Kotlin is a hot programming language right now, and its eclipse of Java for Android mobile development might leave Visual Studio developers wondering how they can get in on the action.
The already well-documented rise of Kotlin -- after being named a first-class language for Android by Google at its I/O conference in May -- is further chronicled in a new report from mobile database company Realm. Culling data from its large user base, Realm just today published its inaugural "Realm Report" to analyze choices developers make on programming tools, languages and platforms.
For languages, there's no doubt about which one has the momentum.
"It's clear: Java (on Android) is dying," the report said. "There aren't simply more Kotlin builders: they're also switching their apps to Kotlin. In fact, 20 percent of apps built with Java before Google I/O are now being built in Kotlin. Kotlin may even change how Java is used on the server, too.
"In short, Android developers without Kotlin skills are at risk of being seen as dinosaurs very soon."
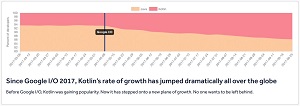 [Click on image for larger view.] Realm Says: 'Kotlin is about to change the whole Android ecosystem' (source: Realm).
[Click on image for larger view.] Realm Says: 'Kotlin is about to change the whole Android ecosystem' (source: Realm).
Google, in describing its views on "Kotlin and Android," has said this:
We have been watching Kotlin adoption on Android steadily rise over the years, with increasing excitement among developers. Kotlin is expressive, concise, extensible, powerful, and a joy to read and write. It has wonderful safety features in terms of nullability and immutability, which aligns with our investments to make Android apps healthy and performant by default. Best of all, it's interoperable with our existing Android languages and runtime. So we're thrilled to make Kotlin an official language on Android.
So what can Visual Studio developers do to avoid becoming dinosaurs -- or at least use Kotlin for Android programming? The answer is: not much.
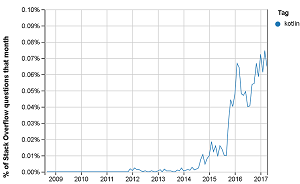 [Click on image for larger view.]
Kotlin Gains in Popularity (source: Stack Overflow Trends)
[Click on image for larger view.]
Kotlin Gains in Popularity (source: Stack Overflow Trends)
With Visual Studio, Android development is primarily done with C# via Xamarin, or with JavaScript via Cordova. The VS approach emphasizes cross-platform functionality, seeking to let coders create mobile apps for Android, iOS and Windows while using much of the same code base.
The truth is, even with Microsoft's transformation into a more open company that embraces alternative technologies, the Visual Studio ecosystem is just now catching up to Java, soon to be subsumed by Kotlin!
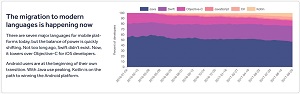 [Click on image for larger view.] What Languages Are Mobile Developers Using? (source: Realm).
[Click on image for larger view.] What Languages Are Mobile Developers Using? (source: Realm).
For example, last month, JNBridge -- which as its name suggests is a specialist in bridging the Java/.NET camps -- announced it will offer Java coding in the Visual Studio IDE with an upcoming Java.VS extension.
And on the Visual Studio Code editor side of things, the somewhat more robust Java offerings include the brand-new Java Debugger for Visual Studio Code.
In fact, the open source VS Code is obviously and logically the go-to choice for coding in other languages, including Kotlin.
But there isn't much in the Visual Studio Marketplace for Kotlin for VS Code.
Here's a look at the two main Kotlin offerings available for VS Code:
Kotlin Language
This extension comes from developer Mathias Fröhlich, providing Kotlin language support for VS Code -- basically a syntax highlighter for the Kotlin language. Fröhlich credits the open source Kotlin Sublime Text 2 Package, so his extension is likely based on that.
As of this writing, the extension has been installed in VS Code 20,475 times, being reviewed only once.
On the project's GitHub site, it has garnered 41 stars, with 17 commits coming from four contributors. It was last updated in July.
Code Runner
Coming from developer Jun Han, this tool isn't Kotlin-specific -- rather, it lets VS Code users run code snippets or code files coming in 35 different programming languages. Kotlin is the latest addition to that extensive list.
 [Click on image for larger animated GIF.]
Kotlin in Code Runner (source: Jun Han)
[Click on image for larger animated GIF.]
Kotlin in Code Runner (source: Jun Han)
Code Runner provides the following features:
- Run code file of current active Text Editor
- Run selected code snippet in Text Editor
- Run custom command
- Stop code running
- View output in Output Window
- Set default language to run
- Select language to run
- Support REPL by running code in Integrated Terminal
Code Runner's new support for Kotlin was announced in a blog post on the Microsoft developer site.
"In recent Google I/O 2017, Kotlin has been announced as the [actually, just "a"] official development language of Android by Google," says the post authored by "formulahendry." "And now, it's time to support Kotlin in Code Runner!
"Kotlin tools will be included with Android Studio 3.0 by default, and JetBrains and Google are pledging to support the language going forward. Kotlin as a language has a lot of similarities to Java in structure. Moreover, Kotlin adds a lot of nice-to-have features, a much cleaner syntax, ideas from functional programming, and other enhancements over Java. Come to VS Code and have a try!"
