Neural Network Lab
Neural Network Data Normalization and Encoding
James McCaffrey explains how to normalize and encode neural network data from a developer's point of view.
A topic that's often very confusing for beginners when using neural networks is data normalization and encoding. Because neural networks work internally with numeric data, binary data (such as sex, which can be male or female) and categorical data (such as a community, which can be suburban, city or rural) must be encoded in numeric form. Additionally, experience has shown that in most cases numeric data, such as a person's age, should be normalized. There are many references that discuss the theory of normalization and encoding, but few that provide practical guidance and even fewer that provide code-implementation examples. This article explains how to normalize and encode neural network data from a developer's point of view. The process is conceptually simple but surprisingly difficult to implement.
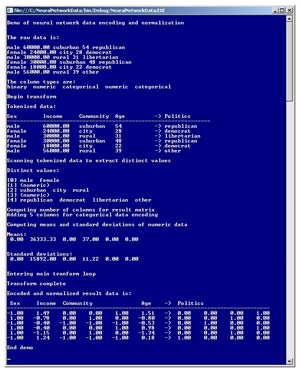
The best way to see where this article is headed is to take a look at the screenshot of a demo program in Figure 1. The demo program starts with six lines of raw data that's intended to be fed to a neural network. Each line represents a person. The raw data is:
male 60000.00 suburban 54 republican
female 24000.00 city 28 democrat
male 30000.00 rural 31 libertarian
female 30000.00 suburban 48 republican
female 18000.00 city 22 democrat
male 56000.00 rural 39 other
 [Click on image for larger view.]
Figure 1. The normalization and encoding demo.
[Click on image for larger view.]
Figure 1. The normalization and encoding demo.
The first field is the person's sex, the second is annual income in dollars, the third is community type, and the fourth is age. The fifth field is the person's political affiliation. The idea is to create a neural network model that uses the first four variables to predict a person's political affiliation. The first variables are called the independent, or x, variables. The variable to predict is called the dependent, or y, variable.
When using neural networks, raw data is usually binary (two possible values), categorical (three or more possible values) or numeric. In the demo, sex is identified as binary, income as numeric, community as categorical, and age as numeric. The dependent variable, political affiliation, is tagged as categorical.
The demo program breaks the raw data down into individual fields and stores each value in a string matrix. Next, the program scans the tokenized data to determine all the distinct binary and categorical values. Then the program scans the tokenized data and computes the means (mathematical averages) and standard deviations of the numeric data (income and age). Next, the demo program iterates through each of the six data lines and encodes binary and categorical data, and normalizes numeric data. The demo finishes by displaying the final, normalized and encoded data, which can be used by a neural network to predict political affiliation from sex, income, community type and age.
This article assumes you have at least intermediate-level programming skills and a basic knowledge of neural networks. The demo program is coded in C# with static methods, but you shouldn't have too much trouble refactoring the code to another language or using an object-oriented programming (OOP) style if you wish. To keep the main ideas clear, all normal error checking has been removed.
Encoding Binary and Categorical Data
When encoding binary and categorical data, there are four cases you must deal with: independent (x) binary data, dependent (y) binary data, independent (x) categorical data and dependent (y) categorical data. An example of independent binary data is a predictor variable, sex, which can take one of two values: "male" or "female." For such data I recommend encoding the two possible values as -1.0 and +1.0:
male = -1.0
female = +1.0
There's convincing research that indicates a -1.0, +1.0 scheme is superior to a simple 0.0, 1.0 scheme for independent binary variables.
An example of independent categorical data is a predictor variable community, which can take values "suburban," "rural" or "city." For such data I recommend using what's often called 1-of-(C-1) effects encoding. Effects encoding is not obvious and is best explained by example:
suburban = [ 0.0, 0.0, 1.0]
rural = [ 0.0, 1.0, 0.0]
city = [-1.0, -1.0, -1.0]
In other words, effects encoding sets up an array of numeric values. The size of the array is the number of possible values, c. The first categorical value has 0.0 values in all positions except a single 1.0 value in the last position. The second categorical value has the single 1.0 at the second-to-last position, and so on. The last categorical value, instead of having a 1.0 in the first position and 0.0 values in the remaining c-1 positions as you might expect, has -1.0 values at all c positions.
