The Data Science Lab
Preparing IMDB Movie Review Data for NLP Experiments
Dr. James McCaffrey of Microsoft Research shows how to get the raw source IMDB data, read the movie reviews into memory, parse and tokenize the reviews, create a vocabulary dictionary and convert the reviews to a numeric form.
A common dataset for natural language processing (NLP) experiments is the IMDB movie review data. The goal of an IMDB dataset problem is to predict if a movie review has positive sentiment ("It was a great movie") or negative sentiment ("The film was a waste of time"). A major challenge when working with the IMDB dataset is preparing the data.
This article explains how to get the raw source IMDB data, read the movie reviews into memory, parse and tokenize the reviews, create a vocabulary dictionary and convert the reviews to a numeric form that's suitable for use by a system such as a deep neural network, or an LSTM network, or a Transformer Architecture network.
Most popular neural network libraries, including PyTorch, scikit and Keras, have some form of built-in IMDB dataset designed to work with the library. But there are two problems with using a built-in dataset. First, data access becomes a magic black box and important information is hidden. Second, the built-in datasets use all 25,000 training and 25,000 test movie reviews and these are difficult to work with because they're so large.
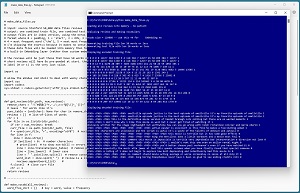 [Click on image for larger view.] Figure 1: Converting Source IMDB Review Data to Token IDs
[Click on image for larger view.] Figure 1: Converting Source IMDB Review Data to Token IDs
A good way to see where this article is headed is to take a look at the screenshot of a Python language program in Figure 1. The source IMDB movie reviews are stored as text files, one review per file. The program begins by loading all 50,000 movie reviews into memory, and then parsing each review into words/tokens. The words/tokens are used to create a vocabulary dictionary that maps each word/token to an integer ID. For example, the word "the" is mapped to ID = 4.
The vocabulary collection is then used to convert movie reviews that have 20 words or less into token IDs. Reviews that have fewer than 20 words/tokens are padded to exactly length 20 by prepending a special 0 padding ID.
Movie reviews that have positive sentiment, such as, "This is a good movie" get a label of 1 as the last value, and negative sentiment reviews get a label of 0. The result is 16 movie reviews for training and 17 reviews for testing. In a non-demo scenario you'd allow longer reviews, for example, up to 80 words in length, so that you'd get more training and test reviews.
This article assumes you have an intermediate or better familiarity with a C-family programming language, preferably Python, but doesn't assume you know anything about the IMDB dataset. The complete source code for the demo program is presented in this article, and the code is also available in the accompanying file download.
Getting the Source Data Files
The IMDB movie review data consists of 50,000 reviews -- 25,000 for training and 25,000 for testing. The training and test files are evenly divided into 12,500 positive reviews and 12,500 negative reviews. Negative reviews are those reviews associated with movies that the reviewer rated as 1 through 4 stars. Positive reviews are the ones rated 7 through 10 stars. Movie reviews that received 5 or 6 stars are considered neither positive nor negative and are not used.
The Large Movie Review Dataset is the primary storage site for the raw IMDB movie reviews data, but you can also find it at other locations using an internet search. If you click on the link on the web page, you will download an 80 MB file in tar-GNU-zip format named aclImdb_v1.tar.gz.
Unlike ordinary .zip compressed files, Windows cannot extract tar.gz files so you need to use an application. I recommend the free 7-Zip utility. After installing 7-Zip you can open Windows File Explorer and then right-click on the aclImdb_v1.tar.gz file and select the Extract Here option. This will result in a 284 MB file named aclImdb_v1.tar ("tape archive"). If you right-click on that tar file and select the Extract Here option, you will get an uncompressed root directory named aclimdb of approximately 300 MB.
The root aclimdb directory contains subdirectories named test and train, plus three files that you can ignore. The test and train directories contain subdirectories named neg and pos, plus five files and one directory named unsup (50,000 unlabeled reviews for unsupervised analysis) that you can ignore. The neg and pos directories each contain 12,500 text files where each review is a single file.
The 50,000 file names look like 102_4.txt where the first part of the file name is the [0] to [12499] review index and the second part of the file name is the numerical review rating (0 to 4 for negative reviews, and 7 to 10 for positive reviews).
