refactoring the demo code to another language if you wish. The complete source code for the demo program is presented in this article. The source code is also available in the accompanying file download.
The Data Preparation Pipeline
Although data preparation is different for every problem scenario, in general the data preparation pipeline for most ML systems usually follows something similar to the steps shown in Figure 2.
 [Click on image for larger view.] Figure 2: Data Preparation Pipeline Typical Tasks
[Click on image for larger view.] Figure 2: Data Preparation Pipeline Typical Tasks
Data preparation for ML is deceptive because the process is conceptually easy. However, there are many steps, and each step is much trickier than you might expect if you're new to ML. This article explains the seventh step in Figure 2. Other Data Science Lab articles explain the other steps. The articles can be found here.
The tasks in Figure 2 are usually not followed in a strictly sequential order. You often have to backtrack and jump around to different tasks. But it's a good idea to follow the steps shown in order as much as possible. For example, it's better to normalize data before encoding because encoding generates many additional numeric columns which makes it a bit more complicated to normalize the original numeric data.
Understanding Normalization Techniques
The min-max, z-score, and constant factor normalization techniques are best explained by examples. Suppose you have just three numeric values: 28, 46, 34. Expressed as a math equation, min-max normalization is x' = (x - min) / (max - min), where x is a raw value, x' is the normalized value, min is the smallest value in the column, and max is the largest value. For the three example values, min = 28 and max = 46. Therefore, the min-max normalized values are:
28: (28 - 28) / (46 - 28) = 0 / 18 = 0.00
46: (46 - 28) / (46 - 28) = 18 / 18 = 1.00
34: (34 - 28) / (46 - 28) = 6 / 18 = 0.33
The min-max technique results in values between 0.0 and 1.0 where the smallest value is normalized to 0.0 and the largest value is normalized to 1.0.
Expressed as a math equation, z-score normalization is x' = (x - u) / sd, where x is a raw value, x' is the normalized value, u is the mean of the values, and sd is the standard deviation of the values. For the three example values, u = (28 + 46 + 34) / 3 = 108 / 3 = 36.0. The standard deviation of a set of values is the square root of the sum of the squared difference of each value and the mean, divided by the number of values, and so is:
sd = sqrt( [(28 - 36.0)^2 + (46 - 36.0)^2 + (34 - 36.0)^2] / 3 )
= sqrt( [(-8.0)^2 + (10.0)^2 + (-2.0)^2] / 3 )
= sqrt( [64.0 + 100.0 + 4.0] / 3 )
= sqrt( 168.0 / 3 )
= sqrt(56.0)
= 7.48
Therefore, the z-score normalized values are:
28: (28 - 36.0) / 7.48 = -1.07
46: (46 - 36.0) / 7.48 = +1.34
34: (34 - 36.0) / 7.48 = -0.27
A z-score normalized value that is positive corresponds to an x value that is greater than the mean value, and a z-score that is negative corresponds to an x value that is less than the mean.
The simplest normalization technique is constant factor normalization. Expressed as a math equation constant factor normalization is x' = x / k, where x is a raw value, x' is the normalized value, and k is a numeric constant. If k = 100, the constant factor normalized values are:
28: 28 / 100 = 0.28
46: 46 / 100 = 0.46
34: 34 / 100 = 0.34
So, which normalization technique should you use? There is very little research on the effects of different types of normalization, but what little research there is suggests that all three techniques work about equally well. Other factors, such as the training optimization algorithm and learning rate, usually have greater influence than type of normalization technique used.
In most situations I prefer using constant factor normalization. It's easy, normalized values maintain sign, and the normalized values are easy to interpret. There are some rather vague theoretical advantages for min-max and z-score normalization, but there are no solid research results to support these claims.
The Demo Program
The structure of the demo program, with a few minor edits to save space, is shown in Listing 1. I indent my Python programs using two spaces, rather than the more common four spaces or a tab character, as a matter of personal preference. The program has five worker functions plus a main() function to control program flow. The purpose of worker functions line_count(), show_file(), make_col_stats(), make_stats_arr(), and normalize_mm_file() should be clear from their names.
Listing 1: Data Normalization Demo Program
# data_normalize.py
# Python 3.7.6 NumPy 1.18.1
import numpy as np
def show_file(fn, start, end, indices=False,
strip_nl=False): . . .
def line_count(fn): . . .
def make_col_stats(data, col, delim): . . .
def make_stats_arr(fn, col_types,
delim): . . .
def normalize_mm_file(src, dest, col_types,
stats_arr, delim): . . .
def main():
print("\nBegin data normalization ")
src = ".\\people_clean.txt"
dest = ".\\people_normalized.txt"
print("\nSource file: ")
show_file(src, 1, 9999, indices=True,
strip_nl=True)
print("\nColumn types: ")
col_types = ["c", "n", "c", "n", "dc"]
print(col_types)
print("\nComputing stats for n-type columns")
stats_arr = make_stats_arr(src,
col_types, "\t")
print("\nApplying min-max normalization")
normalize_mm_file(src, dest,
col_types, stats_arr, "\t")
print("Done")
print("\nResult file: ")
show_file(dest, 1, 9999, indices=True,
strip_nl=True)
print("\nEnd \n")
if __name__ == "__main__":
main()
Program execution begins with:
def main():
print("\nBegin data normalization ")
src = ".\\people_clean.txt"
dest = ".\\people_normalized.txt"
print("\nSource file: ")
show_file(src, 1, 9999, indices=True,
strip_nl=True)
. . .