The Code Runner extension has been installed 1,400,722 times and has an average rating of 4.7 (out of 5) from 60 reviewers.
The project's GitHub site shows 208 stars, 95 commits, 57 releases and 15 contributors. The last commit was six days ago.
More Resources
So there you have it. While Kotlin doesn't have as much VS Code support as some other popular languages, you can install extensions to highlight Kotlin syntax and run Kotlin code snippets or files upon command.
If it's any consolation, searching for Kotlin in the full-fledged Visual Studio IDE section of the marketplace brought up 0 results. Microsoft is apparently keeping its focus on C# and JavaScript cross-platform solutions, even though the Windows Mobile component of that approach is apparently dead.
So it looks like Android development with Kotlin might be better left to Google's default IDE, Android Studio.
That's basically the conclusion of a discussion the Kotlin site titled "How many IDEs are available to write Kotlin code for Android?"
One answer to that question said: "You can program in Kotlin using a text editor such as Sublime Text or Visual Studio Code, and build your programs using Gradle from the command line. You won’t have access to a debugger, though; debugging is only available in Android Studio."
Luckily, there are plenty of resources to consult for Kotlin programming with that tool. Here's a list:
BTW, for non-Kotlin Android development in VS Code, there's an "Android for VS Code" extension. Its description says: "This is a preview version of the Android for VS Code Extension. The extension allows developers to install, launch and debug Android Apps from within the VS Code environment."
Posted by David Ramel on 10/10/20170 comments
Somewhat lost among all the big "version 2.0" product releases last week was the new Entity Framework Core 2.0.
The open source object-relational mapping (ORM) framework for ADO.NET is now targeting the new .NET Standard 2.0 for consistent API usage across all .NET implementations, along with improved LINQ translation, a Like query operator and many more improvements.
Those enhancements and many more can be seen in EF's "what's new" post.
However, some developers are clamoring for new features that didn't make it into EF 2.0. Judging from user comments, high on that list are GroupBy functionality and lazy loading.
"Any idea when GroupBy translation support and lazy loading will make it in? Those are the major blockers for us," said the first comment to last week's announcement post.
Among dozens of other posts, several other users chimed in, with comments like:
- "I agree, it doesn't make sense to use EF Core 2.0 without GroupBy support."
- "Group by is a must have! EF Core is useless for us at the moment without support for real group by. Grouping at the client is a no-go for real database applications (at least for the kind of applications we write -- Line of Business apps)."
- "Can you please, share information when are these supposed to be available? Lazy loading, group by?"
- "Seems like EF Core is limited to relatively simple applications and data models until it can handle that [table per type] and Group by."
- "I need lazy load, when will it launch?"
- "Keep it up! I suspect adoption will increase massively with lazy loading."
Over at the Reddit social coding site, the lazy loading question was also addressed, implying such support is coming in the next version:
Q: Still no lazy loading of navigation properties...? Isn't that one of the main features of EF? Confused why it wasn't implemented in 1.0.
A: There has been discussion about lazy loading being an antipattern but more than anything the implementation in EF6 was not optimal (or not used correctly) so it has been held back while thoughtfully evaluated. Looks like there's been a recent update on this and it's been tagged for EF Core 2.1
Noted EF expert Julie Lerman is also no big fan of lazy loading and has discouraged users from using it. See below for her comments on that issue and others.
Meanwhile, Microsoft's Diego B Vega, program manager on the EF team, confirmed that lazy loading and GroupBy functionality were targeted for version 2.1.
"Both features are in the 2.1 plan, although lazy loading is a 'stretch goal,' meaning that we will do our best to get to it," Vega said.
While GroupBy functionality and lazy loading figured prominently in Vega's commentary posts, a post related to that latter issue also heads the "most commented" list on the official GitHub site for tracking feature requests, bugs and other feedback.
A 2015 item, "Lazy Loading of navigation properties," received 150 comments. The request starts out with: "I was wondering if I am the only one that thinks EF7 is useless without Lazy Loading? Or do I do something wrong?"
However, no "GroupBy" related requests seem to be high in the most-commented rankings. The GitHub method for tracking feature requests doesn't have the same drill-down capabilities of Microsoft's UserVoice mechanism for tracking Visual Studio feedback.
I reached out to Julie Lerman, one of the top EF development experts, for her take on the user requests.
"There are two types of features that people are clamoring for," Lerman said. "One is features that early versions of EF never had that they've always wanted. We've already gotten lots of those since EF Core's new code base gave the team a new path for enabling these features. The other is things people were used to and dependent on from EF6 (and important for any ORM) such as lazy loading, the GroupBy support and TPT inheritance."
Table per Type (TPT), Vega said, is still a request in backlog, and he invited developers to vote up the issue on GitHub.
