In-Depth
Parallel Programming: The Path from Multicore to Manycore
The future of computing is very exciting and the shift to abundant hardware parallelism may seem a little frightening in terms of programming challenges. The best way to be ready is to learn to think parallel and to program in tasks not threads. Nothing matters more.
Advancement in computer performance in the past five years has been coming through hardware parallelism instead of from the clock-rate increases that we enjoyed for roughly 20 years. As a result, multicore processors have taken us from one core per processor to four to 10 cores per processor today. Graphical Processing Units (GPUs) and heterogeneous solutions offer significant opportunities for parallel programming as well.
A big leap in core-counts is coming. Manycore processors offer a staggering amount of parallelism to program. Programmers will be faced with a broad spectrum of parallelism to address because manycore won't displace multicore immediately.
Intel Corp. has demonstrated 32- and 48-core processors and shipped them under advanced development and research programs already. Intel has announced it will deliver products with more than 50 cores after the company moves to 22nm processes next year.
A feeling of panic over this rapid jump to more and more cores is understandable. Fortunately, there's a sane way to address the situation.
Go Abstract: Tasks Not Threads
One piece of advice that has gained nearly universal acceptance is to avoid thread-based programming in an application and instead program in terms of tasks. For the purpose of this explanation, we'll assume the following definitions of tasks and threads. "Tasks" are pieces of work without any decision of where they'll run. "Threads" have a one-to-one mapping of software threads to hardware threads. An application programmer shouldn't be in the business of breaking up a program, or algorithm, into pieces with the goal of mapping pieces explicitly to the hardware. Two big reasons jump out for this: first, hardware is not symmetrical today, and it will get less so in the future; second, nested parallelism is important and nearly impossible to manage well in threads.
It's no small wonder that the Massachusetts Institute of Technology (MIT) research project called Cilk (pronounced "silk") has lead to "work-stealing" schedulers and tasking models that now dominate the field. Intel Cilk Plus descends directly from the MIT work and is implemented in the Intel compilers. Cilk Plus may appear in other compilers following the Cilk Plus specification published last year. Intel Threading Building Blocks (TBBs) is an open source project implementing the Cilk Plus concepts in C++ templates, which has been ported to many different OSes and processors. Microsoft has implemented the same task-centric programming model in its Template Patterns Library (TPL), bringing the concepts to the .NET world and a corresponding Parallel Patterns Library (PPL) offering for Microsoft Visual Studio users of C++. Apple Inc. focuses programmers on its task-centric Grand Central Dispatch (GCD). If you want to understand more about the reasons for this flight to programming in task, an excellent detailed explanation of the evils of threading is "The Problem with Threads," by Edward Lee at University of California, Berkeley (bit.ly/13ur3Y).
Task Parallelism: Smooth as Cilk
The Cilk project at MIT, under the guidance of Professor Charles Leiserson, has generated numerous papers and inspired work-stealing, task-based schedulers including TBB, Cilk Plus, TPL, PPL and GCD. Cilk is also used in teaching and in some college textbooks.
It's instructive to consider how Cilk Plus evolved to address the issues central to this article: specifically easing the work to "think parallel" and providing abstractions for parallel programming.
Cilk originated in the mid-1990s at MIT and has evolved to Cilk Plus today with support on Windows, Linux and, soon, on Mac OS X.
Cilk Plus represents a simple but powerful way to specify parallelism in C and C++. The simplicity and power come, in no small part, from compiler technology. Compiler implementations allow very simple keywords to slip into existing programs and modify a serial application into a parallel application.
Cilk started with only two keywords: cilk_spawn and cilk_sync. To purists this was enough, and the simplicity seemed unbeatable. Having just the ability to send a function running in the background (a separate thread), and to wait for all the locally spawned functions to finish with cilk_sync was a great start.
Listing 1 and Listing 2 show how this concept is realized with minimal changes to the original serial code. Using the classic recursive function to compute Fibonacci numbers as an illustration, we see that the simple addition of a cilk_spawn and a cilk_sync allows parallel execution of the two functions, which need to be computed, and then summed once both calls complete.
