The Data Science Lab
How to Create a Transformer Architecture Model for Natural Language Processing
The goal is to create a model that accepts a sequence of words such as "The man ran through the {blank} door" and then predicts most-likely words to fill in the blank.
This article explains how to create a transformer architecture model for natural language processing. Specifically, the goal is to create a model that accepts a sequence of words such as "The man ran through the {blank} door" and then predicts most-likely words to fill in the blank.
Transformer architecture (TA) models such as BERT (bidirectional encoder representations from transformers) and GPT (generative pretrained transformer) have revolutionized natural language processing (NLP). But TA systems are extremely complex, and implementing them from scratch can take hundreds or thousands of man-hours. The Hugging Face (HF) library is open source code that has pretrained TA models and an API set for working with the models. The HF library makes implementing NLP systems using TA models much less difficult.
A good way to see where this article is headed is to take a look at the screenshot of a demo program in Figure 1. The demo program is an example of "fill-in-the-blank." The source sentence is "The man ran through the {blank} door" and the goal is to determine reasonable words for the {blank}.
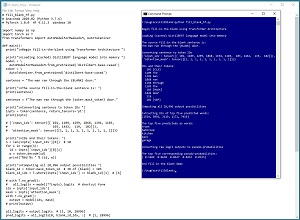 [Click on image for larger view.] Figure 1: Fill-in-the-Blank Using the Hugging Face Code Library
[Click on image for larger view.] Figure 1: Fill-in-the-Blank Using the Hugging Face Code Library
The demo program begins by loading a pretrained DistilBERT language model into memory. DistilBERT is a condensed version of the huge BERT language model. The source sentence is passed to a Tokenizer object which breaks the sentence into words/tokens and assigns an integer ID to each token. For example, one of the tokens is "man" and its ID is 1299, and the token that represents the blank-word is [MASK] and its ID is 103.
The token IDs are passed to the DistilBERT model and the model computes the likelihoods of 28,996 possible words/tokens to fill in the blank. The top five candidates to fill in the blank for "The man ran through the {blank} door" are: "front," "bathroom," "kitchen," "back" and "garage."
This article assumes you have an intermediate or better familiarity with a C-family programming language, preferably Python, and basic familiarity with PyTorch, but does not assume you know anything about the Hugging Face code library. The complete source code for the demo program is presented in this article, and the code is also available in the accompanying file download.
To run the demo program, you must have Python, PyTorch and HF installed on your machine. The demo programs were developed on Windows 10 using the Anaconda 2020.02 64-bit distribution (which contains Python 3.7.6) and PyTorch version 1.8.0 for CPU installed via pip and HF transformers version 4.11.3. Installation is not trivial. You can find detailed step-by-step installation instructions for PyTorch in my blog post. Installing the HF transformers library is relatively simple. You can issue the shell command "pip install transformers."
The Fill-in-the-Blank Demo
The complete demo program code, with a few minor edits to save space, is presented in Listing 1. I indent using two spaces rather than the standard four spaces. The backslash character is used for line continuation to break down long statements.
The demo program imports three libraries:
import numpy as np
import torch as T
from transformers import AutoModelForMaskedLM, AutoTokenizer
The Hugging Face transformers library (transformers) can work with either the PyTorch (torch) or TensorFlow deep neural libraries. The demo uses PyTorch. Technically, the NumPy library is not required to use HF transformers, but in practice most programs will use NumPy.
Listing 1: The Fill-in-the-Blank Demo Program
# fill_blank_hf.py
# Anaconda 2020.02 (Python 3.7.6)
# PyTorch 1.8.0 HF 4.11.3 Windows 10
import numpy as np
import torch as T
from transformers import AutoModelForMaskedLM, AutoTokenizer
def main():
print("\nBegin fill--blank using Transformer Architecture ")
print("\nLoading DistilBERT language model into memory ")
model = \
AutoModelForMaskedLM.from_pretrained('distilbert-base-cased')
toker = \
AutoTokenizer.from_pretrained('distilbert-base-cased')
sentence = "The man ran through the {BLANK} door."
print("\nThe source fill-in-the-blank sentence is: ")
print(sentence)
sentence = f"The man ran through the {toker.mask_token} door."
