Data development news this week includes the availability of Oracle software and Java on Windows Azure, a service to quickly turn SQL Server stored procedures into RESTful APIs and a database-comparison tool's early support for SQL Server 2014.
First announced in a preview last June by Satya Nadella (who's been in the news himself a bit recently), the Windows Azure/Oracle collaboration was made official with a general availability announcement yesterday. Java developers can now work with Oracle's database and WebLogic Server on licensed virtual machine (VM) images.
"We'll also work together to add properly licensed, and fully supported Java into Windows Azure -- improving flexibility and choice for millions of Java developers and their applications," Nadella said last June. "Windows Azure is, and will continue to be, committed to supporting open source development languages and frameworks, and after today's news, I hope the strength of our commitment in this area is clear."
Well, one thing that's clear is that Nadella now has much more gravitas to see that commitment through.
As Jeffrey Schwartz reported yesterday on VirtualizationReview.com, Java support on Windows Azure was previously available through the open source OpenJDK. "For those who wanted to use Oracle's Java license, the partnership offers a fully licensed and supported Java on Windows Azure," Schwartz explained.
In other news this week, Espresso Logic Inc. announced developers can now quickly create RESTful APIs for stored procedures with its cloud-based platform, a "reactive service for SQL data." Espresso 1.2 supports SQL Server version 2005 and later, along with Windows Azure SQL Database, Oracle and MySQL.
"Using the new functionality, developers can quickly create mobile applications that leverage a company’s investment in stored procedures," the company said. "The Espresso Designer exposes stored procedures as REST/JSON resources while the supporting infrastructure is handled by the Espresso service."
The announcement is among many that have recently highlighted the growing importance of RESTful APIs in mobile app development.
Meanwhile, just today, xSQL Software announced it was getting an early jump on SQL Server 2014 support by its SQL Server schema compare tool.
Enhancements to
version 5 of the xSQL Schema Compare and Data Compare tools include "all new and improved SQL Server 2014 objects such as memory-optimized filegroups, memory-optimized tables, hash and range indexes, columnstore indexes, memory-optimized table types, natively compiled stored procedures, primary and secondary selective XML indexes, XML index and namespace paths," the company
said.
SQL Server 2014, of course, is coming soon.
What do you find new and exciting in the world of SQL Server development? Weigh in here or drop me a line.
Posted by David Ramel on 03/14/20140 comments
I feel for you, Scott Hanselman, I really do. I completely understand your wanting to address the irrational vitriol constantly directed toward Microsoft, especially by the developer community. But your blog post, "Microsoft killed my Pappy," won't alleviate anything. It just won't work. As the saying quoted by one commenter goes, "haters gonna hate."
I've got to admit, I used to vaguely dislike Microsoft. For all the usual reasons: big, monolithic, evil empire out to enrich itself through any means possible while trampling over the little guy, dictating to rather than listening to customers, and on and on.
Then I got this job and really began to look at the company. It's no more evil than any other corporate behemoth. It's doing some good things in open source development (Hanselman's bailiwick) and in many other areas. It produces first-class dev tools and listens to customers, changing things they don't like. Witness the silly ALL-CAPS fiasco for Visual Studio menus and much more important things like early access to Windows 8.1 for developers. Microsoft is a bunch of generally well-meaning people simply trying to do their job, just like you and me. As Hanselman pointed out, the company isn't nearly organized enough to be so evil.
But haters gonna hate. Of course, Hanselman is a much smarter guy than I am, and he knew that. Maybe he just got fed up with the unfairness of it all and had to address it. More likely, he wanted to slowly chip away at the issue and stir up some discussion. Which he surely did, with more than 250 comments to his post as I write this.
"I didn't work for The Man when all this [antitrust action and other things] went down, and I was as outraged as you were 20 years ago (assuming you were alive)," Hanselman said. "But now, I've been here pushing open source and the open web for over 5 years and things are VERY different."
He roused comments from a fair share of sympathizers, but, this being the Web, comments quickly deteriorated, with everybody attacking everybody. At one point, Hanselman had to step in with the comment, "Good discussion folks! Let's do keep the language clean and constructive and avoid hyperbole," after one profanity-laden post.
