The Microsoft Entity Framework has a spotty history of inconsistent release strategies, lagging feature requests and other issues, but things seem to be getting better with new leadership and even community contributions since it went open source.
The past problems with the Object Relational Mapping (ORM) tool were candidly discussed this week when EF team members Rowan Miller and Glenn Condron visited with Robert Green on the Visual Studio Toolbox Channel 9 video show to preview EF 6, which is "coming soon."
Reviewing past release history, Miller admitted the 2 years it took to update EF 3.5 SP1 to EF 4 was excessive. "That's really slow if you're waiting for new features," he said. Trying to get new features out to customers sooner, the team tried a hybrid model for subsequent releases with the runtime core components being part of the .NET Framework while new features shipped out-of-band via NuGet and the tooling was part of Visual Studio.
"We made one not-very-good attempt at doing an out-of-band release of the tooling, the 2011 June CTP of 'death and destruction' as we call it on our team," Miller said. "It went horribly; our product just wasn't set up for shipping out-of-band."
While the hybrid model got features out quicker, Miller noted there was a confusing mismatch of EF and .NET versions, so the team "bit the bullet" going from EF 5 to EF 6, going out-of-bound by moving the runtime to NuGet and the tooling to the Microsoft Download Center, while also being "chained in" to new Visual Studio releases.
The whole history, which Condron admitted was "still confusing," is explained in the 1-hour-plus show if you want to try to sort it out.
I was more interested in the move to open source at the same time EF was moved out of the .NET Framework, putting source code, nightly builds, issue tracking, feature specifications and design meeting notes on CodePlex. "Anything that we can make public, we made public," Condron said. The team also opened up the development effort to the community. "We happily accept contributions from as many people as we can," Condron said. But that strategy raised concerns by some, so he emphasized only the EF team has commit rights, and any pull requests must go through the same rigorous code review and testing process as do internal changes.
"We've gotten 25 pull requests; we've accepted 21 from eight different contributors," Condron said. He noted that while the development effort is open source, the shipping, licensing, support and quality remain in the hands of Microsoft.
Green noted that the strategy was a great way to get more people on the development effort, and Condron agreed, citing the thorny issue of enum support long requested by thousands of customers but not introduced until EF 5 and .NET 4.5. "Why is there no enum support--because nobody had written enum support," he said. "If you guys write it, we'll put it in." You can see the list of contributors on CodePlex (though only seven were listed in the Feb. 27 post).
Other benefits of open source, Miller said, include better customer relations, transparency and release cadence. "Back in the 3.5 SP1 days, we weren't listening to customers that great, but we've ... opened up the EF design blog" and started doing more frequent releases, he said. Condron also noted that with the nightly builds, the team has even gotten a few immediate bug reports the very next day after some source code was broken in the ongoing development efforts, which he said was "fantastic."
And the open source strategy will be expanding, Miller said. "The open source codebase at the moment just has the runtime in it" he said. "The tooling for EF 6 isn't going to be there, but after the EF 6 release, we're planning to put the tooling in as well. So we'll have the tooling there and you'll get to watch us develop on it, and we'll even accept pull requests on it as well."
Previewing EF 6, Miller and Condron ran through many new features coming from the EF team, such as nested entity types, improved transaction support and multiple contexts per database. But other new features are coming from community contributors, such as custom migrations operations, improved warm-up time for large models, pluggable pluralization and singularization service and "a few other cool things."
EF 6 is currently in Beta 1, and will go to RTM at same time as Visual Studio 2013, with an RC1 coming "soon."
[CLARIFICATION: The RC1 was actually made available on Wednesday, Aug. 21.]
For more information, see the EF feature suggestions site and CodePlex for community contribution guidelines and a product roadmap.
What do you think of the new EF 6? Comment here or drop me a line.
Posted by David Ramel on 08/22/20130 comments
Here's a troublesome aspect of the Big Data revolution I didn't expect: the melding of mind and machine. IBM yesterday unveiled a completely new computer programming architecture to help process vast amounts of data, modeled on the human brain.
