Code Focused
4 Ways To Transform a File on Windows with C++
On the Windows platform, the C++ language offers several ways to process a file. We'll look at four approaches for serial IO access.
- By Bartlomiej Filipek
- 01/26/2017
Reading and writing to a file is one of the most required features of any standard library for a language or an OS API. Many times I've used different methods to perform IO, but I haven't got a chance to compare them or look deeper.
In this article, I'll present an implementation of one quite simple IO problem, but done using four different options: API of the C standard library, C++ Standard Library and two from the Windows API. This will be a background for the next article where we'll discuss performance of the APIs.
In the implementation, we can also look at modern C++ techniques, especially resource management.
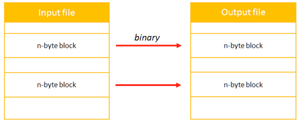
To present all the IO access methods I've created an application that transforms an input file into an output file using binary mode, converting block of bytes by block (you can see all the code at this link on GitHub). The size of the block can be configured, as shown in Figure 1.
 [Click on image for larger view.]
Figure 1: Transform Operation: Binary Process Block By Block; Each Block is N-Byte (Parameter)
[Click on image for larger view.]
Figure 1: Transform Operation: Binary Process Block By Block; Each Block is N-Byte (Parameter)
The method that processes each block is not relevant since we want to focus on the IO access mostly. It might be a binary copy or a cipher operation.
The application is simplified, so we assume that the output file will be the same size as the input. Later, as an extension, we can discuss potential improvements: ability to merge several inputs into one output file, allowing to produce different output block size or more.
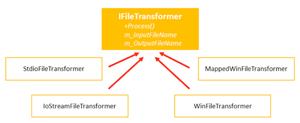
The example is built in the following way: First, an interface IFileTransformer specifies input file name, output file name, Process() method.
Then, there are four separate implementations of the interface:
- StdioFileTransformer uses C CRT api, standard stdio access
-
IoStreamFileTransformer implementation using C++ STD library, Streams
-
WinFileTransformer WinApi basic file access
-
MappedWinFileTransformer WinApi with memory mapped files
And finally, the program runs in console mode and it takes arguments about file names, block size, used API.
Figure 2 shows the class diagram.
 [Click on image for larger view.]
Figure 2: Four Implementations of the iFileTransformer Interface
[Click on image for larger view.]
Figure 2: Four Implementations of the iFileTransformer Interface
Now, let's look at the implementation of each Transformer.
CRT C API
In the Standard Library for the C language, there's a good old header file called stdio.h. It gives low-level access to a file, both in binary or text mode. Here's the quick summary of what we have in the package:
-
We operate on streams of data, using the FILE opaque pointer type.
-
Streams are buffered by default:
- You can control buffer mode and size by calling setvbuf()
- The default size of the buffer - BUFSIZ constant - should be the most efficient buffer size for file I/O on the implementation. For example, on Windows it's defined as 512 (bytes).
-
API is multiplatform, the same code will compile on Windows, Linux…and should produce the same effects.
-
There's no a direct way to random access a file. Instead, we need to seek, read/write manually and then seek again to a different position.
As for the reference, there's an even "lower" level API that could be mentioned here. It gives only basic methods without buffering and it's POSIX standard. The API is specified in the io.h header file (or unistd.h in Linux-based libraries; read more about low-level I/O here).
Let's see how the Transformer for stdio is implemented. First we open two files:
FILE_unique_ptr pInputFilePtr = make_fopen(m_strFirstFile.c_str(), L"rb");
if (!pInputFilePtr)
return false;
FILE_unique_ptr pOutputFilePtr = make_fopen(m_strSecondFile.c_str(), L"wb");
if (!pOutputFilePtr)
return false;
C Streams operate using FILE handles. First we need to open it (via fopen()) and then close (via fclose()). In my example I wrapped those calls into an RAII object, which will make sure the stream is closed even on error. In the code above I leverage RAII based on std::unique_ptr, there's custom deleter provided that closes the stream when it's out of scope. You can read more about custom deleters for smart pointers on my blog.