Readers came up with dozens and dozens of reasons to hate Microsoft, including killing off their favorite products (speaking of which: Keep Silverlight Alive!). One reader seemed to sum up the comments from that camp: "MS hate is well-deserved."
I don't think so. I think Microsoft is an easy target. Back when I vaguely disliked Microsoft, I used to work for a well-known, nationwide print/Web tech publication. After I left and began working with Microsoft technologies more, I saw a shocking pattern of bias against Microsoft at that media outlet. I couldn't believe it. One of the first things you learn in Journalism 101 is to be objective, no matter what your personal feelings (or maybe, these days, no matter how many clicks you're trying to get). That's gone out the window at that former company, and they might not even be aware of it.
I actually thought of collecting a bunch of headlines and lumping them together so the bias is readily apparent. The headlines with negative connotations must outnumber the others 10 to 1. One guy in particular has an absolute knack for taking any kind of news about Microsoft and putting a negative spin on it--even when the company does something (arguably, in my opinion) good. It's amazing. I felt like pointing this out to the editor in chief, a friend of mine, but I don't have time and anyway I quickly realized it would be useless. Haters gonna hate, and "news" organizations gonna chase clicks (yeah, me too). Everybody hates Microsoft? Feed the frenzy and watch the clicks climb in your Web site analytics tool. I can understand this attitude in opinion pieces, like this, but it's a much more insidious and dangerous practice when it seeps into so-called "objective" news articles. It demeans the company and my profession even more so.
Speaking of clicks, I garnered a few myself with an article titled "/* Microsoft should go to hell...*/: Developers Rip Microsoft in Source Code." I found it fascinating that so many developers took pains to attack Microsoft in source code comments. Who's going to read those? Hardly anyone, even after the code search tools came along. The article sparked a lively conversation on Hacker News. A much more recent post titled, "Ask HN: Why the Microsoft hate?" did even better, with 540 comments.
Over on Slashdot, a post titled, "Why Does Everyone Hate Microsoft?" garnered an incredible 1,540 comments (Hanselman's article isn't doing too badly over there either, with 721 comments just four days after publication).
I don't really know the answer to these questions, but they surely strike a nerve, with developers especially.
So please excuse my going off-topic with this deviant diatribe, data developers. Hanselman's article just exemplified something I think about every time I see Microsoft attacked in the "objective" press. But, like so many things that confound me these days, there's no stopping it.
Let's go positive! What do you LOVE about Microsoft? Comment here or drop me a line.
Posted by David Ramel on 02/25/20140 comments
OK, raise your hands: Do you do your data programming in Visual Basic .NET? If I was a speaker at a development conference and asked that question, I'd expect to be squinting to see the results.
Yet this month's TIOBE Programming Community Index, which measures the popularity of programming languages, reports that Visual Basic .NET has cracked the top 10 for the first time ever, right between JavaScript and Transact-SQL (the latter of which, by the way, was recently named by TIOBE as "programming language of the year").
Though not specific to data-related programming, the TIOBE index measures popularity by counting the number of developers using a language, courses offered, search engine results and more.
Visual Basic .NET saw an increase of 0.79 percent, the fourth-highest percentage gain among the top 20 languages listed. That moved it from No. 12 last February to No. 10 this month.
Here's TIOBE's take on the news:
This is quite surprising for two reasons. Visual Basic .NET is the successor of Microsoft's well-beloved classic Visual Basic 6.0 version. Since Visual Basic .NET needed to run on Microsoft's .NET platform, the language has changed drastically. Many software engineers refused to migrate to Visual Basic .NET. For this reason, Visual Basic .NET has been criticized through the years. The other reason why this is surprising is that Microsoft seemed to slow down further development of Visual Basic .NET. For example, the latest Visual Studio version 2013 doesn't contain any new Visual Basic .NET language features.
The index shows "(Visual) Basic" at No. 7, even though it suffered a percentage drop. The "classic" Visual Basic has fallen considerably since its peak in April 2004 and is lately trending steeply downward. In fact, Visual Basic .NET, which debuted on the index in September 2010, has been climbing and it looks like the two could intersect in the next few months.