The first step when working with any machine learning data file is to do a preliminary investigation. The source data is named people_clean.txt and has only 12 lines to keep the main ideas of data normalization as clear as possible. The number of lines in the file could have been determined by a call to the line_count() function. The entire data file is examined by a call to show_file() with arguments start=1 and end=9999. In most cases with large data files, you'll examine just specified lines of your data file rather than the entire file.
The indices=True argument instructs show_file() to display 1-based line numbers. With some data preparation tasks it's more natural to use 1-based indexing, but with other tasks it's more natural to use 0-based indexing. Either approach is OK but you've got to be careful of off-by-one errors. The strip_nl=True argument instructs function show_file() to remove trailing newlines from the data lines before printing them to the console shell so that there aren't blank lines between data lines in the display.
The demo continues with:
print("\nColumn types: ")
col_types = ["c", "n", "c", "n", "dc"]
print(col_types)
print("\nComputing stats for all n columns")
stats_arr = make_stats_arr(src,
col_types, "\t")
. . .
The demo identifies the kind of each column because different kinds of columns must be normalized and encoded in different ways. There is no standard way to identify columns so you can use whatever scheme is suited to your problem scenario. The demo uses "c" for the two categorical predictor data columns sex and region, "n" for the two numeric predictor columns age and income, and "dc" for the dependent categorical variable column political leaning.
The demo uses program-defined function make_stats_arr() to compute a stats_arr object. The result stats_arr object is a NumPy array of references to Dictionary objects, one object per data column. If a column is not numeric, the corresponding array cell is set to None (roughly equivalent to null in other languages). The numeric columns have a corresponding cell that is a reference to a Dictionary where the keys are "min", "max", "mean", and "sd", and the values are the smallest value, largest value, average value, and standard deviation of the column. For example, stats_arr[0] is None because column [0] is the sex variable, which is categorical. And stats_arr[1]["min"] is the smallest value in column [1], the age column, which is 26.
The demo program concludes with:
. . .
print("\nApplying min-max normalization")
normalize_mm_file(src, dest, col_types,
stats_arr, "\t")
print("Done")
print("\nResult file: ")
show_file(dest, 1, 9999, indices=True,
strip_nl=True)
print("\nEnd \n")
if __name__ == "__main__":
main()
The source file is min-max normalized using a call to the normalize_mm_file() function and the results are saved to a destination file, and then displayed. As you'll see shortly, you can easily modify normalize_mm_file() so that it will use z-score or constant factor normalization.
Examining the Data
When working with data for an ML system you always need to determine how many lines there are in the data, how many columns/fields there are on each line, and what type of delimiter is used. The demo defines a function line_count() as:
def line_count(fn):
ct = 0
fin = open(fn, "r")
for line in fin:
ct += 1
fin.close()
return ct
The file is opened for reading and then traversed using a Python for-in idiom. Each line of the file, including the terminating newline character, is stored into variable named "line" but that variable isn't used. There are many alternative approaches.
The definition of function show_file() is presented in Listing 2. As is the case with all data preparation functions, there are many possible implementations.
Listing 2: Displaying Specified Lines of a File
def show_file(fn, start, end, indices=False,
strip_nl=False):
fin = open(fn, "r")
ln = 1 # advance to start line
while ln < start:
fin.readline()
ln += 1
while ln <= end: # show specified lines
line = fin.readline()
if line == "": break # EOF
if strip_nl == True:
line = line.strip()
if indices == True:
print("[%3d] " % ln, end="")
print(line)
ln += 1
fin.close()
Because the while-loop terminates with a break statement, if you specify an end parameter value that's greater than the number of lines in the source file, such as 9999 for the 12-line demo data, the display will end after the last line has been printed, which is usually what you want.
Computing Column Statistics
The demo program computes the min, max, mean, and standard deviation of numeric columns using function make_stats_arr() which calls helper function make_col_stats(). The make_col_stats() creates a Dictionary object for a single specified column of a data file. The definition of helper function make_col_stats() is presented in Listing 3.