Later, there are two buffers created:
auto inBuf = make_unique<uint8_t[]>(m_blockSizeInBytes);
auto outBuf = make_unique<uint8_t[]>(m_blockSizeInBytes);
Again, unique_ptr is used to guard memory allocation and deletion. According to modern C++, we shouldn't be using raw new and delete so that's why make_unique (a C++14 library function) is invoked in the example.
Note, for simplicity I am not checking memory errors here, and I assume the block fits into memory.
Finally, there's the processing loop in Listing 1.
Listing 1: Processing Loop
size_t blockCount = 0;
while (!feof(pInputFilePtr.get()))
{
const auto numRead = fread_s(inBuf.get(), m_blockSizeInBytes,
/*element size*/sizeof(uint8_t), m_blockSizeInBytes, pInputFilePtr.get());
if (numRead == 0)
{
if (ferror(pInputFilePtr.get()))
{
// error...
return false;
}
break;
}
processFunc(inBuf.get(), outBuf.get(), numRead);
const auto numWritten = fwrite(outBuf.get(), sizeof(uint8_t), numRead, pOutputFilePtr.get());
if (numRead != numWritten)
{
// error...
}
blockCount++;
}
The above example shows the core processing loop: we read a block of bytes, transform it into the output buffer (using processFunc) and then save the buffer into the output file.
Please note that additionally I am using secure versions of CRT functions for Streams. Thus fopen_s() and fread_s() instead of fopen() and fread(). The functions offer better parameter validation, and they require buffer size is passed to any function that writes to a buffer to avoid buffer overrun errors.
The CRT version seems to be really easy to implement, let's now move to te C++ version. At the end, we'll compare all solutions.
C++ Streams
In the Standard Library for C++, we get IO API that is object oriented and offers the following features:
-
Stream objects wrap file handle in RAII by default.
- They support exceptions if set (by default it's disabled)
- rvalue and move semantics is enabled (so you can just return stream, and it will be properly moved into outside object, previously pointer param would be needed)
- Much more flexibility with formatted IO thanks to formatters and custom formatters.
- There's a control if C++ Streams should be synced with CRT or not (via sync_with_stdio()); by default syncing is enabled.
- You can control buffered mode with rdbuf() and then operating on raw buffer object.
- There's an option to use custom buffer object.
Let's now look at the implementation of the file transformer using C++ streams, first with opening files:
ifstream inputStream(m_strFirstFile, ios::in | ios::binary);
if (inputStream.bad())
return false;
ofstream outputStream(m_strSecondFile, ios::out | ios::binary | ios::trunc);
if (outputStream.bad())
return false;
Listing 2 shows how to process those two opened files.
Listing 2: Processing Two Opened Files
size_t blockCount = 0;
while (!inputStream.eof())
{
inputStream.read((char *)(inBuf.get()), m_blockSizeInBytes);
if (inputStream.bad())
return false;
const auto numRead = static_cast<size_t>(inputStream.gcount());
processFunc(inBuf.get(), outBuf.get(), static_cast<size_t>(numRead));
const auto posBefore = outputStream.tellp();
outputStream.write((const char *)outBuf.get(), numRead);
if (outputStream.bad())
return false;
blockCount++;
}
The main processing loop is not shorter than the C example. In fact, we have to compute more to calculate a number of bytes written to a file. To do that we have to use position in the file before the write and after (see the call to outputStream.tellp()). Also, to get a number of bytes read we need to use inputStream.gcount(). I think, I prefer the C API, where a number of bytes read and written is returned from the corresponding function call.
Basic WinAPI
The two previously described methods were multiplatform and are supported by the Standard library for C or C++. Still, for a lot of applications such the two APIs are good enough. However if your application is designed specifically for the Windows platform, there's a native API for IO that will give you a lot of options.Here's a summary:
- To process a file we can use CreateFile(), ReadFile() and WriteFile() functions.