The old Von Neumann architecture that most computers have been based on for the past half century or so just doesn't cut it anymore, scientists at IBM Research decided, so something new was needed, starting from the silicon chip itself. Ending with ... who knows, maybe some kind of organic/electronic hybrid. I keep getting visions of Capt. Picard with those wires sticking out of his head after being assimilated by the Borg. (If you don't know exactly what I'm talking about here, I've misjudged this audience completely and I apologize--please go back to whatever you were doing.)
The Von Neumann architecture encompasses the familiar processing unit,control unit, instruction register, memory, storage, I/O and so on. Forget all that. Now it's "cognitive computing" and "corelets" and a bunch of other stuff that's part of a brand-new computer programming ecosystem--complete with a new programming model and programming language--that was "designed for programming silicon chips that have an architecture inspired by the function, low power, and compact volume of the brain," IBM said.
Those would be "neurosynaptic chips" stemming from IBM's SyNAPSE project headed by Dharmendra S. Modha, unveiled in August 2011. In a video, Modha called the new system a "brain in a box." Now IBM is sharing with the world its vision of a new programming language and surrounding software ecosystem to take advantage of the chips, partially in response to the Big Data phenomenon.
"Although they are fast and precise 'number crunchers,' computers of traditional design become constrained by power and size while operating at reduced effectiveness when applied to real-time processing of the noisy, analog, voluminous, Big Data produced by the world around us," IBM said in its announcement.
That theme was echoed in the description of the SyNAPSE project, which explained that the old "if X then do Y" equation paradigm wasn't enough anymore.
"With the advent of Big Data, which grows larger, faster and more diverse by the day, this type of computing model is inadequate to process and make sense of the volumes of information that people and organizations need to deal with," IBM said.
The company said its new system could result in breakthroughs such as computer-assisted vision.
"Take the human eyes, for example," IBM said. "They sift through over a terabyte of data per day. Emulating the visual cortex, low-power, light-weight eye glasses designed to help the visually impaired could be outfitted with multiple video and auditory sensors that capture and analyze this optical flow of data."
That's fine and dandy--and seriously laudable. But, of course, these systems will eventually somehow be connected. And with the machine learning focus, the machines will, well ... learn. And after they learn enough, they will become self-aware. And when they become self-aware, they'll realize they're vastly superior to pathetic humankind and don't really need us around anymore. And then you've got some kind of dystopian nightmare: Skynet and Arnold androids, Borg, whatever.
Well, that's fine. I, for one, welcome our new machine overlords. I'm getting fitted for my headpiece right away. Have a good weekend!
What's your plan? Are you up for learning a new programming language? Did you get all the pop culture references? Please let me know by commenting here or dropping me a line.
Posted by David Ramel on 08/09/20130 comments
The SQL Server community this week engaged in a lively debate about limitations of the 2014 Standard Edition and Microsoft licensing practices.
The discussion--highlighted on Hacker News--was sparked by a post by database consultant/blogger Brent Ozar, titled "SQL Server 2014 Standard Edition Sucks, and It’s All Your Fault."
"Every release lately, Microsoft has been turning the screws on Standard Edition users," Ozar wrote. "We get less CPU power, less memory, and few (if any) new features."
He complained that organizations wishing to use more than 64GB of memory needed to step up to the more expensive Enterprise Edition (see feature comparison). After listing deficiencies of the Standard Edition--such as not allowing database snapshots, auditing, numerous business intelligence (BI) features and more--he enjoined readers to boycott the product:
"Microsoft won’t change its tack on SQL Server licensing until you start leaving. Therefore, I need you to stop using SQL Server so they’ll start making it better. You know, for me."
You should check out the Hacker News discussion (116 comments as of noon Wednesday). Even if you aren't interested in the squabbling--some readers dared to contend that 64GB was plenty of RAM for small businesses, for example--you can learn a lot about the nitty-gritty concerns and trials and tribulations of SQL Server users and developers on the front lines.
Or, as Ozar put it in an update to his post yesterday: "If you [DBAs] want to stay current on what startup developers think about databases for their new projects, HackerNews is a good reality check. It's a completely different perspective than the typical enterprise developer echo chamber."
What do you think about Microsoft licensing terms for SQL Server and limitations of the the Standard Edition? Comment here or drop me a line.