It's hard to make similar comparisons to TIOBE's rankings with other such programming language popularity tools because many don't distinguish between classic Visual Basic and Visual Basic .NET or don't show historical trends. Anyway, for what it's worth, examinations of other sites, of varying formats and publication dates, shows the following. The PYPL PopularitY of Programming Language Index shows Visual Basic at No. 10 in its chart. LangPop.com shows Visual Basic at No. 16. On the Transparent Language Popularity Index, Basic (no "Visual") was No. 5 last July. The RedMonk Programming Language Rankings: January 2013 site shows Visual Basic at No. 19. You can also fool around with tools at TrendySkills and Google Trends.
What do you make of this rise in popularity? What do you think of Visual Basic .NET? Comment here or drop me a line.
Posted by David Ramel on 02/21/20140 comments
A recent blog post from Microsoft's data guru titled "What Drives Microsoft's Data Platform Vision?" provided a clear answer: the cloud. Well, duh.
No news there. For quite a while now, at Microsoft, it has been: "The cloud is the answer. What's the question?" Specific details data developers might be interested in, however, were scarce in the post by Quentin Clark, corporate vice president of the Data Platform Group. There was a lot of stuff like, "After the delivery of Microsoft SQL Server 2012 and Office 2013, we ramped-up our energy and sharpened our focus on the opportunities of cloud computing."
I found myself trying to read between the lines. Was there any new information here? Any subtle clues? Any news by omission? I became a Microsoftologist.
To explain: In the old days, before The Wall came crumbling down, news coming out of the Soviet Union was so skimpy it fostered an analysis technique called Kremlinology, wherein Western strategists tried to glean insights about the direction of the Evil Empire by noting little details like who stood next to whom in parade reviews and combing through speeches for hidden clues.
What struck me most: Where's the Big Data? The rest of the data development world is going crazy about Big Data, but in this post, not so much. It was cloud, cloud and more cloud. My Microsoftology revealed 13 references to "cloud" and seven to "Windows Azure." The total number of "Big Data" references? Two. But there was one reference to "HDInsight" and five to "Hadoop." So, total score: cloud, 20; Big Data, 8.
I also noted in other news that Microsoft development rock star Scott Guthrie (ScottGu) was reportedly named to be the new head of the cloud division, replacing the new CEO, Satya Nadella.
Hmm. Maybe if you're a Microsoft data developer, you should be "Getting Trained on Microsoft's Expanding Data Platform" by taking classes such as "Platform for Hybrid Cloud with SQL server 2014" and "Windows Azure SQL Database" rather than "Getting Started with Microsoft Big Data" and "Big Data Analytics," as featured in another blog post yesterday.
Then again, another Microsoft blog post last week noted: "Microsoft to Join the Big Data Conversation as an Elite Sponsor at Strata, Santa Clara, CA." Just joining the conversation? Maybe it's just late to the party.
What's your take on the future of data development on the Microsoft stack? Comment here or drop me a line.
Posted by David Ramel on 02/07/20140 comments
A new survey of database developers and other professionals shows Microsoft is maintaining its lead in the Relational Database Management Systems (RDBMS) and data warehousing arenas, but faces challenges from newcomers in Big Data and other markets.
Conducted by Progress Software Corp., the "Progress DataDirect 2014 Data Connectivity Outlook" survey purported to reveal "the rising stars in the database constellation." Developers constituted the largest group of respondents (36 percent of 300 existing customers surveyed), followed by CXOs and other management types.
For the RDBMS and enterprise data warehouse markets, respondents were asked about their data technologies currently in use and those expected to be implemented within the next two years. Although Microsoft (SQL Server) and Oracle unsurprisingly took the top two positions in current and projected usage in the RDBMS market, the survey "projects significant growth for emerging alternatives such as the community-developed MariaDB as well as the SAP HANA in-memory platform, over the next two years," Progress said this week.
In the enterprise data warehouse world, the top three technologies currently in use were again no surprise: SQL Server, Oracle and IBM DB2. However, all three were projected to show lower numbers in two years, while the current No. 4, Teradata, was expected to see higher usage. Amazon Redshift will reportedly show the biggest percentage increase in adoption, but is still expected to be in use by only slightly more than 10 percent of respondents in two years. SQL Server usage is expected to drop from being used by about 58 percent of respondents today to about 48 percent of respondents in two years.
