In-Depth
Deploying Microservices Architecture with C#, Part 2
Now that we've got the basics of microservices, what happens when we take into production? It's time to make sure your message reaches its intended targets.
Everything looks good so far in the microservice we set up in Part 1, but what happens when we release this to production, and our application is consumed by multiple customers? Routing problems and message-correlation issues begin to rear their ugly heads. Our current example is simplistic. Consider a deployed application that performs work that is much more complex than our example.
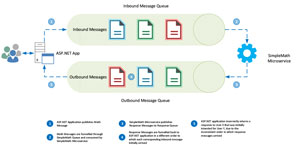
Now we are faced with a problem: how to ensure that any given message is received by its intended recipient only. Consider the process flow in Figure 1.
 [Click on image for larger view.]
Figure 1: Inconsistent Order of Response Messages Might Mean User X Gets User Y's Messages
[Click on image for larger view.]
Figure 1: Inconsistent Order of Response Messages Might Mean User X Gets User Y's Messages
It is possible that outbound messages published from the SimpleMath microservice may not arrive at the ASP.NET application in the same order in which the ASP.NET application initially published the corresponding request to the SimpleMath microservice.
RabbitMQ has built-in safeguards against this scenario in the form of Correlation IDs. A Correlation ID is essentially a unique value assigned by the ASP.NET application to inbound messages, and retained throughout the entire process flow. Once processed by the SimpleMath microservice, the Correlation ID is inserted into the associated response message, and published to the response Queue.
Upon receipt of any given message, the ASP.NET inspects the message contents, extracts the Correlation ID and compares it to the original Correlation ID. See Listing 1.
Listing 1: Comparing Correlation IDs
Message message = new Message();
message.CorrelationID = new CorrelationID();
RabbitMQAdapter.Instance.Publish(message.ToJson(), "MathInbound");
string response;
BasicDeliverEventArgs args;
var responded = RabbitMQAdapter.Instance.TryGetNextMessage("MathOutbound", out response, out args, 5000);
if (responded) {
Message m = Parse(response);
if (m.CorrelationID == message.CorrelationID) {
// This message is the intended response associated with the original request
}
else {
// This message is not the intended response, and is associated with a different request
// todo: Put this message back in the Queue so that its intended recipient may receive it...
}
}
throw new HttpResponseException(HttpStatusCode.BadGateway);
What's wrong with this solution?
It's possible that any given message may be bounced around indefinitely, without ever reaching its intended recipient. Such a scenario is unlikely, but possible. Regardless, it is likely, given multiple microservices, that messages will regularly be consumed by microservices to whom the message was not intended to be delivered. This is an obvious inefficiency, and very difficult to control from a performance perspective, and impossible to predict in terms of scaling.
But this is the generally accepted solution. What else can we do?
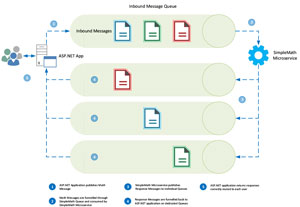
An alternative -- but discouraged -- solution is to invoke a dedicated Queue for each request, as shown in the process flow in Figure 2.
 [Click on image for larger view.]
Figure 2: Invoking a Dedicated Queue For Each Request
[Click on image for larger view.]
Figure 2: Invoking a Dedicated Queue For Each Request
Whoa! Are you suggesting that we create a new queue for each request?!?
Yes, so let's park that idea right there -- it's essentially a solution that won't scale. We would place an unnecessary amount of pressure on RabbitMQ in order to fulfil this design. One new Queue for every inbound HTTP request is simply unmanageable.
Or is it?
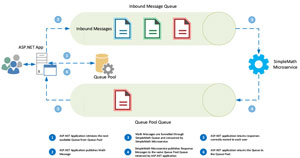
So, what if we could manage this? Imagine a dedicated pool of queues, made available to inbound requests, such that each Queue was returned to the pool upon request completion. This might sound far fetched, but this is essentially the way that database connection-pooling works. Figure 3 shows the new flow.
 [Click on image for larger view.]
Figure 3: A Dedicated Pool of Queues Available to Inbound Requests
[Click on image for larger view.]
