In-Depth
What's New in C# and .NET 4
While .NET 3.0 and 3.5 were great additions to the .NET framework, they were built against the 2.0 Common Language Runtime (CLR). Now, Microsoft has released .NET 4 – in addition to a new CLR, we've got a ton of framework and language improvements. We'll cover some of those changes here and will continue to cover .NET 4 in future articles.
C# Language
Let's start by covering a few of the new features of the C# language. After that, we'll check out some IDE enhancements to make your C# development experience more productive.
Named and Optional Arguments
With support for named arguments, you can reduce the amount of typing you need to do when calling a method (or indexer, constructor or delegate).
Let's say you have a method with 4 arguments (x, y, width and height). And because this API was designed nicely, the arguments are actually named "x", "y", "width" and "height". When it comes time to calling that method, if you can only remember the argument names but not their position, named arguments will help:
CalulateIntersection(x: 20, y: 30, height: 10, width: 4);
Or maybe it was width and height that went first?
CalulateIntersection(height: 10, width: 4, x: 20, y: 30);
With named arguments, both of these calls are equivalent and pass the same data to the method.
Optional arguments allow you to specify a default value for an argument. The default value will be used if the caller does not provide a value for the optional parameter. The syntax is simple:
public void MakeBeta(int value, string name = "Beta1", string version = "1.0")
In the method signature above, name and version are optional. If not supplied by the caller, "name" will get the value "Beta1" and "version" will be "1.0". Even though optional parameters are, um, optional, you can't leave them out altogether. If you wanted to call "MakeBeta" with the default name but a specific version, you can use named arguments:
MakeBeta(34, version: "2.4");
If you've done any COM-interop, especially with the Microsoft Office COM API's, you'll quickly see how powerful optional and named arguments will be to you. Before named arguments, you had to use Type.Missing for optional parameters:
excelApp.get_Range("A5", "C7").AutoFormat(myFormat, Type.Missing, Type.Missing,
Type.Missing, Type.Missing, Type.Missing);
Now you can take advantage of named arguments and simply supply the format argument:
excelApp.get_Range("A5", "C7").AutoFormat(format:myFormat);
Good bye Type.Missing! You won't be missed (pardon the pun)!
Dynamic keyword
The "dynamic" keyword allows you to define a type that has its type checking done at runtime rather than compile time. Why would you want to wait until runtime to do your type checking? It allows your application to be more flexible: You don't care where an object came from – COM interop, reflection, a dynamic language like IronPython – you just want to manipulate it.
Consider this example:
public void DoSomething(dynamic x)
{
x.ShowSample();
}
Since "x" is defined as dynamic, no compile-time checks are done. At runtime, the code will work only if the object passed in supports a "ShowSample" method that takes no arguments. It doesn't matter what the type is – as long as it has a "ShowSample" method.
Why defer type checking to runtime? The biggest reason is COM-interop. If you look at some of the Microsoft Office Automation API interfaces, there are a lot of variables and return types defined as "object". This is because the API's were originally designed for a non-type-safe language: VBScript.
With .NET's adherence to strong typing, interop with COM API's like the Microsoft Office API's requires a lot of casting to various interfaces and classes in both method calls as well as return types. It made the code tedious to write and difficult to read.
With the dynamic keyword, we can let the runtime do the type checking and casting for us. A call to set or get the value of a range used to look something like this:
((Microsoft.Office.Interop.Excel.Range)excelApp.Cells[5, 5]).Value = "Language";
var languageRange = (Microsoft.Office.Interop.Excel.Range)excelApp.Cells[5, 5];
Now, by defining the "excelApp" variable as "dynamic", we can let the runtime do the type checking and there is no longer a need to satisfy the compiler with casting:
excelApp.Cells[5, 5].Value = "Language";
var languageRange = excelApp.Cells[5, 5];
Type Equivalence Support
Type Equivalence Support (or "Type Embedding") allows you to avoid a major pitfall of writing clients against strongly-type interop assemblies; that is, when a new version of the strongly-typed interop assembly is released, you have to recompile your client – even if you're not using any of the new features.