Perhaps more of a surprise, Microsoft HD Insights was listed as the No. 2 Hadoop provider, following overwhelming market leader Apache's open source distribution, listed by more than 45 percent of respondents. Cloudera placed a close third, followed by Oracle DBA, Amazon EMR, IBM BigInsights, Hortonworks, MapR and Pivotal HD. This question asked respondents only what distribution they currently used or planned to use in the next two years, so there was no indication of growth over that period.
"With open-source Apache's low-cost of entry propelling its lead in the market, one can expect other big players in Big Data to further iterate their own unique value and perspectives when it comes to data storage within Hadoop databases like Hive, HBase and Cassandra," the survey report said. "Future competition from many of the large vendors may begin to change market distribution, but no significant changes are foreseen."
Another question concerned usage of NoSQL, NewSQL and non-relational databases, asking only which technologies were currently used or supported. Here, MongoDB held a large lead, used by nearly 40 percent of respondents, with SQLFire, Cassandra, HBase and CouchDB/Couchbase rounding out the top five of the 14 total products listed.
Salesforce.com reported a huge lead in respondents answering the question: "Which [Software as a Service ] SaaS applications do you or your customers currently use or support in your applications?" It was the choice of more than 40 percent of respondents, while Microsoft Dynamics CRM Online came in second, listed by more than 20 percent, followed by SAP Business ByDesign, Force.com and Intuit QuickBooks.
Progress said its first survey of this type "shows that while established vendors still hold significant share, a new set of rising stars--many of them lower-cost alternatives--are emerging in the data source world."
What do you think of the future of the database development landscape? Comment here or drop me a line.
Posted by David Ramel on 02/03/20140 comments
I've noted before how data-driven developers in general and SQL gurus in particular are pretty well set in terms of salary and job security. So I was curious how database skills fared in responses to a recent Slashdot.org question: "It's 2014--Which New Technologies Should I Learn?"
An anonymous reader's "Ask Slashdot" posting on Wednesday read thusly:
"I've been a software engineer for about 15 years, most of which I spent working on embedded systems (small custom systems running Linux), developing in C. However, Web and mobile technologies seem to be taking over the world, and while I acknowledge that C isn't going away anytime soon, many job offers (at least those that seem interesting and in small companies) are asking for knowledge on these new technologies (Web/mobile). Plus, I'm interested in them anyway. Unfortunately, there are so many of those new technologies that it's difficult to figure out what would be the best use of my time. Which ones would you recommend? What would be the smallest set of 'new technologies' one should know to be employable in Web/mobile these days?"
I was so curious I combed through more than 370 comments to total up and compare the "technologies." Obviously, that's a broad term and could (and apparently did) mean just about anything, so I just focused on programming languages (as opposed to, say, "Learn to lie and [BS] with a straight face"). And I wasn't alone in wondering what constituted a "new technology."
Of course, this being Slashdot, the readers branched off on all kinds of bizarre tangents. It's amazing how these people can take the most insignificant, meaningless aspect of such a question and absolutely beat it to death. It's often pretty darn funny, though.
Anyway, a lot of Slashdot readers know their stuff, so I was interested in what they had to say, regardless of the wide range of possible interpretations of the question. My sampling is in no way scientific, or a real survey or even reliant upon any kind of reproducible methodology. I simply tried to total up the language suggestions I found in each of the comments. I didn't subtract votes when a suggestion was hammered by other readers with the inevitable vicious insults and snarkiness (some things will never change).
I guess the results were fairly predictable, but I was kind of disappointed in how database technologies in general ranked.
What was completely clear is that the overwhelming favorite is ... you guessed it: JavaScript. A rough grouping (not counting a lot of people who said just stick with C) looks something like this:
- First: JavaScript
- Second: Java
- Third: PHP, HTML(5)
- Fourth: Objective-C, Python
- Fifth: Ruby, SQL, C++, C#
- Sixth: HTTP, ASP.NET, CSS
Several dozen more languages were suggested in smaller numbers.
Being the resident Data Driver bloggist at Visual Studio Magazine, I was disappointed to see SQL so far down the list. Even totaling up all the other database-related languages, such as MySQL, SQLite, MongoDB and so on, wouldn't result in that impressive of a number (I stopped counting these when I realized none would total more than a few votes).