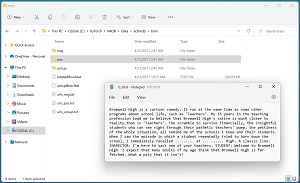 [Click on image for larger view.] Figure 2: IMDB Dataset First Positive Training Review
[Click on image for larger view.] Figure 2: IMDB Dataset First Positive Training Review
The screenshot in Figure 2 shows the directory structure of the IMDB movie review data. The contents of the first positive sentiment training review (file 0.9.txt) is displayed in Notepad.
Making IMDB Reviews Train and Test Files
The complete make_data_files.py data preparation program, with a few minor edits to save space, is presented in Listing 1. The program accepts the 50,000 movie review files as input and creates one training file and one test file.
The program has three helper functions that do all the work:
get_reviews(dir_path, max_reviews)
make_vocab(all_reviews)
generate_file(reviews_lists, outpt_file, w_or_a,
vocab_dict, max_review_len, label_char)
The get_reviews() function reads all the files in a directory, tokenizes the reviews and returns a list-of-lists such as [["a", "great", "movie"], ["i", "liked", "it", "a", "lot"], . . ["terrific", "film"]]. The make_vocab() function accepts a list of tokenized reviews and builds a dictionary collection where the keys are tokenized words such as "movie" and the values are integer IDs such as 27. The dictionary key-value pairs are also written to a text file named vocab_file.txt so they can be used later by an NLP system.
The generate_file() function accepts the results of get_reviews() and make_vocab() and produces a training or test file. The program control logic is in a main() function which begins:
def main():
print("Loading all reviews into memory - be patient ")
pos_train_reviews = get_reviews(".\\aclImdb\\train\\pos", 12500)
neg_train_reviews = get_reviews(".\\aclImdb\\train\\neg", 12500)
pos_test_reviews = get_reviews(".\\aclImdb\\test\\pos", 12500)
neg_test_reviews = get_reviews(".\\aclImdb\\test\\neg", 12500)
. . .
Next, the vocabulary dictionary is created from the training data:
vocab_dict = make_vocab([pos_train_reviews,
neg_train_reviews]) # key = word, value = word rank
v_len = len(vocab_dict)
# need this plus 4, for Embedding: 129888+4 = 129892
For the demo, there are 129,888 distinct words/tokens. This is a very large number because in addition to normal English words such as "movie" and "excellent," there are thousands of words specific to movie reviews, such as "hitchcock" (a movie director) and "dicaprio" (an actor).
The vocabulary is based on word frequencies where ID = 4 is the most common word ("the"), ID = 5 is the second most common word ("and") and so on. This allows you to filter out rare words that occur only once or twice.
The vocabulary reserves IDs 0, 1, 2 and 3 for special tokens. ID = 0 is for <PAD> padding. ID = 1 is for <ST> to indicate the start of a sequence. ID = 2 is for <OOV> for out-of-vocabulary words. ID = 3 is reserved but not used. The number of tokens in the entire vocabulary is 129,888 + 4 = 129,892. This number is needed for an embedding layer when creating an NLP prediction system.
The demo program creates a training file with movie reviews that have 20 words or less with these three statements:
max_review_len = 20 # exact fixed length
generate_file(pos_train_reviews, ".\\imdb_train_20w.txt",
"w", vocab_dict, max_review_len, "1")
generate_file(neg_train_reviews, ".\\imdb_train_20w.txt",
"a", vocab_dict, max_review_len, "0")
The first call to generate_file() uses a "w" argument which creates the destination file for writing the positive reviews. The second call uses a "a" argument to append the negative reviews. It's possible to use "a+" mode but using separate "w" and "a" modes is more clear in my opinion.
