Code Focused
Regular Expressions, Part 3: Business Intelligence Uses
You can do a lot more with regular expressions than you think. In this tutorial, you'll use it to convert a movie list into a CSV file for use in Excel.
- By Ondrej Balas
- 03/06/2014
In Part 1 and Part 2 in this series about regular expressions, I went over some of the key features of regular expressions and how to use them in your code.
Regular expressions can be useful in other places, too, such as the find/replace feature of your favorite IDE or text editor, or even in business intelligence (BI).
Advanced Find/Replace
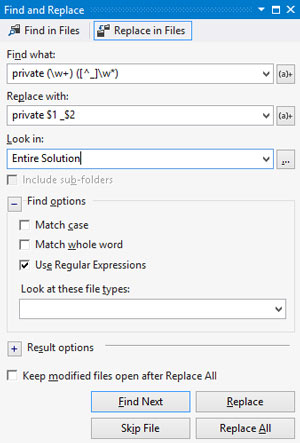
One often overlooked use of regular expressions is in the Find window of your IDE. Let's say for example you had Visual Studio open and were tasked with ensuring all private fields in some C# code were prefixed with an underscore. You could find all private fields NOT prefixed by an underscore by searching for:
private (\w+) ([^_]\w*)
This pattern reads as "the word private, followed by a space, followed by one or more word characters, followed by a space, followed by any character that is not an underscore, followed by zero or more word characters."
To then add the underscore to each of those instances, set the replacement string to:
private $1 _$2
This will replace any matches with the word private, followed by a space, followed by the first capture (the type of variable), followed by a space, then an underscore, and finally the second capture (the original variable name). To see what this looks like in the Visual Studio Find and Replace window, see Figure 1. Don't forget to make sure you check the box for Use Regular Expressions.
 [Click on image for larger view.]
Figure 1. The Visual Studio Find and Replace Window
[Click on image for larger view.]
Figure 1. The Visual Studio Find and Replace Window
Other Uses
Another area in which regular expressions can come in handy is in simple BI. One of my clients regularly asks me to pull data from various sources, do some aggregation and put it into a spreadsheet. In doing this, I've seen a multitude of data sources: HTML, documents using custom markup languages, social network feeds, and even a zip file full of unrelated text files. And while many tools exist for parsing specific things such as HTML or XML, I usually turn to using regular expressions first, before switching to a more specific tool if necessary.
I generally use a free tool called Expresso, which allows me to quickly build the expression I'll use for parsing.
A Fictional Requirement
To show an example of using regular expressions in BI, I'll begin with the following requirement: Convert the list of the top 250 movies on IMDB into a spreadsheet, with columns for the name of the movie, the year it was released, the IMDB rating and a link to the movie page. A simple enough requirement, but simply copying the table into Microsoft Excel isn't enough.
Please note the page I used at the time of this writing is located here, but due to the nature of the Internet, it may have changed by the time you read this. If you're trying to follow along but can't, try the code download accompanying this article. It contains an HTML file that will work with the sample RegEx patterns provided later.
The first step in getting the data is to get something to feed into the RegEx engine, which in this case will be the HTML source of the page. When on the page, your browser should have an option to view the source (typically you can right-click on the page and choose the View Source option, but this may vary based on your browser).
Next, copy the HTML and paste it into the Expresso Sample Text pane (under the Test Mode tab). Your screen should resemble Figure 2.
 [Click on image for larger view.]
Figure 2. Pasting the HTML into the Expresso Sample Text Pane
[Click on image for larger view.]
Figure 2. Pasting the HTML into the Expresso Sample Text Pane
Once the raw HTML is in Expresso, find the block of data you're targeting. For my example, I'll use the Find function in Expresso to search for "Shawshank Redemption," one of the movies in the list. Now look around for the other data points you want to capture. Next, copy the whole block into Notepad, allowing easy reference as you write the RegEx pattern. The text I've copied out is shown in Figure 3.
 [Click on image for larger view.]
Figure 3. Copying Code into Notepad
[Click on image for larger view.]
Figure 3. Copying Code into Notepad
Once you have that, you're ready to begin writing the pattern. I usually start by writing a pattern to match the piece of data with the most specific text surrounding it, but it doesn't really matter where you start, as the end result will be the same. For this example I started with the following pattern:
<a href="(?<RelativeUrl>[^"]*)".*?</a>
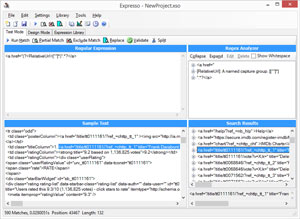
It will find every occurrence of the "a" tag with href as the first attribute. It will then use a named capturing group to capture the relative URL from within the quotation marks. Then it will continue to consume any characters it finds until reaching a closing anchor tag. When running the pattern, notice there are more matches than expected (see Figure 4, where 590 matches returned instead of the expected 250). This is OK, because as the pattern grows and becomes more specific, most if not all false positives will be eliminated. In fact, upon seeing the results, notice the movies have the ranking just before the beginning of the "a" tag, so to capture it you have to expand the pattern:
(?<Rank>\d+)\.\s<a href="(?<RelativeUrl>[^"]*)".*?</a>
 [Click on image for larger view.]