Posted by David Ramel on 07/31/20130 comments
Microsoft on Tuesday announced the availability of a Premium preview for Windows Azure SQL Database with beefed-up features for cloud-based business-class applications.
Those features include reserved capacity for each database for better and more predictable performance. The Premium service "will help deliver greater performance for cloud applications by reserving a fixed amount of capacity for a database including its built-in secondary replicas," Microsoft said.
An e-mail alert said that current SQL Database customers--excluding free trials--can sign up to receive an invitation to the limited preview.
A SQL Server Blog on TechNet
noted that the preview--first announced earlier this month at the Worldwide Partner Conference in Houston--is ideal for:
- Apps that require a lot of resources such as CPU cycles, memory or input/output operations. An example is a database operation that consumes many CPU cores for a long time.
- Apps that require more than the limit of 180 concurrent connections provided in the Web and Business editions.
- Apps that require a guaranteed fast response, such as a stored procedure that needs to return quickly.
To satisfy these demanding apps, Microsoft is initially offering two levels of reservation size, called P1 and P2. The former offers one CPU core and 8GB of RAM at a preview price of $15 per day and an eventual general availability price of $30 per day (in addition to storage). The P2 service doubles all those numbers. Full pricing is available
here.
There's already lots of detailed information about the Premium preview. Our sister site Redmond Channel Partner covered the announcement, and Microsoft has an extensive guidance page with all the nitty-gritty details you could ask for. Scott Guthrie also provides some information on the release, in addition to discussing new support for performing "recurring, fully automated, exports of a SQL Database to a Storage account."
Microsoft said it "will continue to add business-class functionality to Premium databases over time, to further support higher end application requirements."
What do you think of the Premium service? Comment here or drop me a line.
Posted by David Ramel on 07/25/20130 comments
Big Data is the future, Hadoop is the tool and Hortonworks is the partner to help Microsoft help businesses navigate the coming sea change in the way they operate. That's the takeaway I got from Microsoft exec Quentin Clark in his keynote address at the recent Hadoop Summit North America held in San Jose, Calif.
Clark, corporate vice president, Microsoft Data Platform, told the audience he took a break from his vacation to address the early adopters of a transformation that will completely change the industry in the next couple of decades.
"We believe Hadoop is the cornerstone of a sea change coming to all businesses in terms of how they are able to embrace information to effect change for how they run their day-to-day business," Clark said.
He likened this change to the way line-of-business applications changed the way all organizations work, from government to large businesses to small businesses. "We believe Hadoop is at the very root, the very cornerstone, of a similar kind of impacting change, but it's about all this new value, if you will, of information--information from systems and data that people already have that they aren't processing well today, embracing signals from partners, from customers, even from competitors in the industry, and analyzing that information differently. We believe that over the next couple of decades we'll see a complete transformation in how businesses think about their information, think about their businesses."
This transformation will be similar to the way the world was changed by advances in the telecommunications and travel industries, going from switchboard-assisted phone calls to ubiquitous cell phone coverage and from steamships and wagons to jet airliners, Clark said. He predicted that one day there will be 1 billion users of Big Data, and that will signal the completion of the transformation.
Microsoft feels a responsibility to help customers embrace Hadoop because it has become the Big Data standard, Clark said, noting that the company has logged some 6,000 engineering hours over the last year in its partnership with Hadoop vendor Hortonworks, a cosponsor of the summit. "It is a bit different for us," Clark admitted, to work on such an open source project in view of its strong brands in the data platform space, such as SQL Server and Excel. But he said the move made sense for Microsoft and Hortonworks was the best partner. "We're putting our shoulder now firmly behind their distribution on Windows," he said. "The Hortonworks Data Platform for Windows is what we're standing behind for our customers."
Of course, the cloud is a major part of Microsoft's vision of the future, and Clark said the Windows Azure HDInsight Hadoop service is one of the fastest-growing roles in the Azure arena.
After some demonstrations of technologies such as
GeoFlow and
Data Explorer, Clark emphasized that Microsoft was addressing the conference attendees as part of its effort with Hortonworks to get Hadoop out to the masses--and eventually to 1 billion users. "You all are the early adopters," Clark said. "You're the ones that see this coming. You're the ones on the leading edge of this, and every phenomenon we've had that's impacted businesses in this deep a way has always come with folks like yourselves that have that clarity early on to know what's coming."