In the demo, the dependent variable, political affiliation, is categorical and has four possible values: "republican," "democrat," "libertarian" and "other." To encode dependent categorical data I recommend using what's often called 1-of-C dummy encoding:
republican = [0.0, 0.0, 0.0, 1.0]
democrat = [0.0, 0.0, 1.0, 0.0]
libertarian = [0.0, 1.0, 0.0, 0.0]
other = [1.0, 0.0, 0.0, 0.0]
In other words, 1-of-C encoding is the same as effects encoding except that that last categorical value has a 1.0 in the first array position, and 0.0 values in all other c-1 positions.
Instead of having four possible values, suppose the dependent variable, political affiliation, had just two values, "conservative" or "liberal." This would be an example of dependent binary data. In such situations I recommend using a simple 0.0, 1.0 scheme:
conservative = 0.0
liberal = 1.0
It isn't at all obvious why I recommend four different encoding schemes for the four different data cases. And there are several alternatives. You can find many online references that go into a painfully detailed discussion of this topic if you're interested in the theory behind these encoding recommendations.
Normalizing Numeric Data
There are two neural network numeric data cases: independent (x) numeric data and dependent (y) numeric data. An example of independent numeric data values are the ages (54, 28, 31, 48, 22, 39) in the demo program. I recommend normalizing independent numeric data by computing the means and standard deviation of the numeric x data, then applying the transform (x - mean) / stddev.
For example, in the demo program, the mean of all six age values is 37.0 and the standard deviation of the six age values is 11.22. So the normalized age for the first person is (54.0 - 37.0) / 11.22 = 1.51.
In most cases, normalized numeric data will have values that range between -6.0 and +6.0. The idea behind data normalization is to scale all numeric data to have roughly similar magnitudes. In the demo, a typical annual income value is 30,000.0, but a typical age value is 31.0. Without normalization, the large magnitudes of the income data relative to the age data would make the neural network training process more difficult than with normalized data, because changes to the income-weights would have a much greater effect than changes to the age-weights.
For dependent numeric data, except in very unusual situations, I recommend not normalizing or transforming the data.
The Demo Program
The structure of the demo program, with a few minor edits, is presented in Listing 1. To create the demo, I launched Visual Studio (any recent version will work) and created a new C# console application program named NeuralNetworkData. After the template code loaded, I removed all using statements except the ones that reference the System and Collections.Generic namespaces. In the Solution Explorer window I renamed file Program.cs to NeuralDataProgram.cs, and Visual Studio automatically renamed the class Program.
Listing 1. The neural network data demo program structure.