A couple of comments might shed some light on the prevailing attitudes out there. One commenter wrote: "RDBMSes are going to die, so learn how to interact with one of the major NoSQL databases. Most bleeding-edge: Titan and Neo4J, both graph databases."
Another wrote: "Some SQL is very useful but you don't need to be an expert--any serious Web development team will have a database expert who will do the DB stuff, you just need enough to code up test setups, prototypes and to talk to the DB guy."
I don't know exactly why "the DB guy" is separate from the rest of the Web dev team, or why the original poster couldn't be "the DB guy," but whatever.
The question was limited to the Web/mobile arena, remember, so it's not totally disheartening. I mean, there is this little thing called Big Data happening, and vendors are jumping all over themselves trying to come out with applications and packages and such to let the SQL guys and other "DB guys" join in the fun along with the Hadoop specialists and data scientists. But I guess nobody will be doing any Big Data stuff over the Web or with a mobile device.
And SQL didn't fare too badly in more broad examinations of this topic, earning a spot in "
Top 10 Programming Languages to Know in 2014" and "
10 Programming Languages You Should Learn in 2014." Also, of course, Transact-SQL was named "
programming language of the year" for 2013 by TIOBE Software.
What do you think? What would be your top suggestions for staying current in this new world? Comment here or drop me a line.
Posted by David Ramel on 01/24/20140 comments
Maybe it's not the sexiest programming language, but SQL continues to be relevant. In fact, TIOBE Software, which publishes a TIOBE Programming Community Index gauging the popularity of programming languages, named Transact-SQL the language of the year for 2013.
This "award" further emphasizes the importance of competency in SQL. I earlier wrote about how SQL gurus and other database-related programmers enjoyed excellent job security and how SQL Server developers were in high demand.
That's the good news. The bad news, according to TIOBE, "It is a bit strange that Transact-SQL wins the award because its major application field, Microsoft's database engine SQL Server, is losing popularity. The general conclusion is that Transact-SQL won because actually not much happened in 2013."
Not much happened in 2013? Wow, talk about strange. Has TIOBE heard of a little thing called Big Data?
Anyway, following Transact-SQL in popularity gains were Objective-C and F#. Objective-C had been the "language of the year" for the previous two years.
Microsoft fared well in other aspects, too, even regarding the much-maligned Windows Phone platform. As TIOBE wrote: "As we have seen the last decade, programming language popularity is largely influenced by external trends. The most important ones at the moment are mobile phone apps and web development. Android (mainly Java) and iOS (Objective-C) are the major mobile platforms, while Windows Phone (mainly C#) is catching up."
In index rankings, Transact-SQL went from No. 22 in January 2013 to No. 10 in January 2014. Otherwise, the rankings stayed the same for the top eight positions: C, Java, Objective-C, C++, C#, PHP and Python. The only other move in the top 10 was JavaScript going from 10th to the 9th spot.
In other attempts at ranking the popularity of programming languages, SQL was No. 12 in a list developed by LangPop.com last October. Meanwhile, Python garnered the "language of the year" prize in the Popularity of Programming Language (PYPL) index, which measures how often respective language tutorials show up in Google searches. No variants of SQL made the top 10. TIOBE said its ratings "are based on the number of skilled engineers world-wide, courses and third party vendors."
In Google Trends, searches for "SQL Programming Language" held fairly steady throughout 2013, except for a strange dip right at the end of the year.
How do you feel about the importance of keeping your SQL skills honed? Do these popularity rankings mean anything at all? Comment here or drop me a line.
Posted by David Ramel on 01/16/20140 comments
Regardless of the future of the Microsoft ecosystem (and those latest quarterly numbers should slow the naysayers some), data developers can rest easy knowing their SQL Server skills are transferable in the New Data Order.
The latest example is yesterday's open sourcing of a new distributed SQL query engine for Big Data developed by Facebook, called Presto.
It was designed to improve upon existing solutions for Big Data analytics such as Hadoop MapReduce and Hive, Facebook's Martin Traverso said in a post announcing the move to GitHub. "Presto is a distributed SQL query engine optimized for ad-hoc analysis at interactive speed," Traverso said. "It supports standard ANSI SQL, including complex queries, aggregations, joins and window functions."