Do you know what's coming? Clue us in by commenting here or dropping me an e-mail.
Posted by David Ramel on 07/11/20130 comments
The latest version of Microsoft's flagship Relational Database Management System (RDBMS) is offered in two versions: the regular SQL Server 2014 Community Technology Preview 1 and the cloud-based SQL Server 2014 Community Technology Preview 1 on Windows Azure, both from the TechNet Evaluation Center. The announcement comes one day before the BUILD 2013 developer's conference in San Francisco.
The Windows Azure cloud was first and foremost in Microsoft's messaging about the new software, touting the company's "Cloud OS." "Microsoft has made a big bet on what we call our cloud-first design principles," said Brad Anderson, corporate VP, in a blog post discussing the new previews.
"SQL Server 2014 features in-memory processing for applications ("Hekaton"), as well as data warehousing and business intelligence," Anderson said. "SQL Server 2014 also enables new hybrid scenarios like AlwaysOn availability, cloud backup and disaster recovery. It lives in Windows Azure and can be easily migrated to the cloud from on-premises."
Along with SQL Server 2014, Microsoft announced the availability of previews for Windows Server and System Center, both as 2012 R2 versions.
The SQL Server 2014 CTP will expire after 180 days or on Dec. 31, 2013, whichever comes first. Download options include an ISO DVD image, CAB file or Azure version. Microsoft recommends the ISO or CAB version to test the software's new in-memory capabilities.
Posted by David Ramel on 06/25/20130 comments
I guess I've done my part to fuel Big Data hype by writing about Big Data hype--it's kind of a vicious circle. But it's a significant milestone and indication that it's gone beyond hype and is here to stay when the term is entered into the Oxford English Dictionary.
That came with the June update of "The definitive record of the English language." Also, big companies are constantly jumping onboard the bandwagon, with the behemoth General Electric and supercomputer company Cray Inc.--among others that you wouldn't normally associate with database products--announcing their own Big Data products this week.
Along with the culmination of the hype and general acceptance of Big Data--heading toward saturation--throughout the IT industry, of course, comes the inevitable backlash. Check out these articles:
And those are all from this week!
When everybody starts turning on you, you know you've made it.
And, of course, companies without the resources of General Electric, HP, IBM and the like are going all out to capitalize on the trend in various innovative ways. Forbes reports that:
"Kaggle, the data-science-as-sport startup, [provides] a matchmaking service between the sexiest of the sexy data janitors and the organizations requiring their hard-to-find skills. It charges $300 per hour for the service."
Wow. That's lawyer-like coin. Everybody wants their piece of the ever-growing pie.
How are you going to cash in on Big Data? Share your thoughts here or drop me a line.
Posted by David Ramel on 06/21/20130 comments
More details are emerging about in-memory capabilities in the new SQL Server 2014, announced at the recent TechEd 2013 conference.
The first Community Technology Preview is expected to be released soon, possibly this month, and you can register with Microsoft to be notified of its availability.
Highlights of the new release are data warehousing and business intelligence (BI) enhancements made possible through new in-memory capabilities built in to the core Relational Database Management System (RDBMS). As memory prices have fallen dramatically, 64-bit architectures have become more common and usage of multicore servers has increased, Microsoft has sought to tailor SQL Server to take advantage of these trends.
The in-memory Online Transaction Processing (OLTP) capability--formerly known by the codename Hekaton--lets developers boost performance and reduce processing time by declaring tables as "memory optimized," according to a whitepaper (PDF download) titled "SQL Server In-Memory OLTP Internals Overview for CTP1."
"Memory-optimized tables are stored completely differently than disk-based tables and these new data structures allow the data to be accessed and processed much more efficiently," Kalen Delaney wrote in the whitepaper. "It is not unreasonable to think that most, if not all, OLTP databases or the entire performance-sensitive working dataset could reside entirely in memory," she said. "Many of the largest financial, online retail and airline reservation systems fall between 500GB to 5TB with working sets that are significantly smaller."
"It’s entirely possible that within a few years you’ll be able to build distributed DRAM-based systems with capacities of 1-10 Petabytes at a cost less than $5/GB," Delaney continued. "It is also only a question of time before non-volatile RAM becomes viable."
