The Data Science Lab
Runs Testing Using C# Simulation
Dr. James McCaffrey of Microsoft Research uses a full code program for a step-by-step explanation of this machine learning technique that indicates if patterns are random.
Suppose you observe a sequence of people entering a store and you record the color of shirt worn by each person. You see this sequence of 24 shirts:
0, 0, 3, 3, 2, 1, 1, 2, 0, 0, 3, 3, 2, 0, 0, 1, 1, 2, 2, 2, 2, 0, 1, 1
where 0 = white shirt, 1 = yellow, 2 = red, 3 = black. You're interested in knowing if the pattern is random or not. The pattern doesn't look very random, but how can you quantify that observation? This is an example of a runs test.
It's unlikely that you'd want to examine shoppers' shirt colors, but there are many examples where the analysis of runs information is meaningful. For example, if you have four Web server machines set up so that the load is designed to be shared equally, a pattern such as the one above could indicate a problem with the load balancer.
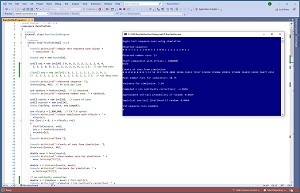 [Click on image for larger view.] Figure 1: Runs Testing Using a C# Simulation in Action
[Click on image for larger view.] Figure 1: Runs Testing Using a C# Simulation in Action
A good way to see where this article is headed is to take a look at the screenshot of a demo program in Figure 1. The demo sets up the sequence of 24 values shown above. The sequence has 13 runs:
(0 0), (3 3), (2), (1 1), (2), (0 0), (3 3), (2), (0 0), (1 1), (2 2 2 2), (0), (1 1)
A run is a set of consecutive data points that are the same. The demo then scrambles the sequence 1,000,000 times and computes the observed number of runs for each random sequence. Over the 1,000,000 iterations, the average number of runs of a random sequence (with the same composition of data points) is 18.75, which is quite a bit more than the observed 13 runs in the data. So it appears that the sequence does in fact have too few runs if the sequence were truly randomly generated.
The demo estimates the probability of seeing fewer than 13 runs in a random sequence in two different ways. The first technique uses the fact that over many iterations the number of runs is approximately Normal (bell-shaped curve) distributed. The statistical probability estimate is 0.0019 -- only about 2 out of 1,000 -- possible, but very unlikely.
The second technique uses a raw counting technique. In the 1,000,000 iterations there were 13 or fewer runs in a random sequence only 4,888 + 1,370 313 + 59 + 13 + 1 = 6,644 times which is an estimated probability of 0.0066 -- only about 7 out of 1,000. Again, possible, but very unlikely.
The conclusion is that the original pattern could be random, but it's very unlikely. Some underlying process that isn't random is probably responsible for the observed sequence.
This article assumes you have intermediate or better programming skill with the C# language but doesn't assume you know anything about runs testing. The complete demo code and the associated data are presented in this article. The source code and the data are also available in the accompanying download. All normal error checking has been removed to keep the main ideas as clear as possible.
The Demo Program
The complete demo program, with a few minor edits to save space, is presented in Listing 1. To create the program, I launched Visual Studio and created a new C# .NET Core console application named RunsTestSim. I used Visual Studio 2022 (free Community Edition) with .NET Core 6.0, but the demo has no significant dependencies so any version of Visual Studio and .NET library will work fine. You can use the Visual Studio Code program too.
After the template code loaded, in the editor window I removed all unneeded namespace references, leaving just the reference to the top-level System namespace. In the Solution Explorer window, I right-clicked on file Program.cs, renamed it to the more descriptive RunsTestSimProgram.cs, and allowed Visual Studio to automatically rename class Program to RunsTestSimProgram.