Traverso said Presto has provided performance gains of up to 10 times more than equivalent Hive/MapReduce tools in CPU efficiency and latency for most queries. While it doesn't run on Windows, "It currently supports a large subset of ANSI SQL, including joins, left/right outer joins, subqueries, and most of the common aggregate and scalar functions, including approximate distinct counts (using HyperLogLog) and approximate percentiles (based on quantile digest)," he said.
Yes, SQL isn't going anywhere. It has withstood challenges in one form or another from other Relational Database Management Systems such as Oracle, branch movements such as MySQL, hybrids like the NoSQL movement and so on. The Big Data onslaught seemed to be stealing much of its mindshare, but the pendulum is swinging back. The problem was that the specialized Hadoop-based solutions often proved too cumbersome to quickly and efficiently glean meaningful analytics from the vast new data stores.
"This enormous knowledge gap in accessing Big Data in Hadoop has prompted an avalanche of vendors to offer SQL-on-Hadoop solutions, which increase the accessibility of Hadoop and allow organizations to reuse their investment learning in SQL," stated a Gigaom report titled "Sector RoadMap: SQL-on-Hadoop platforms in 2013."
"SQL is widely known by most business analysts," the report continued. "Many nontechnical staff without a programming background can write SQL and use traditional business intelligence (BI) tools like Tableau, MicroStrategy, and Business Objects to query data."
Further evidence of SQL's solid positioning came in a recent presentation by Roger Magoulas, research director at O'Reilly Media, at the Strata Conference + Hadoop World event. He spoke about "the state of data science as a profession." An O'Reilly salary survey conducted last year reported that the top tool in use by the responding data scientists was SQL. "I guess it's not a surprise ... we heard some of the other speakers talk about it ... that SQL is still the top thing being used," Magoulas said. His accompanying slide proclaimed "SQL Rules" and indicated 71 percent of respondents reported it as their data science tool of choice. Hadoop was a surprising No. 5 at 35 percent. SQL users also fared well in the salary level findings, but averaged below the far-fewer number of Hadoop specialists.
You can expect to soon hear about more SQL-related Big Data initiatives, joining high-profile efforts such as Teradata's Enterprise Access for Hadoop; Cloudera's Impala; IBM's Big SQL Technology Preview; Hortonworks' Stinger; and many, many more. Stay tuned.
What do you think of the SQL-on-Hadoop and other SQL-related Big Data technologies? Comment here or drop me a line.
Posted by David Ramel on 11/07/20130 comments
Microsoft today announced the availability of SQL Server 2014 CTP2, a near-final version highlighted by new in-memory capabilities formerly called Project Hekaton.
The in-memory enhancements include new Online Transaction Processing (OLTP) features (Hekaton), and column store technology, along with better T-SQL support and new indexes and advisory tools. The product already featured in-memory data warehousing and business intelligence functionality.
New cloud capabilities such as easier backup and recovery in Windows Azure were also announced by Microsoft exec Quentin Clark in his keynote address at the Professional Association of SQL Server (PASS) Summit 2013 in Charlotte, N.C.
Clark noted that this "public and production-ready" release is shipping only 18 months after SQL Server 2012, a much faster release cycle than previous SQL Server versions.
"A year ago we announced project 'Hekaton,' and today we have customers realizing performance gains of up to 30x," said Clark, corporate vice president of the Data Platform Group. "This work, combined with our early investments in Analysis Services and Excel, means Microsoft is delivering the most complete in-memory capabilities for all data workloads -- analytics, data warehousing and OLTP."
Clark also nodded to the Big Data phenomenon, noting that customers are collecting and storing more data than ever before, such as machine signals, data from devices and services and even data from outside the organization, "so we invest in scaling the database and a Hadoop-based solution."
The new Windows Azure backup and recovery features are part of Microsoft's "hybrid cloud" strategy in which customers can work with SQL Server databases on-premises and back them up and recover them from the cloud. Clark announced today that all currently supported SQL Server releases can use Windows Azure backup. A preview of a stand-alone SQL Server Backup for Windows Azure Tool will be available for download later this week.
The CTP2 trial is available for download now along with a product guide.
Posted by David Ramel on 10/16/20130 comments
Microsoft last week updated its latest WCF Data Services version so it will work with Entity Framework 6.