Here are Lerman's observations on the other two issues mentioned above:
"GroupBy is a tricky topic," she said. "The people who need it really need it. As far as I know, the path for the EF Team to build it in was depending on another feature that they are working on. I believe that the delay on GroupBy is a combination of things: 1) the 'bang for the buck' with respect to how much work it is for them to implement vs/ the impact it will have compared to the many other features they have been working through on the very long list and 2) the fact that there IS a workaround which is to write custom SQL."
"LazyLoading is something that I have never used and have actively discouraged people from using because I've seen too many teams encountering performance problems when they were not aware of lazy loading's side effects," Lerman continued. "Learning best practices will solve that but it's just too easy to use without knowing how it really works. Since it's easy enough to load related data explicitly after the fact, I think this feature has been overridden by more pressing features that don't have easy alternatives."
EF chief Vega said the framework's roadmap is still being updated for version 2.1 and future releases, but to get an idea of prioritized issues being worked on now, he pointed developers to this GitHub query that sorts issues by 2.1 milestones concerning enhancements.
On that list, the top five most-commented issues include lazy loading and GroupBy functionality:
- Lazy Loading of navigation properties
- Seed Data
- Column ordering
- Relational: Support translating GroupBy() to SQL
- Support for custom type mapping and data store to CLR type conversions
Posted by David Ramel on 08/21/20170 comments
While mostly known for its use in Linux-based development, the versatile curl tool for transferring data over HTTPS can be a nifty timesaver when using Visual Studio Code on Windows.
Specifically, this reporter has found it useful for quickly testing the results of a REST API call.
For example, when wrestling with how to display JSON data in a list view, I want to make sure the URL I'm using for a GET request to a REST API is actually returning data and see exactly how that JSON data is presented.
With the integrated terminal window in VS Code, this oft-repeated task becomes much faster. Rather than having to exit VS Code and go to a browser to see a URL -- say "https://jsonplaceholder.typicode.com/posts" -- and view the results, I can just quickly go to the terminal window -- right below my code -- and type: curl https://jsonplaceholder.typicode.com/posts.
That gives me this:
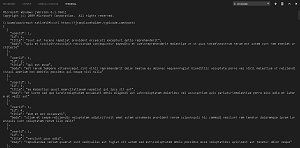 [Click on image for larger view.] Instant REST API Response as JSON
[Click on image for larger view.] Instant REST API Response as JSON
The free, open source curl tool, originally developed by Daniel Stenberg 20 years ago (see Wikipedia page), is extremely versatile and super simple to install.
For me, on a 64-bit Windows 7 machine, installation was as quick as going to the download page and finding the correct package for that configuration. Unzipping it produces just two files -- curl.exe and ca-bundle.crt -- that need to be placed in a directory so the executable is in the path of your terminal window.
As far as versatility, you can find a dizzying array of potential use cases on the "Manual -- curl usage explained" page.
The tool's home page lists an almost equally dizzying number of supported protocols, and more information:
 [Click on image for larger view.] Instant REST API Response as JSON (source: Curl Site).
[Click on image for larger view.] Instant REST API Response as JSON (source: Curl Site).
Curl functionality can also be found in the REST Client extension offering on the VS Code Marketplace, where one of the tool's features is listed as the ability to "Send CURL command in editor and copy HTTP request as CURL command."
More information on testing REST APIs with curl can be found in the appropriately titled article "How to test a REST API from command line with curl" on the CodingpediaOrg site.
Posted by David Ramel on 07/31/20170 comments
Microsoft hasn't been standing still since it became the new commercial steward of the R programming language by acquiring R specialist Revolution Analytics a year ago. The company has been busy revamping its acquired R offerings, including the open source version.
That free download, along with a free developer edition, highlighted a reorganization and rebranding of Microsoft's R products, now called Microsoft R Server.
Along with upgrading and maintaining the open source version, Microsoft exec Joseph Sirosh detailed other open source-related initiatives the company has made surrounding R in a blog post yesterday. For example, he noted that Microsoft became a founding member of the R Consortium, formed "to provide support to the R community, the R Foundation and groups and individuals, using, maintaining and distributing R software." Such moves are furthering Microssoft's transition from a bastion of proprietary, insular software to a champion of the open source movement.
"Microsoft R Open enhances the performance of R with multi-threaded processor optimized computations provided by Intel Math Kernel Libraries (MKL) delivering large speedups especially in matrix-oriented computations," Sirosh said. "It also makes it easier to build reliable applications with R on Windows, Mac and Linux by simplifying the management of R package versions. Microsoft R Open is 100 percent compatible with all R scripts and packages, and just like R is open source and free to download, use and share."
The R language is
popular in the Big Data world because of its statistics capabilities and facility for predictive analytics. The new Microsoft platform consists of the acquired company's offering, Revolution R Enterprise (RRE) for Hadoop, Linux and Teradata -- described as a Big Data-capable R distribution for servers, Hadoop clusters and data warehouses -- along with Microsoft quality enhancements, support and purchasing options.