Figure 3: A Dedicated Pool of Queues Available to Inbound Requests
Let's walk through the code in Listing 2, starting with the QueuePool itself.
Listing 2: QueuePool Class
public class QueuePool {
private static readonly QueuePool _instance = new QueuePool(
() => new RabbitMQQueue {
Name = Guid.NewGuid().ToString(),
IsNew = true
});
private readonly Func<AMQPQueue> _amqpQueueGenerator;
private readonly ConcurrentBag<AMQPQueue> _amqpQueues;
static QueuePool() {}
public static QueuePool Instance { get { return _instance; } }
private QueuePool(Func<AMQPQueue> amqpQueueGenerator) {
_amqpQueueGenerator = amqpQueueGenerator;
_amqpQueues = new ConcurrentBag<AMQPQueue>();
var manager = new RabbitMQQueueMetricsManager(false, "localhost", 15672, "paul", "password");
var queueMetrics = manager.GetAMQPQueueMetrics();
foreach (var queueMetric in queueMetrics.Values) {
Guid queueName;
var isGuid = Guid.TryParse(queueMetric.QueueName, out queueName);
if (isGuid) {
_amqpQueues.Add(new RabbitMQQueue {IsNew = false, Name = queueName.ToString()});
}
}
}
public AMQPQueue Get() {
AMQPQueue queue;
var queueIsAvailable = _amqpQueues.TryTake(out queue);
return queueIsAvailable ? queue : _amqpQueueGenerator();
}
public void Put(AMQPQueue queue) {
_amqpQueues.Add(queue);
}
}
QueuePool is a static class that retains a reference to a synchronized collection of Queue objects. The most important aspect of this is that the collection is synchronized, and therefore thread-safe. Under the hood, incoming HTTP requests obtain mutually exclusive locks in order to extract a Queue from the collection. In other words, any given request that extracts a Queue is guaranteed to have exclusive access to that Queue.
Note the private constructor. Upon start-up (QueuePool will be initialized by the first inbound HTTP request) and will invoke a call to the RabbitMQ HTTP API, returning a list of all active Queues. You can mimic this call as follows:
curl -i -u guest:guest http://localhost:15672/api/queues
The list of returned Queue objects is filtered by name, such that only those Queues that are named in GUID-format are returned. QueuePool expects that all underlying Queues implement this convention in order to separate them from other Queues leveraged by the application.
Now we have a list of Queues that our QueuePool can distribute. Let's take a look at our updated Math Controller, shown in Listing 3.
Listing 3: Updated Math Controller
var queue = QueuePool.Instance.Get();
RabbitMQAdapter.Instance.Publish(string.Concat(number, ",", queue.Name), "Math");
string message;
BasicDeliverEventArgs args;
var responded = RabbitMQAdapter.Instance.TryGetNextMessage(queue.Name, out message, out args, 5000);
QueuePool.Instance.Put(queue);
if (responded) {
return message;
}
throw new HttpResponseException(HttpStatusCode.BadGateway);
Let's step through what's the application is doing here:
- Returns exclusive use of the next available Queue from the QueuePool
-
Publishes the numeric input (as before) to SimpleMath Microservice, along with the Queue-name
-
Subscribes to the Queue retrieved from QueuePool, awaiting inbound messages
-
Receives the response from SimpleMath Microservice, which published to the Queue specified in step 2
-
Releases the Queue, which is reinserted into QueuePool's underlying collection
Notice the Get method. An attempt is made to retrieve the next available Queue. If all Queues are currently in use, QueuePool will create a new Queue.
Leveraging QueuePool offers greater reliability in terms of message delivery, as well as consistent throughput speeds, given that we no longer need rely on consuming components to re-queue messages that were intended for other consumers.
It offers a degree of predictable scale -– performance testing will reveal the optimal number of Queues that the QueuePool should retain in order to achieve sufficient response times.
It is advisable to determine the optimal number of Queues required by your application, so that QueuePool can avoid creating new Queues in the event of pool-exhaustion, reducing overhead.
Queue Pool Sizing
Queue-pooling is a feature of the Daishi.AMQP library that allows AMQP Queues to be shared among clients in a concurrent capacity, such that each Queue will have 0...1 consumers only. The concept is not unlike database connection-pooling.