Rather than requiring the download of a new WCF DS version, the update to version 5.6.0 comes in the form of an out-of-band alpha1 NuGet package called, appropriately, WCF Data Services Entity Framework Provider.
WCF DS 5.6.0 was released in August with support for Visual Studio 2013, portable libraries and other enhancements. The VS 2013 support lets developers consume OData services with the Add Service Reference functionality. The portable libraries support lets developers use the new
streamlined JSON format (part of the OData v3 protocol, sometimes called "JSON light") in Windows Store and Windows Phone 8 apps. While core libraries have support for .NET Framework 4.0, the WCF DS client portable library support targets .NET 4.5. Both the core libraries and the WCF Client have support for Windows Phone 8, Windows Store and Silverlight 5 apps.
Users, however, wanted more. A couple of readers responded in the comments asking about OData v4 support, and one asked, "Does this release include EF 6 support." Microsoft's Mark Stafford last week replied, "Sort of. The EF 6 support will come in a different NuGet package, which will go into alpha today."
The Oct. 2 NuGet update that catches up to EF 6 was made possible by some work the WCF DS team was doing to make providers public. The team wanted to override provider behavior so developers could use features such as spatial properties and enums, which lack native support in the OData v3 protocol. "Unfortunately we ran into some non-trivial bugs with $select and $orderby and needed to cut the feature for this release," the team said in its August announcement.
However, that work paid off later, the team said in last week's update announcement. "We were able to build this provider as an out-of-band provider (that is, a provider that ships apart from the core WCF DS stack) because of the public provider work we did recently" the team said.
The new support for EF 6 basically results from a new class, EntityFrameworkDataService<T>, where T is type DbContext. For previous EF versions, developers should use the base class DataService<T>, where T is type DbContext or the older ObjectContext.
"The new public provider functionality comes with a little bit of code you need to write," the team said. "Since that code should be the same for every default EF 6 WCF DS provider, we went ahead and included a class [the new EntityFrameworkDataService class] that does this for you."
The team admitted that it didn't have time to do full testing on the new provider because the developers were "heads down" preparing for OData v4 support. "So ... we're going to rely on you, our dear customer, to provide feedback of whether or not this provider works in your situation. If we don't hear anything back, we'll go ahead and release the provider in a week or so." Which should be right around now.
Have you tried it yet? Comment here or drop me a line.
Posted by David Ramel on 10/10/20130 comments
I was dropped by my previous auto insurance company for a couple of at-fault accidents on my wife's driving record.
Trouble was, she was not involved in those accidents in any way. They happened to somebody else and somehow got on her report from a data collection company used by the insurer. And, try as I might, I could not convince the insurance company of this. I provided the company with a note from my previous insurer confirming that those accidents were not hers. I even provided an official driving record from the state showing those weren't her accidents. It didn't make any difference to the insurance company (as much as I'd like to see the company burned to the ground in an agonizing bankruptcy, I won't name it, but it definitely wasn't on my side). The accidents were on the ChoicePoint report--that's all that mattered.
I contacted the data collection company and began the nightmarish process of trying to get their information corrected. I eventually gave up; it just wasn't worth the hassle they were putting me through. (Ironically, I've never--ever--been in an at-fault accident. Believe it or not, I've never even received a moving violation, in several decades of driving. I was probably one of the best customers the insurance company could've had.)
I bring up these painful memories because of recent reports about a Big Data company, Acxiom, that this month announced a portal where individuals can look up information collected about them. Several articles noted that the portal, AboutTheData.com, reported some incorrect information. So I checked it out.
Sure enough, the site had a few things wrong, including my birth date, which was strange because I had just provided that date as part of registering for the privilege of looking up my info (pretty sly way to collect data, when you think about it--these people aren't stupid, like people in some other companies, if you know what I mean). They also got my education level, race and age of children wrong, among a few other things. Keep in mind the portal is in beta, and it gives you the chance to correct the data (I didn't even try to go there) and even opt out of the system.
So, just a warning: If you're a developer and your company is hopping on the Big Data bandwagon and you're assigned to the project, be very careful about the quality of the information you collect, especially if the data will have a significant impact on the success of the project--and the company's bottom line.
