The Data Science Lab
Getting Started with AutoML for ML.NET
Dr. James McCaffrey provides hands-on examples in introducing ML.NET, for machine learning prediction models, and AutoML, which automatically examines different ML algorithms, finds the best one, and creates a Visual Studio project with the C# code backing the best model, along with C# code that shows how to use the trained model to make a prediction.
Microsoft ML.NET is a code library for .NET Core (the multi-platform version of the .NET Framework). The ML.NET library allows you to use C# to create, train, and use three types of machine learning prediction models: multiclass classification, binary classification, and regression. Directly writing programs that use ML.NET is quite difficult. The new AutoML system has a command-line tool that automatically examines different machine learning algorithms, finds the best algorithm, and creates a Visual Studio project that has the C# code that generated the best model, along with C# code that shows how to use the trained model to make a prediction. Quite remarkable.
 [Click on image for larger view.]
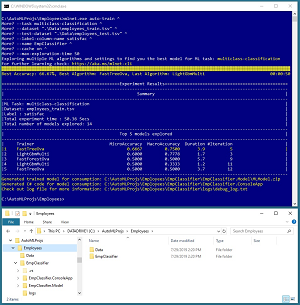
Figure 1. AutoML for ML.NET in Action and Directory Structure
[Click on image for larger view.]
Figure 1. AutoML for ML.NET in Action and Directory Structure
The best way to understand what AutoML for ML.NET is and to see where this article is headed is to take a look at the screenshot in Figure 1. The goal of the demo is to create a machine learning model that predicts the job satisfaction of an employee at a hypothetical company. There is a 40-item file of training data and a 10-item file of test data. Both files look like:
False 66 mgmt 52100.00 low
True 35 tech 86100.00 medium
False 24 tech 44100.00 high
True 43 sale 51700.00 medium
. . .
Each line represents an employee. The value in the first column indicates if the employee is paid an hourly rate (True) or is paid by salary. The second column is employee age. The third column is job type. The fourth column is annual income. The fifth column is the employee's job satisfaction.
The prepare the demo, I installed 1.) Visual Studio 2019, 2.) the .NET Core SDK, and 3.) the ML.NET CLI (command-line interface) tool. Then I issued a rather lengthy command that starts with "mlnet.exe auto-train" and is followed by seven arguments.
The caret ("hat") character is used for line continuation in a command shell. The AutoML tool analyzed the training data, used the ML.NET library to explore several variations of five different machine learning algorithms, identified the best algorithm ("FastTreeOva"), and saved this best one as a model.
To summarize, AutoML is a tool/parameter named auto-train that's part of the mlnet.exe command-line tool. The combined tools call into the ML.NET library, running in .NET Core, using the .NET Core SDK. Notice there isn't a specific "AutoML" entity. The term AutoML was used in pre-release versions of the system and still appears in much of the documentation. The system is also called AutomatedML and auto-train.
After identifying the best multiclass classification algorithm and saving the trained model, the AutoML tools created two Visual Studio projects in a subdirectory named EmpClassifier. The first project is named EmpClassifier.ConsoleApp.csproj, which has the C# code that created and trained the best model, and C# code that calls the trained model to make a prediction. The second project is named EmpClassifier.Model.csproj, which, somewhat confusingly, is essentially a duplicate of the first project and is there for backward-compatibility reasons.
Installing the AutoML for ML.NET Components
To use AutoML for ML.NET the first step is to install Visual Studio 2019 if you don't already have it on your machine. Go here and select the 2019 Community (free) edition option. This will install a Visual Studio Installer utility program that allows you to customize Visual Studio with different capabilities in modules called workloads. Because AutoML for ML.NET is based on .NET Core, you only need the ".NET Core cross-platform development" workload, but I recommend installing the traditional ".NET desktop development" workload too. Launch VS 2019 from the Windows Start menu to verify the installation. If you ever need to uninstall VS 2019, you can do so through the VS Installer program.
