News
C# Makes GitHub's Top 5 Machine Learning Languages List
Although Python is the widely recognized de facto, go-to programming language for machine learning and many other artificial intelligence projects, a new study shows C# is holding its own in the space.
GitHub mined its extensive internal data to publish a report on all things related to machine learning in its software development platform/open source code repository.
The data-based treatise builds on the huge State of the Octoverse 2018 report published last October by the open source champion now owned by Microsoft. The GitHub community consists of more than 31 million developers and more than 2.1 million organizations, hosting more than 96 million repositories.
Yesterday, the company published The State of the Octoverse: Machine Learning, which noted the popularity of machine learning/data science projects in the big October report that prompted the company to explore that topic in greater detail.
As is typical, the exercise starts with a topic dear to all developers: programming languages.
"We looked at contributors to repositories tagged with the 'machine-learning' topic, and ranked the most common primary languages of the repositories," the post said. "Python is the most common language among machine learning repositories and is the third most common language on GitHub overall. "
"However, not all machine learning happens in Python: some of the most common languages on GitHub are also common languages for machine learning projects. C++, JavaScript, Java, C#, Shell, and TypeScript are all in the top 10 languages on GitHub and the top 10 for machine learning projects."
The top machine learning languages on GitHub include:
- Python
- C++
- JavaScript
- Java
- C#
- Julia
- Shell
- R
- TypeScript
- Scala
Commenting further on that list, the company said, "Julia, R, and Scala all appear in the top 10 for machine learning projects but not for GitHub overall. Julia and R are both languages commonly used by data scientists, and Scala is becoming increasingly common when interacting with Big Data systems like Apache Spark."
The above list doesn't look too different from the company's chart of top programming languages used overall over time:
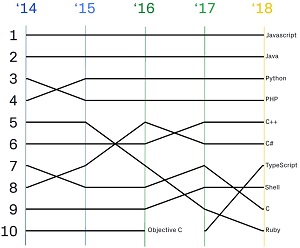 [Click on image for larger view.] Top Programming Languages Used over Time (source: GitHub).
[Click on image for larger view.] Top Programming Languages Used over Time (source: GitHub).
Yesterday's post also explored the top machine learning projects, resulting in this list:
- tensorflow/tensorflow
- scikit-learn/scikit-learn
- explosion/spaCy
- JuliaLang/julia
- CMU-Perceptual-Computing-Lab/openpose
- tensorflow/serving
- thtrieu/darkflow
- ageitgey/face_recognition
- RasaHQ/rasa_nlu
- tesseract-ocr/tesseract
The No. 1 project, tensorflow/tensorflow, was the No. 3 overall project as listed in the main Octoverse study, behind Microsoft/vscode and facebook/react-native.
 [Click on image for larger view.] Top Machine Learning/Data Science Packages (source: GitHub).
[Click on image for larger view.] Top Machine Learning/Data Science Packages (source: GitHub).
GitHub also charted the top packages imported by machine learning projects, resulting in the graphic above, for which it provided the following explanation:
- Numpy -- a package with support for mathematical operations on multidimensional data -- was the most imported package, used in nearly three-quarters of machine learning and data science projects.
- Scipy, a package for scientific computation, pandas, a package for managing datasets, and matplotlib, a visualization library, are all used in over 40 percent of machine learning and data science projects.
- Scikit-learn is a popular machine learning package, containing implementations of a large number of machine learning algorithms -- it's used by nearly 40 percent of projects.
- Tensorflow, a package for working with neural nets, is used in nearly a quarter of packages.
"The rest of the top 10 are utility packages: six is a Python 2 and 3 compatibility library, and python-dateutil and pytz are packages for working with dates," the post said.
Data backing the report came from contributions between Jan. 1, 2018, and Dec. 31, 2018. Types of contributions include pushing code, opening an issue or pull request, commenting on an issue or pull request, or reviewing a pull request, GitHub said. "For the most imported packages, we used data from the dependency graph, which includes all public repositories and any private repositories that have opted in to the dependency graph."
About the Author
David Ramel is an editor and writer at Converge 360.