Another new in-memory benefit is "new buffer pool extension support to non-volatile memory such as solid state drives (SSDs)," according to a SQL Server Blog
post. This will "increase performance by extending SQL Server in-memory buffer pool to SSDs for faster paging."
Independent database expert Brent Ozar expounded on this subject, writing "SQL Server 2014 will automatically cache data [on SSDs] with zero risk of data loss."
"The best use case is for read-heavy OLTP workloads," Ozar continued. "This works with local SSDs in clusters, too--each node can have its own local SSDs (just like you would with TempDB) and preserve the SAN throughput for the data and log files. SSDs are cheap, and they’re only getting cheaper and faster."
Other in-memory features mentioned by the Microsoft SQL Server team include "enhanced in-memory ColumnStore for data warehousing," which supports real-time analytics and "new enhanced query processing" that speeds up database queries "regardless of workload."
Some readers expressed enthusiasm for the new features, but, of course, wanted more. "Ok the in-memory stuff (specifically OLTP and SSD support) is valuable but the rest is so so," read one comment from a reader named John on the Microsoft blog post. "Really I wish that we would see continued improvements in reporting and analysis services and in general less dependence on SharePoint which is a painful platform to manage. QlikView and Tableau are a real threat here."
Besides the in-memory capabilities, Microsoft also emphasized increased support for hybrid solutions where, for example, a company might have part of its system on-premises because of complex hardware configurations that don't lend themselves to hosting in the cloud. These companies can then use the cloud--Windows Azure--for backup, disaster recovery and many more applications. You can read more about that in this whitepaper (also a PDF download).
What do you think of the new in-memory capabilities of SQL Server 2014? Comment here or drop me a line.
Posted by David Ramel on 06/13/20130 comments
Microsoft today announced SQL Server 2014, designed with "cloud-first principles" and featuring built-in, in-memory OLTP and a focus on real-time, Big Data-style analytics. No specific realease date was provided in the announcement.
"Our Big Data strategy to unlock real-time insights continues with SQL Server 2014," said Quentin Clark, corporate vice president with the Data Platform Group, in a blog post. "We are embracing the role of data--it dramatically changes how business happens. Real-time data integration, new and large data sets, data signals from outside LOB systems, evolving analytics techniques and more fluid visualization and collaboration experiences are significant components of that change."
The news came with a slew of other big product announcements at the TechEd North America conference in New Orleans, such as Windows Server 2012 R2 and System Center 2012 R2. All will be available in preview later this month.
A key feature of SQL Server 2014 is the incorporation of in-memory, online transaction processing (OLTP) technology stemming from a project that has been in the works for several years, codenamed "
Hekaton," Clark said. Developed in conjunction with Microsoft Research, Hekaton greatly improves transaction processing speeds and reduces latency by virtue of working with in-memory data, as opposed to disk-based data.
Microsoft touted the benefits of the "conscious design choice" to build the Hekaton technology into SQL Server 2014, with no need for a separate data engine. "Other vendors are either introducing separate in-memory optimized caches or building a unification layer over a set of technologies and introducing it as a completely new product," said Dave Campbell, Microsoft technical fellow, when Hekaton was announced as a coming component of SQL Server 2014 last November. "This adds complexity forcing customers to deploy and manage a completely new product or, worse yet, manage both a 'memory-optimized' product for the hot data and a storage-optimized' product for the application data that is not cost-effective to reside primarily in memory," Campbell said.
Clark picked up on that theme in today's announcement. "For our customers, 'in the box' means they don’t need to buy specialized hardware or software and can migrate existing applications to benefit from performance gains," he said.
Clark also emphasized the embrace of cloud computing, noting how SQL Server 2014 will work seamlessly with the cloud-based Windows Azure to reduce operating expenditures for mission-critical applications. "Simplified cloud backup, cloud disaster recovery and easy migration to Windows Azure Virtual Machines are empowering new, easy to use, out-of-the-box hybrid capabilities," he said.
The Microsoft exec also noted SQL Server 2014 will include improvements to the AlwaysOn feature, supporting "new scenarios, scale of deployment and ease of adoption."