- Each file is represented by a kernel object, you get a HANDLE after a file is created/opened.
- As other kernel objects, you need to CloseHandle() to release the resource.
- Long filenames (with more than 260 characters) are supported (read more about this problem on MSDN)
- Windows uses Cache Manager and caches all opened files (you can work with unbuffered files by taking benefit from the FILE_FLAG_NO_BUFFERING flag)
- There's no way to process a file using TEXT mode; you just get binary mode.
- The API allows for creating asynchronous/multithreaded processing using OVERLAPPED structures.
Listing 3 shows the code for opening files.
Listing 3: Opening Files via the Native Windows API
auto hIn = CreateFile(m_strFirstFile.c_str(),
GENERIC_READ,
/*shared mode*/0,
/*security*/nullptr,
OPEN_EXISTING,
FILE_ATTRIBUTE_NORMAL,
/*template*/nullptr);
auto hOut = CreateFile(m_strSecondFile.c_str(),
GENERIC_WRITE,
/*shared mode*/0,
/*security*/nullptr,
CREATE_ALWAYS,
FILE_ATTRIBUTE_NORMAL,
/*template*/nullptr);
I wrap them into RAII objects, to make sure the CloseHandle() method is called when objects go out of scope:
auto hOInputFile = make_HANDLE_unique_ptr(hIn);
auto hOutputFile = make_HANDLE_unique_ptr(hOut);
Listing 4 has the main processing loop.
Listing 4: Main Processing Loop
while (ReadFile(hInputFile.get(), inBuf.get(),
static_cast<DWORD>(m_blockSizeInBytes), &numBytesRead, /*overlapped*/nullptr)
&& numBytesRead > 0 && writeOK)
{
processFunc(inBuf.get(), outBuf.get(), numBytesRead);
writeOK = WriteFile(hOutputFile.get(), outBuf.get(), numBytesRead, &numBytesWritten, /*overlapped*/nullptr);
if (numBytesRead != numBytesWritten)
return false;
blockCount++;
}
The main processing loop seems to be the shortest one. It's easier than C or C++ version.
Memory-Mapped Files
I went one step further with Windows API for IO to show one method that has a powerful behavior and might be the fastest in some cases: It's the memory-mapped files technique (MMF). MMF can be characterized by the following features:
-
File is mapped into virtual memory. The management of reads and writes is left to the virtual memory manager (so very optimized).
-
You get a regular pointer to memory so you can operate freely on that memory. Since you just have a pointer you can avoid many system calls like WriteFile or ReadFile.
-
Performance might be improved especially for large files and in cases where there's a lot of random access (working in RAM is several orders of magnitude faster than using random access in a physical file on disk).
-
MMF is a common mechanism of implementing shared memory between two processes, or, in other words, interprocess communication.
-
MMF is also used to load a dynamic library.
MMF is the more advanced technique, so we need to execute a few more steps:
- Open a file using the regular CreateFile method
-
Create a file mapping using CreateFileMapping(). This function returns a HANDLE so we need to close it via CloseHandle().
-
Create a view using MapViewOfFile(). At the end we have to use corresponding UnmapViewOfFile() function to release the view.
- An SEH exception might happen so we need to additionally support this.
-
Length of a file cannot be extended when it's mapped.
Listing 5 shows how I open a mapping for input file.
Listing 5: Opening a Mapping
hInputMap = make_HANDLE_unique_ptr(
CreateFileMapping(hInputFile.get(), NULL,
PAGE_READONLY, /*size high*/0, /*size low*/0, NULL), L"Input map");
if (!hInputMap)
return false;
/* Map the input file */
ptrInFile = (uint8_t*)MapViewOfFile(hInputMap.get(),
FILE_MAP_READ, 0, 0, 0);
if (ptrInFile == nullptr)
return false;
We can pass 0 and 0 for high and low parts of the file size so that the whole file will be mapped.