This example highlights one of the main design principles of this style of parallelism: it's designed for parallelizing existing serial C/C++ code by making minimal changes, while providing strong guarantees for serial equivalence. Serial equivalence means the program should compute the same answer if the keywords are ignored. In fact, use of "#define cilk_spawn" and "#define cilk_sync" can illustrate this concept or be used to provide portability to compilers that don't support the keywords. Using such #define directives to eliminate the keywords illustrates the serial equivalence that makes this style of parallelism very easy to understand.
It wasn't long before one more keyword was added, namely cilk_for.
Transforming a loop into a parallel loop by simply changing "for" to "cilk_for" is so easy to learn and use, it has proven irresistible. The alternative of spawning each iteration imposes too much overhead by requiring every iteration to be a task, and has undesirable cache effects. Giving the compiler the information that the iterations of a loop may be done in parallel is enough for the compiler to produce code that "does the right thing" at runtime. If the program is run on a single core, the need for iterations being broken into multiple tasks is not the same as it would be running on a quad-core system. The use of "#define cilk_for for" illustrates serial equivalence and offers portability to compilers without support for cilk_for.
Think Parallel
Parallel programming is easy to understand and utilize when the work to be done is completely independent. It's the interaction between concurrent tasks of an application that are challenging and therefore require a plan for managing sharing between concurrent tasks. The seemingly most fundamental sharing is simple sharing of data via shared memory, and yet nothing gives rise to more challenges in concurrent programming. All parallel computer designs struggle to offer some relief, varying from simple to exotic solutions, but in all cases the best results come from reduced sharing and the worst from unnecessary and frequent fine-grained sharing of data.
Nothing is more fundamental to parallel programming than understanding both sharing and scaling as well as the general relationship between them.
Understanding sharing and how to manage it is the key to parallel programming -- less is better. Take away sharing and parallel programming is at once both trivial and scalable. Most programming will require some sharing, and this gives rise to studying parallel algorithms. Understanding the appropriate algorithm to use is more an exercise in efficient sharing than it is an exercise in efficient use of the processing capabilities of a microprocessor.
Dividing up a program consisting of steps A, B, C and D could be visualized, as shown in Figure 1.
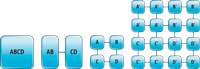
[Click on image for larger view.] |
| Figure 1. Subdividing a program ABCD for parallelism. |
In Figure 1, a single program with no parallelism or concurrency simply performs A, B, C and D in sequence. A system with dual capability to perform work might divide up work so one thread performs A and B, and the other performs C and D. A four-way system can perform A, B, C and D with each using separate resources.
In the dual- and quad-execution examples, we have the extra challenge already of mapping both computation and communications around our system. Computation needs to be subdivided and spread across the system, and communication between the computational units becomes important. The challenge of continued subdivision is illustrated in the 16-way system by visibly subdividing A, B, C and D into four pieces, each with less resemblance to the original tasks than we saw in the two-way or four-way examples. We also see an explosion of connections between computational units. The diagram only shows 24 connections, but, logically, 240 distinct connections can be considered.
Comprehending these two new challenges -- spreading computation and managing communications -- is the essence of parallel programming. Effective parallel programming requires effective management of the distribution of work and control of the communication required.
There's no getting away from the need for an effective programmer to deal with the need to "think parallel." However, by programming in tasks and not threads, the job of parallel programming becomes much more approachable.
Cilk and Data Parallelism
Addressing task parallelism is only half of the solution, however. Once we have abstractions for task parallelism that help with sharing and scaling, we find that data parallelism needs attention as well. Abstractions for data parallelism can complete the picture, and leave parallel programmers with the tools to help as we learn to think parallel.
It's instructive to look to the Cilk project and how it has grown along these lines over the past 15 years to lead the way. The earliest results from Cilk have proven popular, finding ways into solutions on Windows, Linux and Mac OS X systems, with open source, Intel, Microsoft and Apple providing solutions all based on work-stealing algorithms pioneered by the MIT project.
