News
.NET for Apache Spark Debuts in Version 1.0
The open source project .NET for Apache Spark has debuted in version 1.0, finally vaulting the C# and F# programming languages into Big Data first-class citizenship.
Spearheaded by Microsoft and the .NET Foundation, the package -- some two years in the making -- finally introduces .NET into the Big Data mix with a foothold provided by Apache Spark, one of the most popular open source projects of all time. After Big Data arrived upon the scene years ago with the promise of providing data-driven business insights to organizations, Apache Spark soon arrived to get all the pieces moving together with a unified analytics engine for Big Data processing via ready-made components for streaming, SQL, machine learning and graph processing.
With Microsoft extending C#/F# use cases from beyond the desktop to web, mobile, cloud and elsewhere, Big Data is just the latest outreach effort.
.NET for Apache Spark broke onto the scene last year, building upon the existing scheme that allowed for .NET to be used in Big Data projects via the precursor Mobius project and C# and F# language bindings and extensions used to leverage an interop layer with APIs for programming languages like Java, Python, Scala and R.
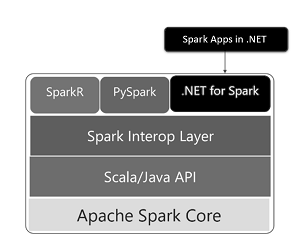 [Click on image for larger view.] .NET for Apache Spark Architecture (source: Microsoft).
[Click on image for larger view.] .NET for Apache Spark Architecture (source: Microsoft).
The v1.0 project now provides high-performance APIs for using Spark from C# and F# to access:
- DataFrame and SparkSQL for working with structured data.
- Spark Structured Streaming for working with streaming data.
- Spark SQL for writing queries with SQL syntax.
- Machine learning integration for faster training and prediction (that is, use .NET for Apache Spark alongside ML.NET).
"Version 1.0 includes support for .NET applications targeting .NET Standard 2.0 or later. Access to the Apache Spark DataFrame APIs (versions 2.3, 2.4 and 3.0) and the ability to write Spark SQL and create user-defined functions (UDFs) are also included in the release," an announcement post said.
Along with that expanded functionality, performance hasn't suffered, as Microsoft said programs that don't use user-defined functions (UDFs) are just as fast as Scala and PySpark-based non-UDF Spark applications, while applications including UDFs are at least as fast as PySpark programs and often faster.
A blog post provides the historical background for the project:
"About two years ago, we heard an increasing demand from the .NET community for an easier way to build big data applications with .NET instead of having to learn Scala or Python. Thus, we built a team based on members from the Azure Data engineering team (including members of the previous Mobius team) and members from the .NET team and started the
.NET for Apache Spark open-source project. While we operate the project under the
.NET Foundation, we did file Spark Project Improvement Proposals (SPIPs)
SPARK-26257 and
SPARK-27006 to have the work included in the Apache Spark project directly, if the community decides that is the right way to move forward.
"We announced the first public version in April 2019 during the
Databricks Spark+AI Summit 2019 and at
Microsoft Build 2019, and since then have regularly released updates to the package. In fact we have shipped 12 pre-releases, included 318 pull requests by the time of version 1.0, addressed 286 issues filed on GitHub, included it in several of our own Spark offerings (Azure HDInsight and Azure Synapse Analytics) as well as integrated it with the .NET Interactive notebook experiences."
Microsoft said it conducted a survey about .NET developers and Big Data that found:
- Most .NET developers want to use languages they are familiar with like C# and F# to build big data projects.
- Support for features like Language Integrated Query (LINQ) is important.
- The largest obstacles faced include setting up prerequisites and dependencies and finding quality documentation.
- A top priority is supporting deployment options, including integration with CI/CD DevOps pipelines and publishing or submitting jobs directly from Visual Studio.
Regarding the latter item, the project's roadmap shows tooling improvements underway to make it easier to copy and paste Scala examples into Visual Studio, along with Visual Studio extensions for submitting an app to a remote Spark cluster and for .NET app debugging.
To address other concerns, Microsoft and project stewards have created community-contributed "ready-to-run" Docker images and sparked a recent wave of updates to the .NET for Spark documentation.
"We are continuously updating the project to keep pace with .NET developments, Spark releases, and feature requests such as GroupMap," the company said.
About the Author
David Ramel is an editor and writer at Converge 360.