In another blog post yesterday, David Smith of Revolution Analytics said that, in addition to its new name, "Microsoft R Server includes an updated R engine (R 3.2.2), new fuzzy matching algorithms, the ability to write to databases via ODBC and a streamlined install experience."
Sirosh expounded on the new features and provided further details about the company's R revamp. "Microsoft R Server is a broadly deployable enterprise-class analytics platform based on R that is supported, scalable and secure," he said. "Supporting a variety of Big Data statistics, predictive modeling and machine learning capabilities, R Server supports the full range of analytics -- exploration, analysis, visualization and modeling. By using and extending open source R, Microsoft R Server is fully compatible with R scripts, functions and CRAN packages, to analyze data at enterprise scale. It also addresses the in-memory limitations of open source R by adding parallel and chunked processing of data in Microsoft R Server, enabling users to run analytics on data much bigger than what fits in main memory."
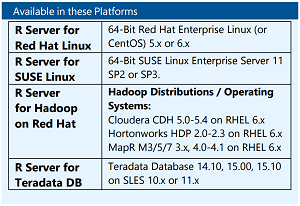 [Click on image for larger view.]
Platform Options (source: Microsoft)
[Click on image for larger view.]
Platform Options (source: Microsoft)
Sirosh said Microsoft wants to make Microsoft R Server the enterprise standard for cross-platform analytics in the cloud or on-premises.
"Delivering Microsoft R Server across multiple platforms allows our enterprise customers to standardize advanced analytics on one core tool, regardless of whether they are using Hadoop (Hortonworks, Cloudera and MapR), Linux (Red Hat and SUSE) or Teradata," Sirosh said "For Windows, Microsoft R Server will be included in SQL Server 2016 as SQL Server R Services -- and the combined bundle is less expensive than RRE standalone. Until SQL Server 2016 is released, Revolution R Enterprise for Windows remains available as a standalone product." The company hasn't specified exactly when SQL Server 2016 will be released, but, barring a name change, it should be this year.
Microsoft, famously characterized by its former CEO as being all about "developers, developers, developers," is also offering a free Microsoft R Server Developer Edition, via Visual Studio Dev Essentials, including all the features found in the commercial version.
That developer edition will also be included in the new Microsoft Data Science Virtual Machine as a pre-installed and pre-configured component. That VM is described as "a Windows Server 2012-based custom virtual machine image on the Azure marketplace containing several popular tools that can be used by data scientists and developers for advanced analytics."
Microsoft R Server is also available free to students for academic use through the company's Microsoft DreamSpark program.
"Advanced and predictive analytics is about developing and testing new models," the company quoted IDC analyst Dan Vesset as saying. "But it's also about their incorporation by developers into production deployments of decision support and automation solutions that can benefit the whole organization. With its new offerings for the R ecosystem, Microsoft is playing an important role in bringing analyst modeling and productivity tools as well as deployment tools to a broader audience."
Posted by David Ramel on 01/13/20160 comments
Less than a month after the first public preview of SQL Server 2016, Microsoft has released an update that for the first time puts the flagship relational database into "rapid preview" cadence.
The counterpart cloud offering, Microsoft Azure, has already been following the model of releasing quicker Community Technology Previews (CTPs), and now the on-premises SQL Server 2016 is following suit.
"With the release of SQL Server 2016 CTP 2.1, for the first time customers can experience the rapid preview model for their on-premises SQL Server 2016 development and test environments," exec Tiffany Wissner said in a blog post yesterday. "This born in the cloud model means customers don't have to wait for traditional CTPs that are released after several months for the latest updates from Microsoft engineering, and can gain a faster time to production. The frequent updates are also engineered to be of the same quality as traditional major CTPs, so customers don't have to be concerned about build quality. "
Microsoft also released previews and general availability releases of several other data-related products, including SQL Server Management Studio (SSMS), which for the first time gets its own preview release separate from the main SQL Engine release cadence. "Our goal is to update this frequently with new features, fixes and support for the newest SQL Server features in SQL Server Engine and Azure SQL Database," the SQL Server engineering team announced in another blog post yesterday. The standalone SSMS has also adopted the rapid preview model.
In the SQL Server 2016 CTP 2.1 (version 2.0 was the first public preview, despite what the versioning number suggests), the Stretch Database functionality introduced last month has been improved. It archives historical data in the Azure cloud, silently migrating it to an Azure SQL Database.
Other functionality was also improved, concerning: Query Store, which deals with the handling of historical query plans; Temporal, which lets users handle and analyze database records as they're changed over time; and Columnstore Index, which received performance boosts in seek functionality and scanning of partitioned tables. More details on these improvements are available in yet another blog post published yesterday.
For the new standalone SSMS, key improvements include: a new lightweight Web installer; automatic update monitoring; fixes in response to top customer requests concerning row editing, Table Designer and database and table property dialogs; a new option to skip the prompt asking users if they want to save T-SQL files; updated import/export wizards; and bug fixes to improve support for Azure SQL Database.
Other preview and general availability releases (you guessed it, detailed in yet another blog post) include:
- The Limited Public Preview of Azure SQL Data Warehouse.