print("\nConverting sentence to token IDs ")
inpts = toker(sentence, return_tensors='pt')
# inpts = toker(sentence, return_tensors=None)
print(inpts)
# {'input_ids': tensor([[ 101, 1109, 1299, 1868, 1194, 1103,
# 103, 1442, 119, 102]]),
# 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
print("\nIDs and their tokens: ")
n = len(inpts['input_ids'][0]) # 10
for i in range(n):
id = inpts['input_ids'][0][i]
w = toker.decode(id)
print("%6d %s " % (id, w))
print("\nComputing all 28,996 output possibilities ")
blank_id = toker.mask_token_id # ID of {blank} = 103
blank_id_idx = T.where(inpts['input_ids'] == blank_id)[1]
# with T.no_grad():
# all_logits = model(**inpts).logits # shortcut form
ids = inpts['input_ids']
mask = inpts['attention_mask']
with T.no_grad():
output = model(ids, mask)
# print(output)
all_logits = output.logits # [1, 10, 28996]
pred_logits = all_logits[0, blank_id_idx, :] # [1, 28996]
print("\nExtracting IDs of top five predicted words: ")
top_ids = T.topk(pred_logits, 5, dim=1).indices[0].tolist()
print(top_ids)
print("\nThe top five predicteds as words: ")
for id in top_ids:
print(toker.decode([id]))
print("\nConverting logit outputs to pseudo-probabilities ")
np.set_printoptions(formatter={'float': '{: 0.4f}'.format})
pred_probs = T.softmax(pred_logits, dim=1).numpy()
pred_probs = np.sort(pred_probs[0])[::-1] # high p to low p
top_probs = pred_probs[0:5]
print("\nThe top five corresponding pseudo-probabilities: ")
print(top_probs)
# [0.1689 0.0630 0.0447 0.0432 0.0323]
print("\nEnd fill-in-the-blank demo ")
return # end-of-function main()
if __name__ == "__main__":
main()
The demo has a single main() function and no helper functions. The demo begins with:
def main():
print("Begin fill--blank using Transformer Architecture ")
print("Loading DistilBERT language model into memory ")
model = \
AutoModelForMaskedLM.from_pretrained('distilbert-base-cased')
toker = \
AutoTokenizer.from_pretrained('distilbert-base-cased')
. . .
The HF library has many different transformer architecture language models. The demo loads the distilbert-base-cased model (65 million weights) into memory. Examples of other models include bert-large-cased (335 million weights trained using Wikipedia articles and book texts), and gpt2-medium (345 million weights), The first time you run the program, the code will reach out using your Internet connection and download the model. On later program runs, the code will use the cached version of the model. On Windows systems the cached HF models are stored by default at C:\Users\(user)\.cache\huggingface\transformers.
In general, each HF model has its own associated tokenizer to break the source sequence text into tokens. This is different from earlier language systems that often use a generic tokenizer such as spaCy. Therefore, the demo loads the distilbert-base-cased tokenizer.
Tokenizing
Breaking an NLP source sentence/sequence into words/tokens is much trickier than you might expect if you're new to NLP. The demo sets up a source sequence of text and tokenizes it like so:
sentence = "The man ran through the {BLANK} door."
print("The source fill-in-the-blank sentence is: ")
print(sentence)
sentence = f"The man ran through the {toker.mask_token} door."
print("Converting sentence to token IDs ")
inpts = toker(sentence, return_tensors='pt')
print(inpts)
The "f" in front of the source string, combined with the {toker.mask_token} variable, is a relatively new (Python 3.6) "f-string" syntax for formatting strings. The source string is fed to the toker Tokenizer object along with a return_tensors='pt' argument. The 'pt' means return tokenized information as PyTorch tensors rather than the default NumPy arrays. The idea here is that the tokenized information will be fed to the DistilBERT model, which requires PyTorch tensors. So, if you omitted the return_tensors='pt' argument you'd have to convert the return results to PyTorch tensors later.
The return result from the toker method call is:
{'input_ids': tensor([[ 101, 1109, 1299, 1868,
1194, 1103, 103, 1442,
119, 102]]),
'attention_mask': tensor([[1, 1, 1, 1, 1,
1, 1, 1, 1, 1]])}
The input_ids field holds the integer IDs of each token. The attention_mask field tells the system which tokens to use (1) or ignore (0). In this example the demo uses all the tokens.
The demo shows how the source sequence of text was tokenized with these statements:
print("IDs and their tokens: ")
n = len(inpts['input_ids'][0]) # 10
for i in range(n):
id = inpts['input_ids'][0][i]
w = toker.decode(id)
print("%6d %s " % (id, w))
The for-loop iterates through each of the 10 token IDs and displays the associated word/token using the decode() method. The results are:
101 [CLS]
1109 The
1299 man
1868 ran
1194 through
1103 the
103 [MASK]
1442 door
119 .
102 [SEP]
The [CLS] token stands for "classifier" and is used internally. The [SEP] token stands for separator.
This example is slightly misleading because each word in the source sentence produces a single token. But tokenization doesn't always work that way. For example, if the source sequence is "The man floogled," the fake word "floogled" would be tokenized as:
1109 The
1299 man
22593 fl
5658 ##oo
8384 ##gled
The point is that in informal usage it's common to use terms such as source "sentence" and tokenized "words," but it's more accurate to use sequence (instead of sentence) and tokens (instead of words).
