News
Microsoft Confirms March Azure Outage Due to COVID-19 Strains
Microsoft published a "post mortem" on a March 24 outage of services on its Azure cloud computing platform, confirming it was caused by increased traffic stemming from the COVID-19 pandemic.
As we earlier reported, Microsoft increased and prioritized computing capacity in the face of a huge surge in remote work and stay-at-home directives that result in people connecting with services such as Microsoft Teams, Skype and so on.
Those moves followed Azure's Pipelines, providing CI/CD DevOps functionality, suffering a "mid-week slowdown as tech world goes remote" reported DevClass on March 26. Earlier in the month, Microsoft Teams suffered some issues, mainly in Europe, reported ZDNet.
Last week, Microsoft shed more light on the March 24 European outage in a "post mortem" titled "Hosted Pools Availability Degradation."
From March 24th - 26th, 2020 many customers in Europe and the United Kingdom experienced delays in their builds and releases targeting our hosted Windows and Linux agents. This incident was caused by VM capacity constraints arising from the global health pandemic that led to increased machine reimage times and then increased wait times for available agents. Many customers experienced significant delays in their pipelines over multiple days. We sincerely apologize for the impact of this incident.
The company also acknowledged "our communication during this incident was also problematic."
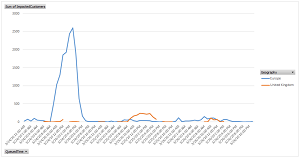 [Click on image for larger view.] The Number of Impacted Organizations During Outage (source: Microsoft).
[Click on image for larger view.] The Number of Impacted Organizations During Outage (source: Microsoft).
Following a comprehensive explanation of the technical details underlying the outage, Microsoft detailed the steps it's taking "To avoid incidents like this in the future":
- We are improving our monitoring and alerting by keeping a closer watch on compute allocation failure rates and agent reimage times. This supplements the monitoring and alerting we already had in place for agent availability and pipeline wait times.
- If we notice impending issues, we will quickly expand our use of ephemeral OS disks for Linux agents, nested virtualization for Windows agents, or both. In the absence of issues, we will continue rolling these changes out slowly, following our normal safe deployment practices.
- We are improving our live-site processes to ensure that initial communication of pipeline delay incidents happens on the same schedule as other incident types."
"Again, we understand the impact that these types of pipeline delays have, especially in combination with a delay in incident communication, and we sincerely apologize for the incident," concluded Chad Kimes, Director of Engineering, the author of last week's post mortem post.
Last month, Microsoft said users can consult the following resources for more information on how Azure is holding up under the new strains:
About the Author
David Ramel is an editor and writer at Converge 360.