News
Microsoft Ships ML.NET 2.0 and New Model Builder Version for Machine Learning
Microsoft updated its machine learning dev tooling with ML.NET 2.0 and a new version of Model Builder.
ML.NET is the company's open source, cross-platform machine learning framework for .NET developers that enables integration of custom machine learning models into .NET apps. Model Builder is a UI tool in Visual Studio that helps devs build, train and consume custom machine learning models in those apps.
Heading the highlights of ML.NET 2.0 are new APIs for working with text, specifically one that enables a new text classification scenario in Model Builder, along with a sentence similarity API.
The ML.NET 2.0 text classification API was part of the big debut of .NET 7 last week, adding state-of-the-art deep learning techniques for natural language processing. The API was introduced in preview in June, with the company listing these use cases:
- Categorizing e-mail as spam or not spam
- Analyzing sentiment as positive or negative from customer reviews
- Applying labels to support tickets
Last week, in announcing the updates, Microsoft said, "A few months ago we released a preview of the Text Classification API. As the name implies, this API enables you to train custom models that classify raw text data. It does so by integrating a TorchSharp implementation of NAS-BERT into ML.NET. Using a pre-trained version of this model, the Text Classification API uses your data to fine-tune the model.
 [Click on image for larger, animated GIF view.] Model Builder in Animated Action in Visual Studio (source: Microsoft).
[Click on image for larger, animated GIF view.] Model Builder in Animated Action in Visual Studio (source: Microsoft).
"Since then, we've been working on refining the API. Today we're excited to announce the Text Classification scenario in Model Builder powered by the ML.NET Text Classification API."
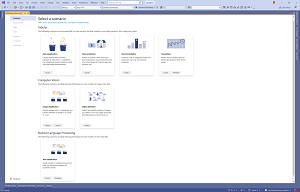 [Click on image for larger view.] Text Classification Scenario Added to Model Builder (source: Microsoft).
[Click on image for larger view.] Text Classification Scenario Added to Model Builder (source: Microsoft).
The new sentence similarity API, meanwhile, uses the same TorchSharp NAS-BERT model as underlying tech. However, instead of predicting a category, the model calculates a numerical value that represents how similar two phrases are.
The dev team also introduced tokenizer support, providing techniques key to enabling the above natural language processing scenarios.
Improvements were also made to the company's AutoML offering, which automates the process of applying machine learning to data. In ML.NET 2.0, developers can:
- Automate data preprocessing using the AutoML Featurizer.
- Train binary classification, multiclass classification, and regression models using preconfigured AutoML pipelines which make it easier to get started with machine learning.
- Choose which trainers are used as part of training process.
- Customize and create your own search space to choose hyperparameters from.
- Choose the tuning algorithms used to find the optimal hyperparamters.
- Persist all AutoML runs.
Going forward, Microsoft plans to improve deep learning functionality, LightGBM (a flexible framework for classical machine learning tasks such as classification and regression), DataFrame (data processing), AutoML and associated tooling, and documentation.
About the Author
David Ramel is an editor and writer at Converge 360.