The test file is created similarly:
generate_file(pos_test_reviews, ".\\imdb_test_20w.txt",
"w", vocab_dict, max_review_len, "1")
generate_file(neg_test_reviews, ".\\imdb_test_20w.txt",
"a", vocab_dict, max_review_len, "0")
The demo inspects the training file:
f = open(".\\imdb_train_20w.txt", "r", encoding="utf8")
for line in f:
print(line, end="")
f.close()
The vocabulary dictionary accepts a word/token like "film" and returns an ID like 87. The demo creates a reverse vocabulary object named index_to_word that accepts an ID and returns the corresponding word/token, taking into account the four special tokens:
index_to_word = {}
index_to_word[0] = "<PAD>"
index_to_word[1] = "<ST>"
index_to_word[2] = "<OOV>"
for (k,v) in vocab_dict.items():
index_to_word[v+3] = k
The demo program concludes by using the modified reverse vocabulary dictionary to decode and display the training file:
f = open(".\\imdb_train_20w.txt", "r", encoding="utf8")
for line in f:
line = line.strip()
indexes = line.split(" ")
for i in range(len(indexes)-1): # last is '0' or '1'
idx = (int)(indexes[i])
w = index_to_word[idx]
print("%s " % w, end="")
print("%s " % indexes[len(indexes)-1])
f.close()
There is no standard scheme for NLP vocabulary collections, which is another problem with using built-in IMDB datasets from PyTorch and Keras. Additionally, a vocabulary collection depends entirely upon how the source data is tokenized. This means you must always tokenize NLP data and create an associated vocabulary at the same time.
Listing 1: Program to Create IMDB Movie Review Train and Test Files
# make_data_files.py
#
# input: source Stanford 50,000 data files reviews
# output: one combined train file, one combined test file
# output files are in index version, using the Keras dataset
# format where 0 = padding, 1 = 'start', 2 = OOV, 3 = unused
# 4 = most frequent word ('the'), 5 = next most frequent, etc.
import os
# allow the Windws cmd shell to deal with wacky characters
import sys
import codecs
sys.stdout = codecs.getwriter('utf8')(sys.stdout.buffer)
# ---------------------------------------------------------------
def get_reviews(dir_path, max_reviews):
remove_chars = "!\"#$%&()*+,-./:;<=>?@[\\]^_`{|}~"
# leave ' for words like it's
punc_table = {ord(char): None for char in remove_chars} # dict
reviews = [] # list-of-lists of words
ctr = 1
for file in os.listdir(dir_path):
if ctr > max_reviews: break
curr_file = os.path.join(dir_path, file)
f = open(curr_file, "r", encoding="utf8") # one line
for line in f:
line = line.strip()
if len(line) > 0: # number characters
# print(line) # to show non-ASCII == errors
line = line.translate(punc_table) # remove punc
line = line.lower() # lower case
line = " ".join(line.split()) # remove consecutive WS
word_list = line.split(" ") # list of words
reviews.append(word_list)
f.close() # close curr file
ctr += 1
return reviews
# ---------------------------------------------------------------
def make_vocab(all_reviews):
word_freq_dict = {} # key = word, value = frequency
for i in range(len(all_reviews)):
reviews = all_reviews[i]
for review in reviews:
for word in review:
if word in word_freq_dict:
word_freq_dict[word] += 1
else:
word_freq_dict[word] = 1
kv_list = [] # list of word-freq tuples so can sort
for (k,v) in word_freq_dict.items():
kv_list.append((k,v))
# list of tuples index is 0-based rank, val is (word,freq)
sorted_kv_list = \
sorted(kv_list, key=lambda x: x[1], \
reverse=True) # sort by freq
f = open(".\\vocab_file.txt", "w", encoding="utf8")
vocab_dict = {}
# key = word, value = 1-based rank
# ('the' = 1, 'a' = 2, etc.)
for i in range(len(sorted_kv_list)): # filter here . .
w = sorted_kv_list[i][0] # word is at [0]
vocab_dict[w] = i+1 # 1-based as in Keras dataset
f.write(w + " " + str(i+1) + "\n") # save word-space-index
f.close()
return vocab_dict
# ---------------------------------------------------------------
def generate_file(reviews_lists, outpt_file, w_or_a,
vocab_dict, max_review_len, label_char):