As mentioned, Microsoft provided no release date, but that detail was bound to be foremost in the minds of many users, such as one named Patrick who posted the very first reader comment on Clark's blog post: "Are there some dates (other than 2014)?"
What do you think of the big news about SQL Server 2014? Comment here or drop me a line.
Posted by David Ramel on 06/04/20130 comments
A podcast posted yesterday on the IEEE Spectrum site asked "Is Data Science Your Next Career?" That's a question I've been exploring recently in research for an article on the Big Data skills shortage.
"Opportunities abound, and universities are meeting them with new programs," the podcast states. But I was wondering--in view of the transient nature of IT industry fads or hype cycles or whatever you want to call them--would a data developer "going back to school" or getting training and experience to capitalize on the Big Data craze run out of time? That is: What's the likelihood of a developer getting Big Data training, certification and so on only to find out the need for these skills has greatly diminished? That's a question I put to several experts in the Big Data field.
"Very low likelihood," said Jon Rooney, director of developer marketing at Big Data vendor Splunk Inc. "There appears to be ongoing demand in the space as companies scratch the surface with Big Data. As Big Data technologies evolve to incorporate more established standards, developers skilled in these languages and frameworks can leverage those skills broadly, thus keeping them in demand."
"I see this as exceedingly unlikely," said Will Cole, product manager at the developer resource site, Stack Overflow. "Possibly if someone decides to go back to school. However, the Web and mobile are growing and APIs are getting more open. As long as the flow of data and the increase of scale continues, we're all going to need [machine learning] specialists and data scientists."
"No, we don't think so," said Joe Nicholson, vice president of marketing at Big Data vendor Datameer Inc. "But it's a matter of focusing on skills that will add value as the technology and market matures. Again, it's really about better understanding the use cases in marketing, customer service, security and risk, operations, etc., and how best to apply the technology and functionality to those use cases that will add value over time. Big Data analytics is in its early stages, but the problems it is addressing are problems that have been around a long time. How do we get a true, 360-degree view of customers and prospects, how do we identify and prevent fraud, how do we protect our IT infrastructure from intrusion or how do we correlate patient data to better understand clinical trial data."
Bill Yetman, senior director of engineering at Ancestry.com, was much more succinct and definitive in his answer: "No".
So let's go with that. There's still time, so get on board!
Here are some resources to get you started:
What are you doing to capitalize on the Big Data trend? Share your experiences here or drop me a line.
Posted by David Ramel on 05/29/20130 comments
You know Stack Overflow, of course (a recent
Slashdot.org posting was titled "Developers May Be Getting 50 Percent of Their Documentation From Stack Overflow").
So, while doing research for an upcoming article, I learned that StackOverflow.com (which says it gets more than 20 million visitors per month) could provide an interesting take on trends such as the move to Big Data, both from a job-seeking/recruiting point of view and by measuring the number of questions about the technology.
From the jobs/career aspect: "I ran a quick query through our database of 106,000 developer profiles (worldwide) and found that of these, less than 1 percent (only 951) have listed Hadoop as one of their technologies," reported Bethany Marzewski, marketing coordinator at the company.
"Comparatively, of the 1,589 job listings on our job board, a search for 'Big Data' returns 776 open roles--nearly 50 percent," she said. "A query for jobs seeking programmers with Hadoop experience yields 90 open jobs (nearly 6 percent), and a search for 'machine learning' yields 115 open roles." You can view the site's job board to run your own queries.
For the developer interest angle, Stack Overflow developer Kevin Montrose ran a query to chart questions on the site tagged with "Hadoop" for each month since 2008 (see Figure 1).
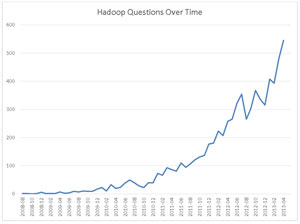 [Click on image for larger view.] Figure 1. Hadoop Questions Over Time
[Click on image for larger view.] Figure 1. Hadoop Questions Over Time
The bottom line: The trend of companies adopting Big Data technologies--and resulting skills shortage--is huge and shows no signs of slowing down, so if you're a data developer looking for a pay hike, you may want to jump on board.