Figure 4. An Unexpected Number of Matches
[Click on image for larger view.]
Figure 4. An Unexpected Number of Matches
With this pattern, the number of matches is 250, exactly as expected. In the Search Results pane you can also expand the matches out to start seeing the data being parsed out, like in Figure 5. Repeat this process, each time building more and more onto the expression, then running it to see the results. The next iteration captures the movie title with this pattern:
(?<Rank>\d+)\.\s<a href="(?<RelativeUrl>[^"]*)"[^>]*>(?<Title>[^<]*)</a>
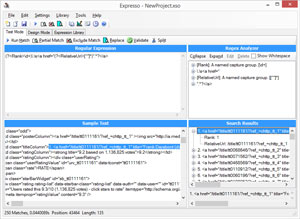 [Click on image for larger view.]
Figure 5. The Data Being Correctly Parsed
[Click on image for larger view.]
Figure 5. The Data Being Correctly Parsed
The release year can be captured with this one (see Figure 6):
(?<Rank>\d+)\.\s<a href="(?<RelativeUrl>[^"]*)"[^>]*>(?<Title>[^<]*)</a>.*?\((?<Year>\d{4})\)
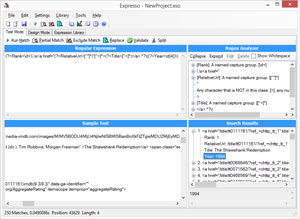 [Click on image for larger view.]
Figure 6. Capturing the Release Year
[Click on image for larger view.]
Figure 6. Capturing the Release Year
As you can see, there's heavy use of [^>]*> and [^<]*<, which tell the RegEx engine to consume every non-bracket character up to the first bracket character it comes across. This is an effective way to deal with HTML. It works in most cases when I know the HTML is well formed, and is more reliable than using pure wildcard searches, which can end up consuming a lot more than expected.
The final requirement is to get the rating, using this pattern:
(?<Rank>\d+)\.\s<a href="(?<RelativeUrl>[^"]*)"[^>]*>(?<Title>[^<]*)</a>.*?\((?<Year>\d{4})\).*?(?<Rating>\d\.\d)
But by default, that pattern won't work. The rating is on the next line, and the period can't consume line break characters unless a special flag, "Singleline," is set. To set that flag in Expresso, go to the Design Mode tab; at the very bottom are a number of checkboxes. Check the box for Singleline (see Figure 7) and run the expression again. Now it should work, resulting in 250 matches as expected, as shown in Figure 8.
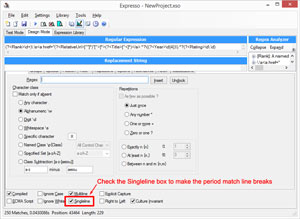 [Click on image for larger view.]
Figure 7. Setting the Singleline Flag
[Click on image for larger view.]
Figure 7. Setting the Singleline Flag
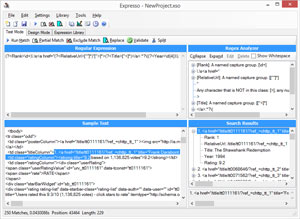 [Click on image for larger view.]
Figure 8. The Correct Number of Matches (250)
[Click on image for larger view.]
Figure 8. The Correct Number of Matches (250)
Turning the Data into Information
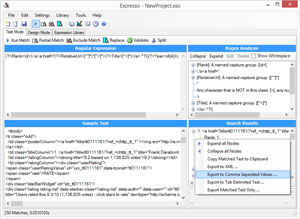
Now that the pattern's written and the data being extracted, the next step is to get it into a usable format for manipulation. I usually prefer to export it to CSV format, which can be done by first right-clicking inside the Search Results pane and selecting the Export to Comma Separated Values option (see Figure 9). You can then open this in something like Microsoft Excel, where you can aggregate or otherwise manipulate the extracted information.
 [Click on image for larger view.]
Figure 9. Exporting to Comma-Separated Values
[Click on image for larger view.]
Figure 9. Exporting to Comma-Separated Values
Going Further
As you can see, regular expressions can be used in many scenarios where a pattern needs to be checked for, and optionally some data extracted or modified. Regular expressions aren't a silver bullet, though, and aren't appropriate for every possible situation. In this article, I've shown you an example of how to extract some data from an HTML page, but full and accurate parsing of HTML isn't possible using only regular expressions. If you need to parse HTML beyond simple data extraction, I urge you to check out some purpose-built HTML parsers.
In the end, regular expressions are just another tool in your tool belt, and if used effectively they can provide immense value to the businesses you support. If you're ready to get serious about learning regular expressions, I highly recommend "Mastering Regular Expressions" (O'Reilly Media, 2006).
About the Author
Ondrej Balas owns UseTech Design, a Michigan development company focused on .NET and Microsoft technologies. Ondrej is a Microsoft MVP in Visual Studio and Development Technologies and an active contributor to the Michigan software development community. He works across many industries -- finance, healthcare, manufacturing, and logistics -- and has expertise with large data sets, algorithm design, distributed architecture, and software development practices.