I mean, just imagine how much money that previous insurance company left on the table if the fiasco I experienced was commonplace among its multitude of customers. Fortunately, my new insurer uses a different data collection company that actually has accurate information and I got a sweet rate. And my present insurer is soaking up those monthly premiums and hasn't had to pay out a dime. Think of that, repeated thousands and thousands of times. If they only knew, I imagine the headquarters honchos in Columbus, Ohio, would be kicking themselves.
Have you any Big Data horror stories? Comment here or drop me a line.
Posted by David Ramel on 09/19/20130 comments
Microsoft may have been late to the cloud party, but its Windows Azure ranks near the top when it comes to popularity for data-related development, according to a new survey from Forrester.
The Forrsights Developer Survey, Q1 2013 found that North American and European developers preferred the Amazon EC2 cloud service for their compute services by a significant margin over Windows Azure, but it's a different story for Relational Database Management Systems (RDBMS) services.
"Microsoft and Amazon are neck and neck amongst users of cloud RDBMS," said Forrester analyst Jeffrey Hammond in a blog post yesterday.
The survey found that the top three types of cloud services adopted by developers are compute, storage and relational data services. Hammond said 47 percent of respondents regularly use compute and storage services, while 36 percent use RDBMS services. These numbers come from 325 developers in the North America and European regions (out of 1,611 total) who reported they had used cloud computing or elastic applications.
Of those respondents using cloud compute services, 62 percent said they were using Amazon EC2 or planned to expand their use of it in the next year. That compares to 39 percent for Windows Azure and 29 percent for the Google Cloud Platform.
That gap of more than 20 points in adoption "is well outside a standard margin of error, so we have to give the nod to AWS when it comes to compute," Hammond said.
"Things are very different when it comes to developers using cloud-based RDBMS services," Hammond said. There, 48 percent of developers reported they were "implementing and expanding" use of Microsoft SQL Azure, followed by 45 percent for the Amazon RDS service (see Figure 1). However, that 3-point gap is within the margin of error.
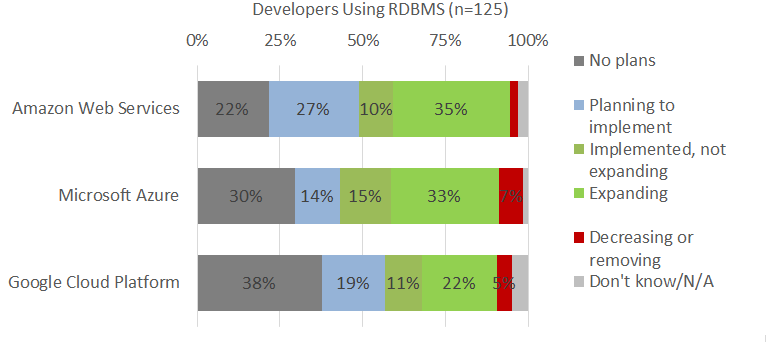 [Click on image for larger view.]
Figure 1. Survey respondents using cloud RDBMS services (source: Forrester Research Inc.)
[Click on image for larger view.]
Figure 1. Survey respondents using cloud RDBMS services (source: Forrester Research Inc.)
"Also note that there are a high number of developers that are planning to implement Amazon's RDS service (27 percent) while 7 percent of Microsoft SQL Azure developers plan to decrease or remove their RDBMs workloads," Hammond said. "Overall, we'd have to rate this workload as a push--with no clear adoption leader."
The percentage of developers who reported using cloud storage and plan to expand that usage over the next 12 months was almost equally divided among Amazon Web Services, Windows Azure and Google Cloud Storage, at 25 percent, 22 percent and 23 percent, respectively.
"Amazon still has a larger body of developers that have implemented but are not expanding AWS S3 (17 percent compared to 10 percent for Microsoft Azure and 9 percent for Google, respectively)" Hammond said. "Our take: this workload looks like it's headed for a strongly competitive market in 2014."
So, despite a lag of about 4 years between the introduction of Amazon EC2 (August 2006) and Windows Azure (February 2010), Microsoft has caught up in attracting developers to its cloud platform. That's interesting news, considering the popular backlash about Microsoft's decision to not provide developers early access to the Windows 8.1 RTM.
What is it that makes Windows Azure database-related services so popular among developers? Comment here or drop me a line.
Posted by David Ramel on 09/05/20130 comments