Listing 3: Computing Statistics for a Numeric Column
def make_col_stats(data, col, delim):
# make a statistics dictionary for one numeric col
d = dict()
sum = 0.0
smallest = np.finfo(np.float32).max
largest = np.finfo(np.float32).min
n = len(data)
for i in range(n):
tokens = data[i].split(delim)
x = np.float32(tokens[col])
if x < smallest: smallest = x
if x > largest: largest = x
sum += np.float32(tokens[col])
mean = sum / n
d["mean"] = mean
d["min"] = smallest
d["max"] = largest
ssd = 0.0
for i in range(n):
tokens = data[i].split(delim)
x = np.float32(tokens[col])
ssd += (x - mean) * (x - mean)
sd = np.sqrt(ssd / n)
d["sd"] = sd
return d
The input parameter named data is an array of strings, where each string is a line of data. Each line is split into tokens, for example, the first line of data yields tokens[0] = "M", tokens[1] = "32", tokens[2] = "eastern", tokens[3] = "59200.00", tokens[4] = "moderate". Next the specified 0-based column is converted from a string to a float32 numeric value, for example "32" is converted to 32.0. In most ML scenarios, float32 is the default floating point type but you can use the float64 type if you wish.
The current numeric value is checked to see if it is a new column min or max value, and is then accumulated into a running sum variable. After all lines have been processed, the column mean is computed. Then a second pass through the data is performed to compute the column standard deviation.
The demo computes the population standard deviation, dividing the sum of squared deviations from the mean by the number of values n, rather than the sample standard deviation which divides by n-1. Either form of standard deviation works for z-score normalization. A sample standard deviation calculation is usually performed in situations where you want to estimate the standard deviation of a population from which a sample was selected.
The make_stats_arr() function accepts a source data file, reads the file into memory as an array of strings, and then calls the make_col_stats() function on each numeric column. The code for make_stats_arr() is presented in Listing 4.
Listing 4: Computing Statistics as an Array of Dictionary Objects
def make_stats_arr(fn, col_types, delim):
# make array of stats dictionaries for "n" cols
num_cols = len(col_types) # ["c", "n", . . .]
dict_arr = np.empty(num_cols, dtype=np.object)
num_lines = line_count(fn)
data = np.empty(num_lines, dtype=np.object)
fin = open(fn, "r")
i = 0
for line in fin:
data[i] = line
i += 1
fin.close()
for j in range(num_cols):
if col_types[j] == "n":
dict_arr[j] = make_col_stats(data, j, delim)
else:
dict_arr[j] = None
return dict_arr
One of the many minor details when doing programmatic data normalization with Python is that a NumPy array of strings has to be specified as dtype=np.object rather than dtype=np.str as you would expect. The definitions of functions make_stats_arr() and make_col_stats() point out the idea that data normalization is very simple in principle, but performing normalization in practice is surprisingly tricky because of the many small details that must be attended to.
Normalizing the Source File
After an array of Dictionary objects of column statistics has been created, the demo program uses that array to normalize a source file. The definition of function normalize_mm_file() is presented in Listing 5. The function opens the source file for reading and a destination file for writing. The source file is processed one line at a time. Each line is split into tokens. Each token is examined and if the token is a numeric column, a normalized value is computed.
Listing 5: Normalizing a Data File
def normalize_mm_file(src, dest, col_types,
stats_arr, delim):
# use stats_arr to min-max normalize "n" cols
fin = open(src, "r")
fout = open(dest, "w")
for line in fin:
line = line.strip() # remove trailing newline
tokens = line.split(delim)
if len(col_types) != len(tokens):
print("FATAL: len(col_types) != len(tokens)")
input()
s = ""
for j in range(len(tokens)): # each column
if col_types[j] == "n":
x = np.float32(tokens[j])
mn = stats_arr[j]["min"]
mx = stats_arr[j]["max"]
xx = (x - mn) / (mx - mn)
s += "%0.6f" % xx
else:
s += tokens[j]
if j < len(tokens)-1: # interior column
s += "\t"
else: # last column
s += "\n"
fout.write(s)
fout.close(); fin.close()
return
The core statement for min-max normalization is xx = (x - mn) / (mx - mn). In words, the normalized value is the raw value minus the min, divided by the max minus the min. If you want to perform z-score normalization, the new code would look like xx = (x - mean) / sd. If you want to perform constant factor normalization, the new code would look like xx = x / k.
Wrapping Up
In theory, it's not necessary to normalize numeric data for training a neural network. The idea is that the network weights and biases will adapt during training to handle differently scaled predictor values. But in practice, data normalization is usually necessary to get a good prediction model. A well-known exception to this rule of thumb is Fisher's Iris data. Because there are only 150 items in the Iris dataset, and all the raw values are between 0.1 and 7.9 you can get a good model without normalization. This is one of the reasons why the Iris dataset is the "Hello World" data for neural networks.
For numeric data clustering algorithms, such as k-means variants, clustering is usually essential. These clustering algorithms are based on a distance metric. If data is not normalized, variables with large magnitudes (such as annual income) will dominate variables with smaller magnitudes (such as age). Without normalization the clustering will be effectively based on just the variable which has values with the largest magnitudes.