Next you need the .NET Core SDK. Go here and select the "Download .NET Core SDK" option. This will download a self-extracting executable named something like dotnet-sdk-2.2.1-win-x64.exe. When you run it, you will get the SDK so you can develop .NET Core programs and the runtime so you can run .NET Core programs. I installed version 2.2.1, but by the time you read this there could be a newer version available. After installing the SDK and runtime, launch a command shell and enter "dotnet --version" to verify the installation. If you ever need to uninstall the SDK, you can do so through the Control Panel Add/Remove Programs GUI interface.
The third step is to install the ML.NET CLI tool, which also includes the ML.NET library. Make sure your machine is connected to the Internet. Launch a command shell and enter "dotnet tool install -g mlnet". The -g argument stands for global. This command will magically install program mlnet.exe in the C:\Users\<user>\.dotnet\tools directory and update your system PATH environment variable to point to the program. You will also get the ML.NET library installed so you don't need to install it separately. Launch a command shell and enter "mlnet --version" to verify the installation. If you ever need to uninstall the ML.NET CLI tool, you can do so from the command line by entering "dotnet tool uninstall mlnet -g".
Preparing Data for ML.NET
The 40-item training dataset and 10-item test dataset are shown in Listing 1. The files are tab-separated and are named employees_train.tsv and employees_test.tsv. The ML.NET library also supports comma-separated files with a .csv extension, and space-separated files with a .txt extension.
Listing 1. Training and Test Data
hourly age job income satisfac
False 66 mgmt 52100.00 low
True 35 tech 86100.00 medium
False 24 tech 44100.00 high
True 43 sale 51700.00 medium
True 37 mgmt 88600.00 medium
True 30 sale 87900.00 low
False 40 mgmt 20200.00 medium
False 58 tech 26500.00 low
True 27 mgmt 84800.00 low
False 33 sale 56000.00 medium
True 59 tech 23300.00 high
True 52 sale 87000.00 high
False 41 mgmt 51700.00 medium
True 22 sale 35000.00 high
False 61 sale 29800.00 low
True 46 mgmt 67800.00 medium
True 59 mgmt 84300.00 low
False 28 tech 77300.00 high
True 46 sale 89300.00 medium
False 48 tech 29200.00 medium
False 28 mgmt 66900.00 medium
False 23 sale 89700.00 high
True 60 mgmt 62700.00 high
True 29 sale 77600.00 low
True 24 tech 87500.00 high
False 51 mgmt 40900.00 medium
True 22 sale 89100.00 low
True 19 tech 53800.00 low
False 25 sale 90000.00 high
True 44 tech 89800.00 medium
True 35 mgmt 53800.00 medium
True 29 sale 76100.00 low
False 25 mgmt 34500.00 medium
False 66 mgmt 22100.00 low
False 43 tech 74500.00 medium
True 42 sale 85200.00 medium
True 44 mgmt 65800.00 medium
False 42 sale 69700.00 medium
True 56 tech 36800.00 high
True 38 mgmt 26000.00 low
hourly age job income satisfac
True 50 mgmt 54700.00 medium
False 67 tech 32000.00 low
False 23 sale 75100.00 high
True 18 tech 79500.00 low
False 33 mgmt 62100.00 medium
True 47 sale 46500.00 medium
True 59 sale 74200.00 high
True 51 tech 49700.00 medium
False 33 tech 26300.00 medium
False 35 mgmt 83000.00 high
Notice that Boolean values are encoded as True or False rather than 0 or 1, which is common in other libraries. Both data files have a tab-separated header line of (hourly, age job, income, satisfac). Header lines are not required but are recommended. The dependent variable to predict can be placed in any column, but it's usual to place it as the first or last column.
There is no required directory structure for ML.NET systems, but I recommend using a top-level root directory named Employees that contains a subdirectory named Data where you place the training and test files.
Using AutoML for ML.NET
To invoke the AutoML system, launch a command shell and use the cd command to navigate to the root Employees directory. You can type ML.NET commands as one long line, but I prefer to use the caret continuation character. The auto-train option has 14 parameters as shown in the table in Figure 2. Of these, there are only three required parameters: task, dataset, and label-column-name or label-column-index.
 [Click on image for larger view.]
Figure 2. Arguments for the Auto-train Option of ML.NET CLI
[Click on image for larger view.]