using System;
using System.Collections.Generic;
namespace NeuralNetworkData
{
class NeuralDataProgram
{
static void Main(string[] args)
{
Console.WriteLine("\nDemo of neural network data encoding and normalization\n");
string[] rawData = new string[] {
"male 60000.00 suburban 54 republican",
"female 24000.00 city 28 democrat",
"male 30000.00 rural 31 libertarian",
"female 30000.00 suburban 48 republican",
"female 18000.00 city 22 democrat",
"male 56000.00 rural 39 other" };
Console.WriteLine("\nThe raw data is: \n");
ShowRawData(rawData);
string[] colTypes = new string[5] { "binary", "numeric", "categorical",
"numeric", "categorical" };
Console.WriteLine("\nThe column types are:");
ShowColTypes(colTypes);
Console.WriteLine("\nBegin transform");
double[][] nnData = Transform(rawData, colTypes);
Console.WriteLine("\nTransform complete");
Console.WriteLine("\nEncoded and normalized result data is:\n");
ShowTransformed(nnData);
Console.WriteLine("\nEnd demo\n");
Console.ReadLine();
}
static double[][] Transform(string[] rawData, string[] colTypes) { . . }
static double BinaryIndepenToValue(string val, int col,
string[][]distinctValues) { . . }
static double BinaryDepenToValue(string val, int col,
string[][]distinctValues) { . . }
static double[] CatIndepenToValues(string val, int col,
string[][]distinctValues) { . . }
static double[] CatDepenToValues(string val, int col,
string[][]distinctValues) { . . }
static double NumIndepenToValue(string val, int col, double[] means,
double[] stdDevs) { . . }
static int NumNewCols(string[][]distinctValues, string[] colTypes) { . . }
static string[][] GetValues(string[][] data, string[] colTypes) { . . }
static string[][] LoadData(string[] rawData) { . . }
static double[] GetMeans(string[][] data, string[] colTypes) { . . }
static double[] GetStdDevs(string[][] data, string[] colTypes,
double[] means) { . . }
static void ShowVector(double[] vector, int decimals) { . . }
static void ShowRawData(string[] rawData) { . . }
static void ShowColTypes(string[] colTypes) { . . }
static void ShowTokenData(string[][] data) { . . }
static void ShowDistinctValues(string[][] distinctValues) { . . }
static void ShowTransformed(double[][] nnData) { . . }
} // Program
} // ns
The primary method is Transform. It accepts an array of strings that are the raw data to encode. In most non-demo situations, raw neural network data will be stored in a text file or SQL table. There are five methods that correspond to five of the six normalization and encoding cases -- recall that dependent numeric data doesn't require any normalization. There are five other very short helper methods (which are used by method Transform) and six display methods.
The Helper Methods
Method LoadData accepts the raw data, tokenizes each line into separate items, and returns an array-of-arrays style tokenized string matrix:
static string[][] LoadData(string[] rawData)
{
int numRows = rawData.Length;
int numCols = rawData[0].Split(' ').Length;
string[][] result = new string[numRows][];
for (int i = 0; i < numRows; ++i) {
result[i] = new string[numCols];
string[] tokens = rawData[i].Split(' ');
Array.Copy(tokens, result[i], numCols);
}
return result;
}
In the rare situations where your neural network raw data is too large to fit into machine memory, you'll have to stream data one line at a time instead of storing it in a matrix.
In some situations you may want to manually specify the distinct values for the categorical and binary columns along the lines of:
string[][] distinctValues = new string[5][];
distinctValues[0] = new string[] { "male", "female" };
distinctValues[1] = new string[] { "(numeric)" };
distinctValues[2] = new string[] { "suburban", "city", "rural" };
...
A more flexible approach is to write a method that scans the tokenized data and determines the distinct value programmatically. Method GetValues does this, and is presented in Listing 2.
Listing 2. Programmatically determining distinct categorical and binary values.
static string[][] GetValues(string[][] data, string[] colTypes)
{
int numCols = data[0].Length;
string[][] result = new string[numCols][];
for (int col = 0; col < numCols; ++col)
{
if (colTypes[col] == "numeric")
{
result[col] = new string[] { "(numeric)" };
}
else
{
Dictionary<string, bool> d = new Dictionary<string, bool>();
for (int row = 0; row < data.Length; ++row)
{
string currVal = data[row][col];
if (d.ContainsKey(currVal) == false)
d.Add(currVal, true);
}
result[col] = new string[d.Count];
int k = 0;
foreach (string val in d.Keys)
result[col][k++] = val;
} // Else
} // Each col
return result;
}
The method processes the tokenized matrix one column at a time and uses string array colTypes to determine the type ("binary," "categorical" or "numeric") of the current column. If the column is numeric, a dummy string value of "(numeric)" is assigned; otherwise, a Dictionary object is used to store the distinct values found in the current column.