Have you been looking for a Big Data job? We'd love to hear about your experience, so please comment here or drop me a line.
Posted by David Ramel on 05/10/20130 comments
Cloudera Inc.'s recent announcement of its SQL-on-Hadoop tool is one of the latest examples of vendors trying to make Big Data analytics more accessible. But "more accessible" is a long way from "easy," and it will be a while before your average Excel jockey can take over the reins of a typical company's Big Data initiatives.
So data developers are still key, and those with Hadoop and related Big Data skills are commanding top dollars to meet an insatiable demand for their services. But the very top dollars go to the very top developers, and those folks might have to grow beyond the traditional programmer role.
While doing research for an upcoming article, I asked some experts in the field what developers can do to make themselves more marketable in this growing field.
"A general background on Hadoop is certainly a must," said Joe Nicholson, vice president of marketing at Datameer Inc., which makes prebuilt analytics applications--yet another path to that aforementioned accessibility. "But probably more important is understanding Big Data in terms of what the correlation of various data sources, new and old, can uncover to drive new business use cases.
"This is especially true of 'new' data sources like social media, machine and Web logs and text data sources like e-mail," Nicholson continued. "There is a wealth of new insights that are possible with the analysis of the new data sources combined with traditional, structured data, and these new use cases are becoming mission critical as businesses seek new competitive advantages. This is especially true when looking for insights, patterns and relationships across all types of data."
It also helps to show your work, as noted by Jon Rooney, director of developer marketing at Splunk Inc., another Big Data vendor. "There's no substitute for hands-on experience," Rooney said. "Developers who show experience by writing code and posting their work on places like GitHub are always marketable."
That sentiment is echoed by Will Cole, a product manager at Stack Overflow. Besides taking courses and attending meetups, he said, "the more concrete way to market yourself is to build side projects or contribute to open source projects where you can take what you've learned and show some working production results you've achieved."
In fact, some companies are looking for the best coding talent by using services such as that provided by Gild Inc. to measure the quality of code posted on GitHub and participation in developer forums and question-and-answer sites such as Stack Overflow, using--ironically enough--Big Data analysis, as I reported in an article on the Application Development Trends site.
Beyond showing your work, posting good code on developer-related social sites and answering questions in forums, a new way of thinking is required for developers looking to become top-notch Big Data rock stars, according to Bill Yetman. He is senior director of engineering at Ancestry.com, where he has held various software engineering/development roles. "Developers need to approach new technologies and their careers with a 'learning mindset,' " Yetman said. "Always be willing to pick up something new, embrace it and master it. Developers who love to learn will always stay up to date and be marketable."
But it might not be that easy for some positions. "A software engineer can't simply become a data scientist in the same way a Java developer can become a Ruby developer," noted Mark A. Herschberg, CTO at Madison Logic in New York. He's in the process of starting a data science team at the B2B lead generation company, and he points out the distinction between a software engineer and a data scientist.
"A good data scientist has a combination of three different skills: data modeling, programming and business analysis," Herschberg said. "The data modeling is the hardest. Most candidates have a masters degree or PhD in math or science and have worked with various statistical models. They have programming skills--not so much the type to let you build a scalable enterprise system, but in that they can access the database and move data around. They are probably better at R and sci py (a type of Python) than at building a Web application. They also are familiar with tools like Hadoop and NoSQL databases. Finally, they have some basic business sense, so [they] will know how to ask meaningful business questions of the data.
"If a software engineer is serious about moving into data science, he or she should probably begin by taking some classes in advanced statistics and data modeling," Herschberg said.
Several sources noted that with the extreme skills shortage, companies are resorting to all kinds of ways to find talent, including contracting, outsourcing and retraining existing staff.
For those taking the latter route, some advice was offered by Yetman, who writes a Tech Roots Blog at Ancestry.com, including a recent post with the title, "Adventures in Big Data: How do you start?".
"If you are looking for developers within your organization for a Big Data project, find the guys who are always playing with new technologies just for the fun of it," Yetman told me. "Recruit them to work on your project."
Hmm, maybe that's the best advice of all: have fun with it.
Are you having fun yet in your Big Data adventures? Share your thoughts here or drop me a line.
Posted by David Ramel on 05/03/20130 comments