Listing 1: Runs Test Simulation Demo Code
using System; // .NET 6.0
namespace RunsTestSim
{
internal class RunsTestSimProgram
{
static void Main(string[] args)
{
Console.WriteLine("\nBegin test sequence runs using" +
" simulation ");
Random rnd = new Random(0);
int[] seq = new int[24] { 0, 0, 3, 3, 2, 1, 1, 2, 0, 0,
3, 3, 2, 0, 0, 1, 1, 2, 2, 2, 2, 0, 1, 1 }; // too few runs
Console.WriteLine("\nObserved sequence: ");
ShowSeq(seq, 40); // 40 vals per line
int obsRuns = NumRuns(seq); // 13 observed
Console.WriteLine("\nObserved number runs: " + obsRuns);
int[] counts = new int[25]; // count of runs
int[] scratch = new int[24];
Array.Copy(seq, scratch, seq.Length);
int nTrials = 1_000_000; // C# 7.0 syntax
Console.WriteLine("\nStart simulation with nTrials = " +
nTrials);
for (int i = 0; i < nTrials; ++i)
{
Shuffle(scratch, rnd);
int r = NumRuns(scratch);
++counts[r];
}
Console.WriteLine("Done ");
Console.WriteLine("\nCounts of runs from simulation: ");
ShowCounts(counts, 40);
double mean = Mean(counts);
Console.WriteLine("\nMean number runs for simulation: " +
mean.ToString("F2"));
double v = Variance(counts, mean);
Console.WriteLine("\nVariance for simulation: " +
v.ToString("F2"));
// no continutiy correction
double z = (obsRuns - mean) / Math.Sqrt(v);
Console.WriteLine("\nComputed z (no continuity correction): " +
z.ToString("F4"));
// with continuity correction
// double z = 0.0;
// if (obsRuns > mean) // right tail
// z = ((obsRuns - mean) - 0.5) / Math.Sqrt(v);
// else // obsRuns < mean : left-tail
// z = ((obsRuns - mean) + 0.5) / Math.Sqrt(v);
// Console.WriteLine("\nComputed z (with continuity correction): " +
// z.ToString("F4"));
double p = OneTail(z); //
Console.WriteLine("\nApproximate one-tail probability if random: " +
p.ToString("F4"));
double likely = 0.0;
if (obsRuns > mean)
likely = Likelihood(counts, obsRuns, "right");
else
likely = Likelihood(counts, obsRuns, "left");
Console.WriteLine("\nEmpirical one-tail likelihood if random: " +
likely.ToString("F4"));
Console.WriteLine("\nEnd sequence runs example ");
Console.ReadLine();
} // Main()
static double OneTail(double z)
{
// raw z could be pos or neg
if (z < 0.0) z = -z; // make it positive is usual
double p = 1.0 - Phi(z); // from z to +infinity
return p;
}
//static double TwoTail(double z)
//{
// // likehood of z, z is positive
// double rightTail = 1.0 - Phi(z); // z to +infinity
// return 2.0 * rightTail;
//}
static double Phi(double z)
{
// cumulative density of Standard Normal
// erf is Abramowitz and Stegun 7.1.26
if (z < -6.0)
return 0.0;
else if (z > 6.0)
return 1.0;
double a0 = 0.3275911;
double a1 = 0.254829592;
double a2 = -0.284496736;
double a3 = 1.421413741;
double a4 = -1.453152027;
double a5 = 1.061405429;
int sign = 0;
if (z < 0.0)
sign = -1;
else
sign = 1;
double x = Math.Abs(z) / Math.Sqrt(2.0);
double t = 1.0 / (1.0 + a0 * x);
double erf = 1.0 - (((((a5 * t + a4) * t) + a3) *
t + a2) * t + a1) * t * Math.Exp(-x * x);
return 0.5 * (1.0 + (sign * erf));
}
static int NumRuns(int[] seq)
{
int runs = 0;
int last = -1;
for (int i = 0; i < seq.Length; i++)
{
if (seq[i] != last)
{
++runs;
last = seq[i];
}
}
return runs;
}
static double Likelihood(int[] counts, int obsRuns, string leftOrRight)
{
int countOutsideObsRuns = 0;
int totalCount = 0;
for (int i = 0; i < counts.Length; ++i)
{
// i is a runs count, [i] is a freq
totalCount += counts[i];
if (leftOrRight == "left")
{
if (i <= obsRuns) countOutsideObsRuns += counts[i];
}
else if (leftOrRight == "right")
{
if (i >= obsRuns) countOutsideObsRuns += counts[i];
}
}
return (countOutsideObsRuns * 1.0) / totalCount;
}
static double Mean(int[] counts)
{
int sum = 0;
int n = 0; // number of values
for (int i = 0; i < counts.Length; ++i)
{
sum += i * counts[i]; // i is number runs, [i] is freq
n += counts[i];
}
double mean = (sum * 1.0) / n;
return mean;
}
static double Variance(int[] counts, double mean)
{
double sumSquares = 0.0;
int n = 0;