The means and standard deviations for each numeric variable are needed to normalize the data. These two helper methods are presented in Listing 3.
Listing 3. Means and standard deviation for each numeric variable.
static double[] GetMeans(string[][] data, string[] colTypes)
{
double[] result = new double[data.Length];
for (int col = 0; col < data[0].Length; ++col)
{
if (colTypes[col] != "numeric") continue;
double sum = 0.0;
for (int row = 0; row < data.Length; ++row) {
double val = double.Parse(data[row][col]);
sum += val;
}
result[col] = sum / data.Length;
}
return result;
}
static double[] GetStdDevs(string[][] data, string[] colTypes,
double[] means)
{
double[] result = new double[data.Length];
for (int col = 0; col < data[0].Length; ++col) // Each column
{
if (colTypes[col] != "numeric") continue;
double sum = 0.0;
for (int row = 0; row < data.Length; ++row) {
double val = double.Parse(data[row][col]);
sum += (val - means[col]) * (val - means[col]);
}
result[col] = Math.Sqrt(sum / data.Length);
}
return result;
}
A matrix of neural network normalized and encoded data will typically have more columns than the tokenized raw data because categorical independent and dependent variables generate multiple values. For example, if variable community has three possible categorical values -- "suburban," "city" and "rural" -- then "city" will be encoded as [0.0, 1.0, 0.0]. In general, an independent or dependent categorical variable with c possible values will generate an array with c values, so each categorical variable generates c-1 new columns. Helper method NumNewColumns computes the number of additional columns needed, relative to the tokenized matrix, for the normalized and encoded data matrix:
static int NumNewCols(string[][] distinctValues, string[] colTypes)
{
int result = 0;
for (int i = 0; i < colTypes.Length; ++i) {
if (colTypes[i] == "categorical") {
int numCatValues = distinctValues[i].Length;
result += (numCatValues - 1);
}
}
return result;
}
The Transform Method
The Transform method accepts a matrix of tokenized raw data and an array that describes the type of each column, and returns a numeric matrix of normalized and encoded data that's suitable for use by a neural network. In the demo program shown in Figure 1, I added many WriteLine statements and used several display methods so you could more easily understand how Transform works. Method Transform, with most WriteLine and display code removed for clarity, is presented in Listing 4.
Listing 4. The Transform method.
static double[][] Transform(string[] rawData, string[] colTypes)
{
string[][] data = LoadData(rawData); // Tokenize
string[][] distinctValues = GetValues(data, colTypes);
int extraCols = NumNewCols(distinctValues, colTypes);
double[][] result = new double[data.Length][];
for (int i = 0; i < result.Length; ++i)
result[i] = new double[data[0].Length + extraCols];
double[] means = GetMeans(data, colTypes);
double[] stdDevs = GetStdDevs(data, colTypes, means);
for (int row = 0; row < data.Length; ++row)
{
int k = 0; // Walk across result cols
for (int col = 0; col < data[row].Length; ++col)
{
string val = data[row][col];
bool isBinary = (colTypes[col] == "binary");
bool isCategorical = (colTypes[col] == "categorical");
bool isNumeric = (colTypes[col] == "numeric");
bool isIndependent = (col < data[0].Length - 1);
bool isDependent = (col == data[0].Length - 1);
if (isBinary && isIndependent) // Binary x value -> -1.0 or +1.0
{
result[row][k++] = BinaryIndepenToValue(val, col, distinctValues);
}
else if (isBinary && isDependent) // Binary y value -> 0.0 or 1.0
{
result[row][k] = BinaryDepenToValue(val, col, distinctValues); // No k++
}
else if (isCategorical && isIndependent)
{
double[] vals = CatIndepenToValues(val, col, distinctValues);
for (int j = 0; j < vals.Length; ++j)
result[row][k++] = vals[j];
}
else if (isCategorical && isDependent)
{
double[] vals = CatDepenToValues(val, col, distinctValues);
for (int j = 0; j < vals.Length; ++j)
result[row][k++] = vals[j];
}
else if (isNumeric && isIndependent)
{
result[row][k++] = NumIndepenToValue(val, col, means, stdDevs);
}
else if (isNumeric && isDependent)
{
result[row][k] = double.Parse(val);
}
} // Each col
} // Each row
return result;
}
Method Transform assumes the dependent y-variable is located in the last column of the tokenized data. If your data has the dependent variable in some other column, the simplest approach is to preprocess the raw data to place the dependent variable into the last column. A more difficult approach is to modify the logic in Transform.