- General availability of Azure AD Connect and Connect Health.
- General availability of Azure Application Gateway.
- Microsoft Intune Conditional Access and Mobile Application Management for the Outlook app.
- General availability of the new Microsoft Power BI Content Pack and connector.
- General availability of Key Vault across all regions (except Australia).
Microsoft invited users to download the SQL Server 2016 preview or test it via an Azure virtual machine (VM) and provide feedback on their experiences.
Posted by David Ramel on 06/25/20150 comments
Look out Microsoft. New Big Data services with a taste of SQL highlighted a bevy of new offerings added to the Oracle Cloud Platform yesterday.
At a live event, exec Larry Ellison was on hand to introduce more than 25 new Software-as-a-Service (SaaS), Platform-as-a-Service (PaaS) and Infrastructure-as-a-Service (IaaS) cloud products.
Among these is the Oracle Big Data Cloud Service, providing an Apache Hadoop-based distribution from Cloudera Inc., dedicated high-performance hardware and networking, and security via Kerberos and Apache Sentry.
Combined with the company's new SQL-on-Hadoop Big Data SQL Cloud Service, they form an enterprise-oriented offering that Oracle calls a comprehensive Big Data Management System. The system extends Oracle's SQL-based implementation to enable unified queries and security across Hadoop and its traditional counterpart database technology, NoSQL.
"Oracle Big Data Cloud Service and Big Data SQL Cloud Service provides a high-performance, secure platform for running diverse workloads on Hadoop and NoSQL databases to help enterprises acquire and organize Big Data," the company said in a news release.
Oracle said that by leveraging the well-known SQL query language, its solution provides familiar technology, tools and training to help organizations address "the widening Big Data skills gap."
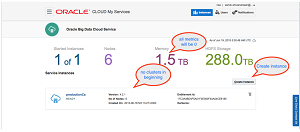 [Click on image for larger view.]
Managing Data in the Cloud (source: Oracle Corp.)
[Click on image for larger view.]
Managing Data in the Cloud (source: Oracle Corp.)
"While experts can easily work with data in Hadoop and NoSQL databases, most of your organization is not familiar with these new environments," an Oracle solution brief states. "But most people do know SQL, and it's the main way that business applications already access data."
"Your analysts can use their existing SQL skills to access new data, and your existing applications require no changes to access data in Hadoop," the brief continued. "Big Data SQL also extends the security capabilities of Oracle Database to data in Hadoop and NoSQL, so you can use your existing policies and processes to keep your data secure."
In addition to supplying familiar technology and the ability to use incumbent skills, Oracle said its new solution uses its SmartScan technology to reduce data movement, which it characterized as one of the major impediments to speedy Big Data analytics, even in the cloud.
On the more traditional database front, Oracle offered another tilt at Microsoft and its Azure Big Data services. The company announced the Oracle Database Cloud - Exadata Service, providing a cloud host that gives users the same functionality, performance and availability of its familiar on-premises Oracle Database packaged with the Exadata appliance. The company describes Exadata as "a modern architecture featuring scale-out industry-standard database servers, scale-out intelligent storage servers, state-of-the-art PCI flash storage servers and an extremely high-speed InfiniBand internal fabric that connects all servers and storage."
The cloud offering is 100 percent compatible with its on-premises counterpart, the company said, which paves the way for a smooth cloud migration or transition to a hybrid implementation providing the best of both worlds.
Another service introduced yesterday is the Oracle Archive Storage Cloud Service, which squarely targets a comparable Amazon Web Services Inc. (AWS) offering at one-tenth the price. You can read more about that at our sister publication, AWS Insider.net. You can also learn more about all the new services in the John K. Waters article, "Oracle 'Completes'its Cloud Platform," on sister site ADT Mag.
Posted by David Ramel on 06/23/20150 comments
Amazon Web Services Inc. (AWS) unveiled a new Microsoft SQL Server Enterprise Edition offering for the Amazon Elastic Compute Cloud (EC2.)
A blog post authored by exec Jeff Barr yesterday said the new, pre-configured Amazon Machine Image (AMI) improves upon the Standard Edition by adding more computing power and memory. Standard allows for using up to 16 cores and 128 GiB of memory, while Enterprise can go up to 32 cores and 244 GiB of memory available in an extra-large instance.
The Enterprise Edition comes with SQL Server Enterprise Edition 2012 and SQL Server Enterprise Edition 2014, available in several regions, as explained in the AWS Marketplace.
Barr highlighted the following new and unique features of the offering:
- High availability lets users configure a primary database and up to four active, readable secondary databases into an Always-On availability group.
- Self-service business intelligence through Power View, used to interactively explore and visualize data.
- Data quality services let organizational and third-party reference data be used to profile, cleanse and match your own data.
- Online change functionality lets users restore files and file groups, alter schemas and make indexing changes while a database remains online.
"You can run the AMI on-demand or you can purchase an EC2 Reserved Instance with a one- or three-year term," Barr said.