We've built a small application that leverages a simple downstream Microservice, implements the AMQP protocol over RabbitMQ, and operates a QueuePool mechanism. We have seen how the QueuePool can retrieve the next available Queue:
var queue = QueuePool.Instance.Get();
and how Queues can be returned to the QueuePool:
QueuePool.Instance.Put(queue);
We have also considered the QueuePool default Constructor, how it leverages the RabbitMQ Management API to return a list of relevant Queues, as shown in Listing 4.
Listing 4: QueuePool Constructor
private QueuePool(Func<AMQPQueue> amqpQueueGenerator) {
_amqpQueueGenerator = amqpQueueGenerator;
_amqpQueues = new ConcurrentBag<AMQPQueue>();
var manager = new RabbitMQQueueMetricsManager(false, "localhost", 15672, "paul", "password");
var queueMetrics = manager.GetAMQPQueueMetrics();
foreach (var queueMetric in queueMetrics.Values) {
Guid queueName;
var isGuid = Guid.TryParse(queueMetric.QueueName, out queueName);
if (isGuid) {
_amqpQueues.Add(new RabbitMQQueue {IsNew = false, Name = queueName.ToString()});
}
}
}
Notice the high-order function in the above constructor. In the QueuePool static Constructor we define this function as shown here:
private static readonly QueuePool _instance = new QueuePool(
() => new RabbitMQQueue {
Name = Guid.NewGuid().ToString(),
IsNew = true
});
This function will be invoked if the QueuePool is exhausted, and there are no available Queues. It is a simple function that creates a new RabbitMQQueue object. The Daishi.AMQP library will ensure that this Queue is created (if it does not already exist) when referenced.
Exhaustion is Expensive
QueuePool exhaustion is something that we need to avoid. If our application frequently consumes all available Queues, then the QueuePool will become ineffective. Let's look at how we go about avoiding this scenario.
First, we need some targets. We need to know how much traffic our application will absorb in order to adequately size our resources. For argument's sake, let's assume that MathController will be subjected to 100,000 inbound HTTP requests, delivered in batches of 10. In other words, at any given time, MathController will service 10 simultaneous requests, and will continue doing so until 100,000 requests have been served.
Stress Testing Using Apache Bench
Apache Bench is a very simple, lightweight tool designed to test Web-based applications, and is bundled as part of the Apache Framework. Click http://stackoverflow.com/questions/4314827/is-there-any-link-to-download-ab-apache-benchmark here for simple download instructions. Assuming that our application runs on port 46653, here is the appropriate Apache Bench command to invoke 100 MathController HTTP requests in batches of 10:
ab -n 100 -c 10 http://localhost:46653/api/math/150
Notice the "n" and "c" paramters; "n" refers to "number", as in the number of requests, and "c" refers to "concurrency", or the amount of requests to run in simultanously. Running this command will yield something along the lines of the following:
C:\>ab -n 100 -c 10 http://localhost:46653/api/math/150
This is ApacheBench, Version 2.3 <$Revision: 1638069 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient).....done
Server Software: Microsoft-IIS/10.0
Server Hostname: localhost
Server Port: 46653
Document Path: /api/math/150
Document Length: 5 bytes
Concurrency Level: 10
Time taken for tests: 7.537 seconds
Complete requests: 100
Failed requests: 0
Total transferred: 39500 bytes
HTML transferred: 500 bytes
Requests per second: 13.27 [#/sec] (mean)
Time per request: 753.675 [ms] (mean)
Time per request: 75.368 [ms] (mean, across all concurrent requests)
Transfer rate: 5.12 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.4 0 1
Processing: 41 751 992.5 67 3063
Waiting: 41 751 992.5 67 3063
Total: 42 752 992.4 67 3063
Percentage of the requests served within a certain time (ms)
50% 67
66% 1024
75% 1091
80% 1992
90% 2140
95% 3058
98% 3061
99% 3063
100% 3063 (longest request)
Those results don't look great. Incidentally, if you would like more information as regards how to interpret Apache Bench results, click http://stash.ryanair.com:7990/projects/PAPI/repos/payment-api-v2/browse here. Let's focus on the final section, "Percentage of the requests served within a certain time (ms)". Here we see that 75 percent of all requests took just over one second (1,091 milliseconds) to complete. Ten percent took over two seconds, and five percent took over three seconds to complete. That's quite a long time for such a simple operation running on a local server. Let's run the same command again:
C:\>ab -n 100 -c 10 http://localhost:46653/api/math/100
This is ApacheBench, Version 2.3 <$Revision: 1638069 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient).....done
Server Software: Microsoft-IIS/10.0
Server Hostname: localhost
Server Port: 46653
Document Path: /api/math/100
Document Length: 5 bytes
Concurrency Level: 10
Time taken for tests: 0.562 seconds
Complete requests: 100
Failed requests: 0
Total transferred: 39500 bytes
HTML transferred: 500 bytes
Requests per second: 177.94 [#/sec] (mean)
Time per request: 56.200 [ms] (mean)
Time per request: 5.620 [ms] (mean, across all concurrent requests)
Transfer rate: 68.64 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.4 0 1
Processing: 29 54 11.9 49 101
Waiting: 29 53 11.9 49 101
Total: 29 54 11.9 49 101
Percentage of the requests served within a certain time (ms)
50% 49
66% 54
75% 57
80% 60
90% 73
95% 80
98% 94
99% 101
100% 101 (longest request)
OK, those results look a lot better. Even the longest request took 101 milliseconds, and 80 percent of all requests completed in less than 60 milliseconds.
But where does this discrepancy come from? Remember, that on start-up there are no QueuePool Queues. The QueuePool is empty and does not have any resources to distribute. Therefore, inbound requests force QueuePool to create a new Queue in order to facilitate the request, and then reclaim that Queue when the request has completed.
Does this mean that when I deploy my application, the first batch of requests are going to run much more slowly than subsequent requests?
No, and that's where sizing comes in. As with all performance testing, the objective is to set a benchmark in terms of the expected volume that an application will absorb, and to determine that maximum impact that it can withstand, in terms of traffic. In order to sufficiently bootstrap QueuePool, so that it contains an adequate number of dispensable Queues, we can simply include ASP.NET controllers that leverage QueuePool in our performance run.
Suppose that we expect to handle 100 concurrent users over extended periods of time. Let's run an Apache Bench command again, setting the level of concurrency to 100, with a suitably high number of requests in order to sustain that volume over a reasonably long period of time:
ab -n 1000 -c 100 http://localhost:46653/api/math/100
Percentage of the requests served within a certain time (ms)
50% 861
66% 938
75% 9560
80% 20802
90% 32949
95% 34748
98% 39756
99% 41071
100% 42163 (longest request)
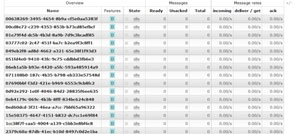
Again, very poor, but expected results. More interesting is the number of Queues now active in RabbitMQ (see Figure 4).
 [Click on image for larger view.]
Figure 4: Queues Now Active in RabbitMQ
[Click on image for larger view.]
Figure 4: Queues Now Active in RabbitMQ
In my own environment, QueuePool created 100 Queues in order to facilitate all inbound requests. Let's run the test again, and consider the results:
Percentage of the requests served within a certain time (ms)
50% 497
66% 540
75% 575
80% 591
90% 663
95% 689
98% 767
99% 816
100% 894 (longest request)
These results are much more respectable. Again, the discrepancy between performance runs is due to the fact that QueuePool was not adequately initialized during the first run. However, QueuePool was initialized with 100 Queues, a volume sufficient to facilitate the volume of request that the application is expected to serve.
This is simple an example as possible. Real-world performance testing entails a lot more than simply executing isolated commands against single endpoints; however the principal remains the same. We have effectively determined the optimal size necessary for QueuePool to operate efficiently, and can now size it accordingly on application start-up, ensuring that all inbound requests are served quickly and without bias.
Those already versed in the area of microservices might object at this point. There is only a single instance of our microservice, SimpleMathMicroservice, running. One of the fundamental concepts behind microservice design is scalability. Next time, I'll cover auto scaling, and we'll drive those performance response times into the floor.