Feeding Tokens to the Model
The demo prepares to feed the tokenized source sentence to the model with these statements:
print("Computing all 28,996 output possibilities ")
blank_id = toker.mask_token_id # ID of {blank} = 103
blank_id_idx = T.where(inpts['input_ids'] == blank_id)[1] # [6]
Different tokenizers use different IDs for the {blank} token so the demo programmatically gets the ID rather than hard-coding with the statement blank_id = 103. The PyTorch where() function finds the index of a target value in an array. In this case the location of the {blank} token is at index [6]. That index will be needed to extract results.
The tokenized IDs and attention mask values are fed to the DistilBERT model like so:
ids = inpts['input_ids']
mask = inpts['attention_mask']
with T.no_grad():
output = model(ids, mask)
The no_grad() block is used so that the output results are not connected to the underlying PyTorch computational network that is the DistilBERT model. Instead of passing the tokenized IDs and attention mask tensors to the DistilBERT model, it's possible to pass them together and then fetch the output logits using this shortcut syntax:
with T.no_grad():
all_logits = model(**inpts).logits # shortcut form
The raw output logits results are fetched and then the logits of interest are extracted with these two statements:
all_logits = output.logits # [1, 10, 28996]
pred_logits = all_logits[0, blank_id_idx, :] # [1, 28996]
The output object that's returned by the model is:
MaskedLMOutput(loss=None,
logits=tensor([[[ -6.4189, . . -5.4534],
[ -7.3583, . . -6.3187],
[ -12.7053, . . -11.8682]]]),
hidden_states=None,
attentions=None)
For a fill-in-the-blank problem, the only field that's relevant is the logits information. The shape of the logits 3D tensor for the given input sequence is [1, 10, 28996]. The 28996 in third dimension represents each possible word/token to fill in the blank. The 10 in the second dimension represents each of the 10 input token IDs. The only one of those tensors that's needed is the one that predicts the associated [MASK] index at [6] stored in blank_id_idx so those values are extracted and stored into the pred_logits. Dealing with tricky indexing in multidimensional tensors is not conceptually difficult but it does take quite a bit of time.
Interpreting the Results
The pred_logits tensor holds 28,996 values. Each logit value represents the likelihood of a word to fill in the blank in the "The man ran through the {blank} door" sentence, and the index values 0, 1, 2, . . represent token IDs. Larger logit values are more likely. You could simply seek the largest logit value then get the index of its location for the most likely word/token. A better approach is to find the five most likely words/tokens. The demo uses the handy torch.topk() function to do this:
print("Extracting IDs of top five predicted words: ")
top_ids = T.topk(pred_logits, 5, dim=1).indices[0].tolist()
print(top_ids)
print("The top five predicteds as words: ")
for id in top_ids:
print(toker.decode([id]))
The 28,996 logit values are difficult to interpret so the demo program converts the logits to pseudo-probabilities using the softmax() function. These values sum to 1.0 so they loosely represent probabilities.
print("Converting raw logit outputs to pseudo-probabilities ")
np.set_printoptions(formatter={'float': '{: 0.4f}'.format})
pred_probs = T.softmax(pred_logits, dim=1).numpy()
pred_probs = np.sort(pred_probs[0])[::-1] # high p to low p
top_probs = pred_probs[0:5]
print("The top five corresponding pseudo-probabilities: ")
print(top_probs)
# [0.1689 0.0630 0.0447 0.0432 0.0323]
The pseudo-probabilities show that the most-likely word "front" (0.1689) is almost three times more likely than the second most likely word "bathroom" (0.0630). Words "kitchen," "back" and "garage" are about equally likely.
The pseudo-probability values are converted to NumPy values only because NumPy values are easier to format. In general, it's better to work with PyTorch tensors except when getting input and when producing final output. If you find yourself repeatedly converting back and forth between PyTorch tensors and NumPy arrays, you're likely writing inefficient and slow-to-run code.
Wrapping Up
One way to think about the fill-in-the-blank example presented in this article is that the DistilBERT model gives you an English language expert. You can ask this expert things such as what is the missing word in a sentence, or how similar two words are. But the DistilBERT expert doesn't have specific knowledge about anything beyond pure English. For example, the basic DistilBERT model doesn't know anything about movies. It is possible to start with a basic DistilBERT model and then fine-tune the model to give it knowledge about movie reviews in order to create a movie review expert. The fine-tuned expert will know about English and also about the difference between a good movie review and a bad review.
By the way, you are probably wondering about the rather odd "Hugging Face" name. I reached out to HF via email and they explained that, "In the early days the team was building an advanced chatbot. The founders wanted it to be friendly and fun so they named it after the hugging face emoji." Well, even if I'm not a big fan of the Hugging Face name, I am a big fan of the library itself.