In another data-related move, AWS on the same day announced it had added support for the enormously popular Apache Spark project to its Amazon Elastic MapReduce (Amazon EMR) service. "Amazon EMR is a Web service that makes it easy for you to process and analyze vast amounts of data using applications in the Hadoop ecosystem, including Hive, Pig, HBase, Presto, Impala and others," the company said. "We're delighted to officially add Spark to this list. Although many customers have previously been installing Spark using custom scripts, you can now launch an Amazon EMR cluster with Spark directly from the Amazon EMR Console, CLI or API."
Spark is an open-source, distributed processing framework often used for Big Data workloads. It leverages in-memory caching and optimized execution to boost performance over older Hadoop ecosystem components such as MapReduce, supporting general batch processing, streaming Big Data analytics, machine learning, graph databases, and interactive, ad hoc queries, according to the AWS Spark page.
Among Spark's many components is Spark SQL for low-latency, interactive SQL queries.
Posted by David Ramel on 06/17/20150 comments
With prior partnerships in place with Hortonworks Inc. and Cloudera Inc., Microsoft has now teamed up with MapR Technologies Inc., the final member of the "big three" distributors of Apache-Hadoop based software.
"Today, we are excited to announce that MapR will also be available in the summer as an option for customers to deploy Hadoop from the Azure Marketplace," Microsoft exec T.K "Ranga" Rengarajan said in a blog post yesterday.
Hortonworks had been the primary Hadoop partner in the Azure cloud. The companies teamed up in 2011 to eventually offer the Azure-based HDInsight service, featuring the Hortonworks Data Platform (HDP) as the Hadoop distribution providing the software foundation. Hortonworks also developed the Hortonworks Data Platform for Windows, letting Windows users in on the traditionally Linux-based Hadoop ecosystem. HDP is also available as a virtual machine (VM) option in the Azure Marketplace.
Microsoft then added Cloudera to the Azure mix in October 2013, putting Cloudera Enterprise in the Azure Marketplace as another Hadoop-based option.
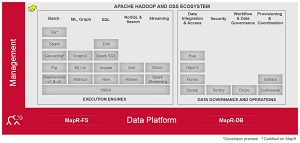 [Click on image for larger view.]
How MapR Fits In (source: MapR Technologies Inc.)
[Click on image for larger view.]
How MapR Fits In (source: MapR Technologies Inc.)
Now, sometime this summer, the MapR Hadoop-based distribution will join the Azure Hadoop party.
"MapR is a leader in the Hadoop community that offers the MapR Distribution including Hadoop, which includes MapR-FS, an HDFS and POSIX compliant file store, and MapR-DB, a NoSQL key value store," Rengarajan said. "The distribution also includes core Hadoop projects such as Hive, Impala, SparkSQL, and Drill, and MapR Control System, a comprehensive management system."
MapR said its distribution on the Azure Marketplace will let users:
- Deploy MapR directly from the Azure Marketplace.
- Transfer data between MapR and Microsoft SQL Server services within Azure.
- Deploy MapR-DB, the MapR in-Hadoop NoSQL database, to support a wide variety of real-time use cases and deployment scenarios.
"As part of this agreement, MapR will fully support deployment of its top-ranked NoSQL database, MapR-DB on Azure," the company said yesterday in a news release. "MapR-DB offers advanced operational features such as multi-master table replication, where business users can analyze data across geographic regions while maintaining low latency and automatic synchronization with a centralized table for analytics and BI."
MapR also yesterday announced that a new version of its distribution, MapR 5.0, will be available in 30 days. "The latest MapR release auto synchronizes storage, database and search indices to support complex, real-time applications to increase revenue, reduce operational costs and mitigate risk," the company said. "MapR 5.0 also includes comprehensive security auditing, Apache Drill support, and the latest Hadoop 2.7 and YARN features."
Rengarajan noted that the Hortonworks distribution was also just updated, to HDP 2.3. That, he said, will also be available in the Azure Marketplace this summer.
Posted by David Ramel on 06/11/20150 comments
Well, Microsoft lied to us. They didn't provide the public preview of SQL Server 2016 "this summer" as promised -- they delivered today.
"The first public preview of SQL Server 2016 is now available for download," the SQL Server 2016 Preview page says today. "It is the biggest leap forward in Microsoft's data platform history with real-time operational analytics, rich visualizations on mobile devices, built-in advanced analytics, new advanced security technology, and new hybrid cloud scenarios."
The new edition of the company's flagship relational database features enhanced in-memory performance, Always Encrypted security technology developed in the company's research unit, "stretch databases" that move data back and forth to the cloud when needed, built-in advanced analytics and many more. You can read more about the new release in my earlier report.
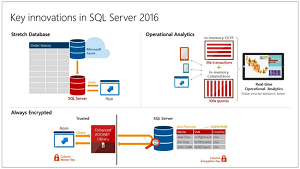 [Click on image for larger view.]
What's New (source: Microsoft)
[Click on image for larger view.]