Figure 2. Arguments for the Auto-train Option of ML.NET CLI
The demo command is:
> mlnet.exe auto-train ^
--task multiclass-classification ^
--dataset ".\Data\employees_train.tsv" ^
--test-dataset ".\Data\employees_test.tsv" ^
--label-column-name satisfac ^
--name EmpClassifier ^
--cache on ^
--max-exploration-time 50
The task argument can be "multiclass-classification" when the class to predict has three or more possible values, "binary-classification" when the class to predict has exactly two possible values, or "regression" when the value to predict is numeric, such as income or age.
The dataset argument is required and is the path to the training data. You can use an absolute path or a relative path. The test-dataset argument is optional. If no test-dataset is given, the system will use the training data when computing accuracy.
The label-column-name argument is used to specify the dependent variable to predict. If your data files do not have a header, then you can use the label-column-index parameter with a 1-based integer value.
The name argument specifies the name of the subdirectory and Visual Studio projects that will be created. The name argument is optional and if omitted, you'll get a long, ugly default name that contains the word Sample.
The cache argument tells AutoML to load the entire training dataset into memory if possible. This argument is optional and if omitted, AutoML will try to determine whether to cache data or not.
The max-exploration time limits the amount of time, in seconds, that AutoML is allowed to explore different machine learning algorithms and their hyperparameters. The default value is only 10 seconds, which is rarely long enough to get good results in a non-demo scenario.
Interpreting Results
For a multiclass classification problem, AutoML generates two key metrics. MicroAccuracy is the percentage of correct predictions made by the model on the test dataset. For example, in Figure 1 you can see that the FastTreeOva algorithm created a model that scored 0.6000 (60.00 percent) on the 10-item test data: 6 out of 10 predictions correct. When AutoML has enough time to run a particular algorithm more than once, it will average the results.
The MacroAccuracy metric is weighted by the number of items per class. MacroAccuracy is useful when a dataset is highly skewed towards one class. For example, suppose a test dataset of 200 items had 180 low-satisfaction items, 10 medium-satisfaction items and 10 high-satisfaction items. A model could just predict low-satisfaction for all items and score 180 / 200 = 0.9000 accuracy for the MicroAccuracy metric. But the MacroAccurcy would be (0.9000 + 0.0000 + 0.0000) / 3 = 0.3000. Therefore, when you see a big discrepancy between MicroAccuracy and MacroAccuracy, you should make sure the model is not simply predicting the most common class.
Many of the classification algorithms used by AutoML have "Ova" in their names. This stands for "one versus all". The OVA technique is something of a hack applied to a classification algorithm that is designed for binary classification so that the algorithm can be used for multiclass classification.
Wrapping Up
After generating a prediction model using AutoML, the next step is to use the model to make predictions. The auto-generated Visual Studio projects have code that make a prediction for the first data item in the training dataset. But you can modify the template code to make a prediction for a new, previously unseen item. Such code could look like:
ModelInput X = new ModelInput();
X.Age = 33; X.Hourly = false;
X.Job = "tech"; X.Income = 62000.00f;
ModelOutput Y = predEngine.Predict(X);
string predSatisfac = Y.Prediction;
float[] predProbs = Y.Score;
Console.WriteLine("Prediction probs:");
for (int i = 0; i < predProbs.Length; ++i)
Console.Write(predProbs[i] + " ");
Console.WriteLine("\n");
Console.WriteLine("Predicted class: ");
Console.WriteLine(predSatisfac);
The prediction probabilities array might have values like (0.2500, 0.0500, 0.7500) and then the predicted class would be "high" because the value at index [2] is the largest. The probabilities are ordered by how each class first appears in the training dataset. If you refer back to Listing 1 you'll notice that the first item is "low," the second item is "medium," and the third item is "high." Because of this mechanism, when using AutoML for ML.NET it's a good idea to rearrange the first few items in the training dataset so that each class to predict appears one by one in a logical order of some kind.
About the Author
Dr. James McCaffrey directs the data science and research efforts at Quaetrix, a data analytics company located near Redmond, Washington. Before joining Quaetrix, James was a senior research engineer at Microsoft. James can be reached at [email protected].