for (int i = 0; i < counts.Length; ++i)
{
sumSquares += counts[i] * ((i - mean) * (i - mean));
n += counts[i];
}
return sumSquares / n;
}
static void Shuffle(int[] seq, Random rnd)
{
int n = seq.Length;
for (int i = 0; i < n; ++i)
{
int ri = rnd.Next(i, n); // be careful
int tmp = seq[ri];
seq[ri] = seq[i];
seq[i] = tmp;
}
}
static void ShowSeq(int[] seq, int n)
{
for (int i = 0; i < seq.Length; i++)
{
Console.Write(seq[i] + " ");
if ((i + 1) % n == 0)
Console.WriteLine("");
}
Console.WriteLine("");
}
static void ShowCounts(int[] counts, int n)
{
// n is number values per line
for (int i = 0; i < counts.Length; i++)
{
Console.Write(counts[i] + " ");
if ((i + 1) % n == 0)
Console.WriteLine("");
}
Console.WriteLine("");
}
} // Program
} // ns
The demo program begins by setting up a sequence to analyze, and a Random object for scrambling the sequence:
Random rnd = new Random(0);
int[] seq = new int[24] { 0, 0, 3, 3, 2, 1, 1, 2, 0, 0,
3, 3, 2, 0, 0, 1, 1, 2, 2, 2, 2, 0, 1, 1 }; // too few runs
The random seed value of 0 is arbitrary. Next, the number of observed runs in the sequence is computed using a program-defined helper function NumRuns():
int obsRuns = NumRuns(seq); // 13 observed
Console.WriteLine("\nObserved number runs: " + obsRuns);
Compared to some alternative classical statistics techniques such as Wald-Wolfowitz, one advantage of the simulation approach is that it can handle very long sequences. So, although you could manually count the number of runs in the sequence being examined, using a helper function to count runs is a better approach.
Next, the demo sets up an array to hold the number of runs seen in the simulation, and makes a copy of the source sequence:
int[] counts = new int[25]; // count of runs
int[] scratch = new int[24];
Array.Copy(seq, scratch, seq.Length);
Notice that because the source sequence has 24 items, the maximum number of runs is 24. But to store the count of times 24 runs appeared you need to declare an array size of 25 because of zero-based indexing.
The heart of the simulation is:
int nTrials = 1_000_000; // C# 7.0 syntax
Console.WriteLine("\nStart simulation with nTrials = " +
nTrials);
for (int i = 0; i < nTrials; ++i)
{
Shuffle(scratch, rnd);
int r = NumRuns(scratch);
++counts[r];
}
Console.WriteLine("Done ");
In each of the 1,000,000 trials, the copy of the source sequence is scrambled into random order using a program-defined Shuffle() function. After scrambling, the number of runs in the scrambled sequence is computed and stored.
After the simulation, the demo computes the mean (average) number of runs seen and the variance of the runs seen:
double mean = Mean(counts);
Console.WriteLine("\nMean number runs for simulation: " +
mean.ToString("F2"));
double v = Variance(counts, mean);
Console.WriteLine("\nVariance for simulation: " +
v.ToString("F2"));
The mean is needed for both the statistical estimate and the empirical estimate of the likelihood of seeing the observed number of runs. The variance is needed only for the statistical estimate.
The statistical estimate is computed like so:
double z = (obsRuns - mean) / Math.Sqrt(v);
Console.WriteLine("\nComputed z (no continuity correction): " +
z.ToString("F4"));
double p = OneTail(z); //
Console.WriteLine("\nApproximate one-tail probability if random: " +
p.ToString("F4"));
The program-defined OneTail() function estimates the probability of seeing less than the observed number of runs (13) if the sequence is random (18.75 runs).
The demo concludes by computing a likelihood estimate based on counts of runs from the simulation:
double likely = 0.0;
if (obsRuns > mean)
likely = Likelihood(counts, obsRuns, "right");
else
likely = Likelihood(counts, obsRuns, "left");
Console.WriteLine("\nEmpirical one-tail likelihood if random: " +
likely.ToString("F4"));
The program-defined Likelihood() function scans through the counts[] array and adds the number of times there were 13 runs or fewer.