What's New (source: Microsoft)
Company exec T.K. "Ranga" Rengarajan provided more details in a blog post today. "Unique in this release of SQL Server, we are bringing capabilities to the cloud first in Microsoft Azure SQL Database such as Row-Level Security and Dynamic Data Masking and then bringing the capabilities, as well as the learnings from running these at hyper-scale in Microsoft Azure, back to SQL Server to deliver proven features at scale to our on-premises offering," he said. "This means all our customers benefit from our investments and learnings in Azure."
Row-Level Security lets administrators control access to data based on user characteristics. Security is implemented inside a database, so no modifications are required to an application. With Dynamic Data Masking, real-time data obfuscation is supported so data requesters can't access unauthorized data. Rengarajan said this helps protect sensitive data even when it's not encrypted.
Rengarajan highlighted the following additional capabilities in the Community Technology Preview 2:
- PolyBase -- More easily manage relational and non-relational data with the simplicity of T-SQL.
- Native JSON support -- Allows easy parsing and storing of JSON and exporting relational data to JSON.
- Temporal Database support -- Tracks historical data changes with temporal database support.
- Query Data Store -- Acts as a flight data recorder for a database, giving full history of query execution so DBAs can pinpoint expensive/regressed queries and tune query performance.
- MDS enhancements -- Offer enhanced server management capabilities for Master Data Services.
- Enhanced hybrid backup to Azure -- Enables faster backups to Microsoft Azure and faster restores to SQL Server in Azure Virtual Machines. Also, you can stage backups on-premises prior to uploading to Azure.
He also said ongoing preview updates were coming soon. "New with SQL Server 2016, customers will have the opportunity to receive more frequent updates to their preview to help accelerate internal development and test efforts," Rengarajan said. "Instead of waiting for CTP3, customers can choose to download periodic updates to CTP2 gaining access to new capabilities and features as soon as they are available for testing. More details will be shared when the first preview update is available."
He didn't say when that would be. Just as well, as the company seems to have trouble following its promised timelines.
Posted by David Ramel on 05/27/20150 comments
After stewarding the open source project from incubation to its new 1.0 release, MapR Technologies Inc. added Apache Drill for SQL-based Big Data analytics to its Apache Hadoop distribution.
The company -- one of the "big three" Hadoop vendors along with Hortonworks Inc. and Coudera Inc. -- this week announced the general availability of the open source Apache Drill 1.0 and its inclusion in the MapR Hadoop distribution.
Drill is a low-latency query engine based on ANSI SQL standards that facilitates self-service, interactive analytics at Big Data scales, including up to petabyte scale (1 PB is equal to 1 million GB). One of its key features is that it doesn't depend on traditional database schemas that describe how data is categorized. Discovering such schemas on the fly makes for quicker analytics, the company said.
MapR engineers including Jacques Nadeau and Steven Phillips have taken the lead on the open source project, which was incubated at the Apache Sofwtare Foundation (ASF) in September 2012 with the goal of wedding the familiar workings of relational databases with the huge new scalability demanded by the Big Data era and the agility of Hadoop systems and their heavy use of NoSQL databases.
"The project has been on the fast track in the last nine months since the developer preview in August 2014, delivering seven significant iterative releases, each adding exciting new features and most importantly, improving on the stability, scale and performance required for broader enterprise deployments," MapR exec Neeraja Rentachintala said in a blog post Tuesday.
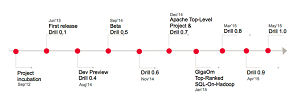 [Click on image for larger view.]
The Apache Drill Project Timeline (source: MapR Technologies Inc.)
[Click on image for larger view.]
The Apache Drill Project Timeline (source: MapR Technologies Inc.)
In addition to SQL queries, the tool can work with varying types of data, including files, NoSQL databases and more complex types of data such as JSON and Parquet.
"Drill enables interactivity with data from both legacy transactional systems and new data sources, such as Internet of Things (IOT) sensors, Web click-streams and other semi-structured data, along with support for popular business intelligence (BI) and data visualization tools," MapR said in a news release. "Drill provides reliability and performance at Hadoop scale with integrated granular security and governance capabilities required for multi-tenant data lakes or enterprise data hubs."
Upcoming features planned for future editions of Drill include more functionality centered on JSON, SQL, complex data functions and new file formats, Rentachintala said.
Posted by David Ramel on 05/22/20150 comments
Syncfusion Inc. has updated its Big Data Platform, unique for its claim to be "the one and only Hadoop distribution designed and optimized for Windows" and free for even commercial use.
"We have fine-tuned the entire Big Data Platform experience, from the download to the end result," said exec Daniel Jebaraj in a statement.
A key update to the platform lets developers handle multiple-node Hadoop clusters on Windows. With a point-and-click cluster management tool, developers can create, monitor and otherwise manage multiple-node jobs running in C#, Java, Pig, Hive, Python and Scala.
Syncfusion says developers can create clusters using commodity machines that run Windows 7, Windows Server 2008 and later Windows versions in just minutes.