With type embedding, you can actually embed type information into a client. So if the type information changes on the target machine (because the user upgraded to the next version of Microsoft Office, for example), the type information embedded into the client can be used without the need to recompile the client application.
A simple example of how this works is beyond the scope of this article. See the MSDN documentation on "Walkthrough: Embedding Types from Managed Assemblies" for a complete explanation and sample code.
Covariance and Contravariance
This is one of those tricky things that could take up an entire article. As a matter of fact, former "C# Corner" author Bill Wagner did just that back in May of 2009. His article, "Generic Covariance and Contravariance in C# 4.0" provides an in-depth look at how C# handles type conversions and decides which ones are allowed and which aren't. You can read the article online here.
C# IDE
The C# language wasn't the only part of C# that was improved. Microsoft spent a lot of time on Visual Studio as well. The IDE shell was rewritten in WPF (ever heard of the term "eating your own dog food?") and uses MEF (Managed Extensibility Framework) to offer even more extensibility points. Here are a few C# IDE enhancements in 2010.
Call Hierarchy
This is one of my favorite features in the new IDE. Simply right-click on the name of any method, constructor or property and select "View Call Hierarchy". The Call Hierarchy window will appear. A sample is shown below in Figure 1 for a method called "WhiteOutRows":
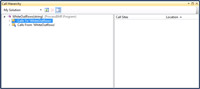
[Click on image for larger view.] |
| Figure 1. Call Hierarchy Window |
There are two nodes underneath the method name: Calls To and Calls From. Expanding "Calls To" will show all calls made to the selected item. Likewise, selecting "Calls From" will list all calls made from the method. See Figure 2 where I opened the "Calls From WhiteOutRows" node:
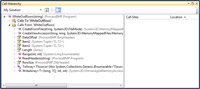
[Click on image for larger view.] |
| Figure 2. Calls from WhiteOutRows |
You can continue to navigate further down the "call stack" since each method and property name listed under the "Calls To" or "Calls From" will have their own "Calls To" and "Calls From" nodes.
This is like a super-charged call stack window – and it's available at design time!
Generate From Usage
As a fan of test-first development, I like the new "Generate From Usage" feature.
Let's say we’re writing a simple banking application and we need to write some code to transfer some money between two accounts. Let’s start with a unit test:
[TestMethod]
public void TransferFundsTest()
{
Account source = new Account() {Balance = 300.0};
Account destination = new Account() {Balance = 100.0};
var xferService = new XferService();
xferService.Transfer(source, destination, 50.0);
Assert.AreEqual(250, source.Balance);
Assert.AreEqual(150, destination.Balance);
}
Lots of errors in there! That’s because we haven’t even written an Account class or an XferService class. Visual Studio can help us start generating some code based on our unit test.
Right-click on the one of the red "Account" instances and select "Generate" and then "Class". Visual Studio generates a simple Account class with no members. Now right-click on one of the red "Balance" references and select "Generate" and then "Property". Our Account class now has a simple get/set Balance field. Repeat these same steps with XferService and the Transfer method. Without too much work, we’ve got the following code generated from our unit tests:
class Account
{
public double Balance { get; set; }
}
class XferService
{
internal void Transfer(Account source, Account destination, double p)
{
throw new NotImplementedException();
}
}
Not runnable code, but a nice start at fleshing out our design based on our unit tests!
Reference Highlighting
Reference Highlighting adds a nice navigational feature to the IDE. Select any word in the IDE. You’ll notice that all instances of that word are highlighted in the code editor. It’s a quick way to show you where usages of that word object (class, variable, method, property) can be found. And you can navigate between all highlighted instances with CTRL+SHIFT+DOWN ARROW and CTRL+SHIFT+UP ARROW.
Conclusion
All in all, Microsoft has done a very nice job of putting lots of features into both C# and the Visual Studio IDE. Remember, this article covered just a few of the highlights. Check out http://msdn.microsoft.com/en-us/vstudio/default.aspx for more information on Visual Studio 2010 and C# 4.0
About the Author
Patrick Steele is a senior .NET developer with Billhighway in Troy, Mich. A recognized expert on the Microsoft .NET Framework, he’s a former Microsoft MVP award winner and a presenter at conferences and user group meetings.