And Listing 6 has the code for the output file.
Listing 6: Output File
hOutputMap = make_HANDLE_unique_ptr(
CreateFileMapping(hOutputFile.get(), NULL,
PAGE_READWRITE, fileSize.HighPart, fileSize.LowPart, NULL), L"Output map");
if (!hOutputMap)
return false;
ptrOutFile = (uint8_t*)MapViewOfFile(hOutputMap.get(),
FILE_MAP_WRITE, 0, 0, (SIZE_T)fileSize.QuadPart);
if (ptrOutFile == nullptr)
return false;
In this case, we're passing the desired size of the file (taken from the input file). We cannot give 0 since the file might be empty and in that case the function will fail.
Now, we have two pointers in the memory ptrInFile and ptrOutFile we can just work on them almost like regular pointers. All we have to do additionally is to remember SEH exceptions.
I wrapped the processing into a separate method, shown in Listing 7.
Listing 7: Separate Method for Processing
size_t bytesProcessed = 0;
size_t blockSize = 0;
__try
{
pIn = ptrInFile;
pOut = ptrOutFile;
while (pIn < ptrInFile + fileSize.QuadPart)
{
blockSize = static_cast<size_t>(static_cast<long long>(bytesProcessed + m_blockSizeInBytes) < fileSize.QuadPart ? m_blockSizeInBytes : fileSize.QuadPart - bytesProcessed);
processFunc(pIn, pOut, blockSize);
pIn += blockSize;
pOut += blockSize;
bytesProcessed += m_blockSizeInBytes;
}
return true;
}
__except (GetExceptionCode() == EXCEPTION_IN_PAGE_ERROR ? EXCEPTION_EXECUTE_HANDLER : EXCEPTION_CONTINUE_SEARCH)
{
// error!
}
return false;
Although, for our example, memory-mapped files might be too complicated but it's an interesting experiment to see how we can just use regular pointers to do the processing. All the magic is done by the virtual memory manager of the system.
Which One Is Best?
So, what method should you choose in your applications? I think, several factors might affect your final decision.
First of all, if you write an application that already uses OS API - like an app that relies on WinAPI, then the natural choice would be also to use WinAPI. On the other hand, if your code is written in generic C++ way (multiplatform), then you can just stay with C++ Streams or stdio libraries.
Another important factor is the need to process data in text or binary mode. Since the Windows API doesn't allow TEXT mode, you would have to implement your text conversions. In that case, it's probably easier just to stick with C++ or C libraries since they support TEXT mode. I'd say that C++ Streams are usually the most advanced and easier to use in text mode.
Another thing you might consider the type of advanced IO management you need. C++ and C libraries offer good file access -- there's even buffer control -- but they won't give you all the options as the Windows API does. In WinAPI you can create memory-mapped files or perform async IO, and there's better support for threads. If you want to do the same in generic C++, you need to reach for some third-party libraries (like boost). If we look at those APIs regarding ease of use C++ Standard Library might be the best choice. By default, it offers file handle management which other APIs lack.
In the next article, we'll look at the performance of all of the above methods. What's the fastest way to process a file? As you can see, there are many factors that have an impact on the speed: block size, file buffering, system caching, the number of system calls, so it's worth spending a bit more time and discuss the factors.
Summary
In the article, I've covered implementation of a simple problem: transforming an input file into output byte by byte using four APIs available on Windows. You could see what are the essential features of those implementations. For example, C++ Streams offers RAII by default, while Windows API gives tons of different options to configure a file processing (including memory mapped files that we've also used).
I've skipped one important part: the performance characteristics of the APIs. We have the basic knowledge, so we'll tackle performance next time.
As I mentioned, the code in the article was based on serial, single-threaded access. IO methods are synchronous, meaning that the main thread is waiting until the IO operation is finished. As a logical extension, we could try using asynchronous methods and see what benefit they bring.
Also, we could have a more complex relation between an input file and output file: merge several inputs into one output, allow to have different sizes or more.