Each column is identified as binary-independent, binary-dependent, categorical-independent, categorical-dependent, numeric-independent or numeric-dependent. Then an appropriate helper method either normalizes or encodes the current data value (except in the case of numeric-dependent data, when no processing is performed).
The five conversion helper methods are presented in Listing 5.
Listing 5. The conversion methods.
static double BinaryIndepenToValue(string val, int col, string[][] distinctValues)
{
if (distinctValues[col].Length != 2)
throw new Exception("Binary X data only 2 values allowed");
if (distinctValues[col][0] == val)
return -1.0;
else
return +1.0;
}
static double BinaryDepenToValue(string val, int col, string[][] distinctValues)
{
if (distinctValues[col].Length != 2)
throw new Exception("Binary Y data only 2 values allowed");
if (distinctValues[col][0] == val)
return 0.0;
else
return 1.0;
}
static double[] CatIndepenToValues(string val, int col,
string[][] distinctValues) // Affects encoding
{
if (distinctValues[col].Length == 2)
throw new Exception("Categorical X data only 1, 3+ values allowed");
int size = distinctValues[col].Length;
double[] result = new double[size];
int idx = 0;
for (int i = 0; i < size; ++i)
{
if (distinctValues[col][i] == val)
{
idx = i; break;
}
}
if (idx == size - 1) // Last val all -1.0s
{
for (int i = 0; i < size; ++i) // Ex: [-1.0, -1.0, -1.0]
{
result[i] = -1.0;
}
}
else // value is not last, use dummy
{
result[result.Length - 1 - idx] = +1.0; // Ex: [0.0, 1.0, 0.0]
}
return result;
}
static double[] CatDepenToValues(string val, int col,
string[][] distinctValues) // 1-of-C encoding
{
if (distinctValues[col].Length == 2)
throw new Exception("Categorical X data only 1, 3+ values allowed");
int size = distinctValues[col].Length;
double[] result = new double[size];
int idx = 0;
for (int i = 0; i < size; ++i)
{
if (distinctValues[col][i] == val)
{
idx = i; break;
}
}
result[result.Length - 1 - idx] = 1.0; // Ex: [0.0, 1.0, 0.0]
return result;
}
static double NumIndepenToValue(string val, int col, double[] means,
double[] stdDevs)
{
double x = double.Parse(val);
double m = means[col];
double sd = stdDevs[col];
return (x - m) / sd;
}
Data Recommendations
Perhaps because the topic isn't glamorous, I haven't found much practical information about neural network data normalization and encoding from a developer's point of view available online. One problem that beginners to neural networks face is that most references describe many normalization and encoding alternatives, but rarely provide specific recommendations. My recommendations are:
- Binary X data: use -1.0 or +1.0 encoding
- Binary Y data: use 0.0 or 1.0 encoding
- Categorical X data: use effects encoding such as [0.0, 0.0, 1.0] or [-1.0, -1.0, -1.0]
- Categorical Y data: use dummy encoding such as [0.0, 0.0, 1.0] or [1.0, 0.0, 0.0]
- Numeric X data: use (x - mean) / stddev normalization
- Numeric Y data: do not normalize
These recommendations have worked well for me in many situations, but I should point out that some neural network experts recommend different encoding and normalization schemes.