Understanding the Statistical Estimate Approach
The key idea behind estimating the probability of seeing an observed number of runs in a sequence is that for a large number of simulation iterations, the number of runs seen will be approximately Normal (also called Gaussian, or bell-shaped). The graph in Figure 2 shows the distribution of the number of runs seen in 1,000,000 iterations.
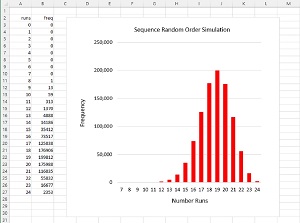 [Click on image for larger view.] Figure 2: Distribution of Number of Runs for Random Sequences
[Click on image for larger view.] Figure 2: Distribution of Number of Runs for Random Sequences
The graph shows that the mean number of runs is about 19 and the standard deviation (measure of spread) is about (24 - 12) / 6 = 2.0. The variance of the data is the standard deviation squared, or about 2.0^2 = 4.0. If you refer back to the demo run in Figure 1, the actual computed mean is 18.75 and the actual computed variance is 3.94.
To estimate probability of an extreme number of runs -- too many or too few -- you can convert an observed number of runs using the equation z = (obs - mean) / sd. For the demo sequence this is z = (13 - 18.75) / sqrt(3.94) = -5.75 / 1.98 = -2.8969. Then you can look up the probability associated with z in a table, or you can compute the probability programmatically.
The demo program uses the programmatic approach to compute the estimated probability of seeing fewer than 13 runs if the sequence is randomly generated. The function to compute is known as the cumulative density function (CDF) for the standard Normal distribution, or the phi() function for short. The phi() function cannot be computed exactly so there are several estimation equations. The demo uses a function known as the erf() function ("error function") estimated by math equation A&S 7.1.26.
Understanding the Empirical Estimate Approach
To estimate the likelihood of an extreme number of runs in a sequence, the first step is to compute the mean number of runs from the simulation. The demo program does this using this function:
static double Mean(int[] counts)
{
int sum = 0;
int n = 0; // number of values
for (int i = 0; i < counts.Length; ++i)
{
sum += i * counts[i]; // i is number runs, [i] is freq
n += counts[i];
}
double mean = (sum * 1.0) / n;
return mean;
}
Suppose a small simulation ran 16 times and counts array looks like [0, 0, 3, 8, 5]. This means that there were 0 times with 0 runs, 0 times with 1 run, 3 times with 2 runs, 8 times with 3 runs, and 5 times with 4 runs. In other words, the index value is a number of runs and the cell value is a count of runs. If the number of runs were extracted from the counts array, they would be (0, 0, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 5, 4, 4, 4, 4). The mean is (0 + 0 + 2 + . . + 4) / 15 = 50 / 15 = 3.33.
The sum value in the code is computed as (0 * 0) + (1 * 0) + (2 * 3) + (3 * 8) + (4 * 5) = 50. The n value in the code is 0 + 0 + 3 + 8 + 5 = 15. The mean value is 50.0 / 15 = 3.33.
After the mean number of counts seen in the simulation has been computed, you can easily compute the empirical likelihood of the observed number of runs. The key statements in program-defined function Likelihood() are:
for (int i = 0; i < counts.Length; ++i)
{
totalCount += counts[i];
if (leftOrRight == "left")
if (i <= obsRuns) countOutsideObsRuns += counts[i];
else if (leftOrRight == "right")
if (i >= obsRuns) countOutsideObsRuns += counts[i];
}
For example, in the demo simulation with 1,000,000 iterations, the counts of low numbers of runs are:
8 runs: 1
9 runs: 13
10 runs: 59
11 runs: 313
12 runs: 1370
13 runs: 4888
Therefore, the empirical likelihood of seeing 13 runs or fewer is (1 + 13 + 59 + 313 + 1370 + 4888) / 1,000,000 = 6644 / 1,000,000 = 0.0066.
Notice that the empirical calculation estimate used in the demo is for 13 runs or fewer (0.0066), but the statistics calculation estimate is for strictly fewer than 13 runs (0.0019). But both of these values are just estimates of too few runs to be random.
Wrapping Up
It's important to remember that the results of a runs test on a sequence can only suggest that a sequence is probably not generated randomly. Therefore, conclusions should be conservative and similar to, "It is unlikely the sequence was generated by a random process" or "There is no evidence that the sequence wasn't generated randomly." A conclusion such as, "The data shows the pattern isn't random" is too strong.