# write first time, append later. could use "a+" mode instead.
fout = open(outpt_file, w_or_a, encoding="utf8")
offset = 3 # Keras offset: 'the' = 1 (most frequent) 1+3 = 4
for i in range(len(reviews_lists)): # walk each review-list
curr_review = reviews_lists[i]
n_words = len(curr_review)
if n_words > max_review_len:
continue # next i, continue without writing anything
n_pad = max_review_len - n_words # number 0s to prepend
for j in range(n_pad):
fout.write("0 ")
for word in curr_review:
# a word in test set might not have been in train set
if word not in vocab_dict:
fout.write("2 ") # out-of-vocab index
else:
idx = vocab_dict[word] + offset
fout.write("%d " % idx)
fout.write(label_char + "\n") # '0' or '1
fout.close()
# ---------------------------------------------------------------
def main():
print("Loading all reviews into memory - be patient ")
pos_train_reviews = get_reviews(".\\aclImdb\\train\\pos", 12500)
neg_train_reviews = get_reviews(".\\aclImdb\\train\\neg", 12500)
pos_test_reviews = get_reviews(".\\aclImdb\\test\\pos", 12500)
neg_test_reviews = get_reviews(".\\aclImdb\\test\\neg", 12500)
# mp = max(len(l) for l in pos_train_reviews) # 2469
# mn = max(len(l) for l in neg_train_reviews) # 1520
# mm = max(mp, mn) # longest review is 2469
# print(mp, mn)
# ---------------------------------------------------------------
print("Analyzing reviews and making vocabulary ")
vocab_dict = make_vocab([pos_train_reviews,
neg_train_reviews]) # key = word, value = word rank
v_len = len(vocab_dict)
# need this value, plus 4, for Embedding: 129888+4 = 129892
print("Vocab size = %d -- use this +4 for \
Embedding nw " % v_len)
max_review_len = 20 # exact fixed length
# if max_review_len == None or max_review_len > mm:
# max_review_len = mm
print("Generating training file len %d words or less " \
% max_review_len)
generate_file(pos_train_reviews, ".\\imdb_train_20w.txt",
"w", vocab_dict, max_review_len, "1")
generate_file(neg_train_reviews, ".\\imdb_train_20w.txt",
"a", vocab_dict, max_review_len, "0")
print("Generating test file with len %d words or less " \
% max_review_len)
generate_file(pos_test_reviews, ".\\imdb_test_20w.txt",
"w", vocab_dict, max_review_len, "1")
generate_file(neg_test_reviews, ".\\imdb_test_20w.txt",
"a", vocab_dict, max_review_len, "0")
# inspect a generated file
# vocab_dict was used indirectly (offset)
print("Displaying encoded training file: \n")
f = open(".\\imdb_train_20w.txt", "r", encoding="utf8")
for line in f:
print(line, end="")
f.close()
# ---------------------------------------------------------------
print("Displaying decoded training file: ")
index_to_word = {}
index_to_word[0] = "<PAD>"
index_to_word[1] = "<ST>"
index_to_word[2] = "<OOV>"
for (k,v) in vocab_dict.items():
index_to_word[v+3] = k
f = open(".\\imdb_train_20w.txt", "r", encoding="utf8")
for line in f:
line = line.strip()
indexes = line.split(" ")
for i in range(len(indexes)-1): # last is '0' or '1'
idx = (int)(indexes[i])
w = index_to_word[idx]
print("%s " % w, end="")
print("%s " % indexes[len(indexes)-1])
f.close()
if __name__ == "__main__":
main()
Tokenizing the Movie Reviews
The primary customization points for tokenizing IMDB movie reviews, or any other NLP problem source text, is in the get_reviews() function. In high-level pseudo-code:
loop each file in directory
loop each line in file
remove trailing newline
remove specified punctuation chars
convert to all lower case
remove consecutive white space chars
split line into tokens
end each line
end each file
The demo program removes all punctuation except for the single-quote character. This allows contraction words like don't and they're to remain in the reviews. You might want to retain period characters in order to preserve sentence structure.
Converting movie reviews to all lower case is a simple approach but has the problem of not distinguishing between words like "March" (the month) and "march" (as in walking). In some NLP scenarios you might want to convert to lower case but retain capitalization of just certain words that have special meaning for the specific problem being solved.
The demo program integrates tokenization code with code that reads and saves IMDB movie reviews. Therefore, if you are working on a problem with different source text, you'll have to completely refactor the get_reviews() function. An alternative approach is to modularize design by creating a dedicated tokenization object. This is a lot of work.
Wrapping Up
Working with natural language processing problems is extremely difficult. Even relatively simple problems can take days or weeks of effort. I have worked on several NLP projects and in most cases, data preparation took over 80% of the total time and effort required. And it's easy to make mistakes. If you check out Figure 1 you'll notice that the positive training reviews have a duplicate (files 1557_10.txt and 1558_10.txt are identical).
Once the data for an NLP problem has been prepared, it can be used to train a prediction system. Examples include text classification (such as movie review sentiment), question-answer systems and artificial document generation. Deep neural prediction systems based on LSTM (long, short-term memory) networks and TA (transformer architecture) networks have produced significant accuracy improvements over classical statistics NLP techniques.