Today we see data parallelism being addressed in Cilk Plus. Will it be as popular? As programmers, we should hope that some solution takes hold. Having every compiler -- and every system -- help with data parallelism will, in a sense, complete the picture.
After the original two-keyword Cilk, three things have been added to make Cilk Plus. The first enhancement was cilk_for.
The second addition to Cilk was hyper-objects. Hyper-objects help break up a shared variable into private copies to enable parallelism without bottlenecking on a shared variable, and allow specification of reduction operations. Sound complicated? Well, the beauty of hyper-objects is they make it look simple and they're easy to learn. Hyper-objects help solve the inevitable sticky data problems in task parallel situations.
The third enhancement in Cilk Plus is the ability to specify data-parallel operations explicitly with new vector and array notations for C and C++. Current programming today can be quite obtuse upon reflection. Consider the following loop:
for (i=0; i<10000; i++) {
a[i] = b[i] + c[i];
}
Writing such a loop is unnecessarily complicated when you really want to just say:
a[:] = b[:] + c[:];
Cilk Plus also adds elemental functions into C and C++, which is consistent with the goal of leaving today's code largely intact but adding the ability to take advantage of data parallelism.
Consider the following code; as written, it can never use data parallel instructions, such as SSE and AVX, because the function operates on one floating-point value at a time:
float my_simple_add(float x1, float x2){
return x1+x2;
}
for (int j = 0; j < N; ++j) {
outputx[j] = my_simple_add(inputa[j],inputb[j]);
}
Getting at the parallelism has traditionally required non-trivial rewriting of the code, sometimes referred to as "refactoring" code. Compiler technology can provide a better solution with Cilk Plus. The following code shows a one-line addition (the first line) that suddenly results in a program that will use SSE or AVX instructions to yield significant speed-up from data parallelism.
__declspec(vector)
float my_simple_add(float x1, float x2){
return x1+x2;
}
for (int j = 0; j < N; ++j) {
outputx[j] = my_simple_add(inputa[j],inputb[j]);
}
In this case, the compiler will create data-parallel versions of the function and call them whenever it detects an opportunity. In the example shown, the number of calls to the function can be reduced by a factor of eight for AVX or a factor of four for SSE. This will result in similarly impressive performance increases.
In the future, we'll see task- and data-parallel support added into more languages and compilers. Cilk Plus gives us a glimpse into what it can look like and how simple it can be.
Safety in Numbers
Another huge consideration is "safety." Parallel programming can lead to programming errors known as data races and deadlocks. Both come from improper synchronization between tasks or threads. New tools can help detect these problems. New programming methods like Cilk Plus have shown the ability to reduce errors significantly. Research into Cilk over the years has proven this ability to allow for extremely fast detection of key errors, a seemingly distinct advantage of this approach.
Today almost all computers are parallel systems, but only some software uses parallel programming to full advantage. The future of parallel programming will demand abstract programming methods that allow independence from the underlying hardware for portability from vendor to vendor and portability into the future.
The advice for programmers is simple: learn to "think parallel," program in tasks not threads, and look for abstract programming methods that span to the future by addressing task parallelism, data parallelism and safety for multicore today with a path to manycore futures.
How to think about parallelism, or how to teach it, is a problem we'll be working on for years to come. You could say that the problem is how to teach ourselves to think about these systems instead of just programming them.
If that seems like a lot to absorb, just go grab some code, convert it to run in parallel and try it out (on the largest number of cores you can). Experience is invaluable. You shouldn't wait. As long as you program using abstract programming methods, starting with task-based programming, you'll gain invaluable experience by just doing it.
Specific recommendations for task-based programming are:
- C++ programmers: TBB
- C and C++ programmers: Cilk Plus
- .NET programmers: TPL
- Objective-C (Mac OS X): GCD
All these have solutions to program in tasks, not threads. Only Cilk Plus has integrated data parallelism and safety solutions as well. That is the state we find ourselves in today. Don't let that stop you -- just pick one and try it out. The experience is invaluable and will prepare you better for a world with lots and lots of cores. Enjoy!