"It is still completely free, and typically installs in less than 15 minutes (for a starter cluster) with absolutely no manual configuration," Jebaraj said. "Developers can start with either a 5- or 10-node cluster, and scale as they need in order to grow their business. Between the platform's updates, capabilities, and support options, developers will be able to take their work further than ever."
The company also listed the following features of the new platform:
- Free commercial support for clusters with up to five nodes.
- Optional paid support with service level agreements for larger clusters.
- Unlimited personal commercial support for Syncfusion Plus members.
- A set of C# samples demonstrating use under different scenarios.
- A unique, local, single-node distribution of Hadoop, complete with an interactive development environment and no dependencies outside the Microsoft .NET Framework, facilitating the development and testing of solutions prior to deployment.
In addition to on-premises installations, the company said users can run their own Hadoop clusters on virtual machines supplied by cloud service providers such as Microsoft Azure and Amazon Web Services (AWS), with customization functionality not found in other cloud-based Hadoop services.
The new platform is available now for download.
Posted by David Ramel on 05/20/20150 comments
Native support for JSON in the upcoming SQL Server 2016 was buried among the many goodies announced earlier this month for the flagship RDBMS, but it's clearly an important feature for data developers, who this week got more details on the new functionality.
The item titled "Add native support for JSON to SQL Server, a la XML (as in, FOR JSON or FROM OPENJSON)" is the No. 1 requested feature on the Connect site used to garner feature requests for users of SQL Server and Windows Azure SQL Database.
With more than 1,000 votes and leading other items by more than a 140 votes, the item posted more than four years ago reads:
While JSON import and export is possible in SQL Server using horribly complex T-SQL code or CLR integration using the JavaScript JSON methods, such methods are system-resource intensive. It would be nice if MS could integrate JSON into SQL Server the same ways they do XML: say, a FOR JSON clause, an OPENJSON statement, etc.
It may have taken a while, but Microsoft -- as it's increasingly doing on many fronts these days -- has listened and responded to its customers. Microsoft's Jovan Popovic wrote a recent blog post with extensive details about the new support.
For one thing, "native support" doesn't the mean same thing as introducing a new native JSON type, as was done for XML.
As a refresher, JSON -- standing for JavaScript Object Notation -- uses text name/value (or attribute/value) pairs to represent data, serving as a data transmission technology that's easier to read and less complicated than XML.
And, instead of getting its own type like XML, it will be represented by the existing NVARCHAR type, used for representing variable-length strings. Popovic said Microsoft studied the issue and decided to go the NVARCHAR type for many reasons concerning issues such as migration, cross-feature compatibility and client-side support.
"Our goal is to create simpler but still useful framework for processing JSON documents," Popovic said.
Thus the company is focusing on functionality -- such as export/import and prebuilt functions for JSON processing -- and query optimization, rather than storage.
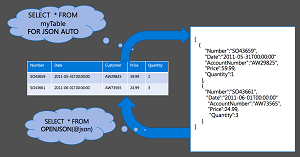 [Click on image for larger view.]
SQL Server 2016: JSON Support (source: SQL Sentry Inc.)
[Click on image for larger view.]
SQL Server 2016: JSON Support (source: SQL Sentry Inc.)
Not to say that this strategy is set in stone. As I said, Microsoft is really listening to customers these days, and things could change.
"We know that PostgreSQL has a native type and JSONB support, but in this version we want to focus on the other things that are more important (do you want to see SQL Server with native type but without built-in functions that handle JSON -- I don’t think so :) )," Popovic said. "However, we are open for suggestions and if you believe the native type will help, you can create request on connect site so we can discuss it there."
(Some readers didn't even wait to open a Connect item. "This seems like a massively crippled feature and until there is native support I don't believe it offers anything even remotely similar to PostgreSQL," a reader named Phillip wrote in a blog comment.)
Anyway, Popovic explains the nitty-gritty details on the company's initial focus for JSON functionality, detailing how to export JSON with the FOR JSON clause (as was suggested in the original Connect request), how to transform JSON text to relational tables with the OPENJSON function and so on.
"Someone might say -- this will not be fast enough, but we will see," Popovic said. "Built-in JSON parser is the fastest way to process JSON in database layer. You might use CLR type or CLR parsers as external assemblies, but this will not be better than the native code that parses JSON."
Popovic said the JSON functionality will be rolled out over time in the SQL Server 2016 previews. SQL Server 2016 CTP2 is planned to include the ability to format and export data as JSON string, while SQL server 2016 CTP3 is expected to incorporate the ability to load JSON text in tables, extract values from JSON text, index properties in JSON text stored in columns, and more, he said.
The SQL Server team will be publishing more details about the huge new release of SQL Server 2016 as the days count down to the first
public preview, expected this summer.
If you can't wait, those wacky wonks on Hacker News managed to stay somewhat on-topic in a discussion about the new JSON support, and noted database expert Aaron Bertrand goes into really extensive detail in a blog post on the SQL Sentry site.
Posted by David Ramel on 05/19/20150 comments