The Data Science Lab
Data Prep for Machine Learning: Missing Data
Turning his attention to the extremely time-consuming task of machine learning data preparation, Dr. James McCaffrey of Microsoft Research explains how to examine data files and how to identify and deal with missing data.
Preparing data for use in a machine learning (ML) system is time consuming, tedious, and error prone. A reasonable rule of thumb is that data preparation requires at least 80 percent of the total time needed to create an ML system. There are three main phases of data preparation: cleaning, normalizing and encoding, and splitting. Each of the three main phases has several steps. This article explains how to examine machine learning data files and how to identify and deal with missing data.
A good way to understand what missing data means and see where this article is headed is to take a look at the screenshot of a demo program in Figure 1. The demo starts with a small text file that illustrates many of the types of issues that you might encounter, including missing data, extraneous data, and incorrect data.
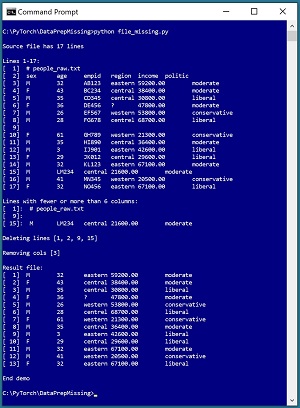 [Click on image for larger view.] Figure 1: Programmatically Dealing with Missing Data
[Click on image for larger view.] Figure 1: Programmatically Dealing with Missing Data
The demo is a Python language program that examines and performs a series of transformations on the original data. In some scenarios where your source data is small (about 500 lines or less) you can clean, normalize and encode, and split the data by using a text editor or dropping the data into an Excel spreadsheet. But in almost all non-demo scenarios, manually preparing ML data is not feasible and so you must programmatically process your data.
The first five lines of the demo source data are:
# people_raw.txt
sex age empid region income politic
M 32 AB123 eastern 59200.00 moderate
F 43 BC234 central 38400.00 moderate
M 35 CD345 central 30800.00 liberal
. . .
Each line represents a person. There are six tab-delimited fields: sex, age, employee ID, region, annual income, and political leaning. The eventual goal of the ML system that will use the data is to create a neural network that predicts political leaning from other fields.
Because the demo data has so few lines, you can easily see most, but not all, of the problems that need to be handled. In neural systems you usually don't want comment lines or a header line, so the first two lines of data are removed by the demo program. You can see that line [6] has a "?" value in the region field, which likely means "unknown." But in a realistic scenario where there are hundreds or thousands of lines of data, you'd have to find such issues programmatically. Similarly, line [8] has "centrel" in the region field, which is likely a misspelling, but this would have to be detected programmatically.
Line [9] is blank, or it may have non-visible control characters. Line [12] has a "3" value in the age field, which is almost certainly a transcription error of some kind. Line [15] has only five fields and is missing the age value.
All of these typical data problems in the demo are quite common in real-world data. But there are many other types of problems too. The point is that you won't find a code library that contains a magic "clean_my_data()" function. Each ML dataset must be dealt with in a custom way.
This article assumes you have intermediate or better skill with a C-family programming language. The demo program is coded using Python but you shouldn't have too much trouble refactoring the demo code to another language if you wish. The complete source code for the demo program is presented in this article. The source code is also available in the accompanying file download.
The Data Preparation Pipeline
Although data preparation is different for every source dataset, in general the data preparation pipeline for most ML systems usually is something similar to the steps shown in Figure 2.
 [Click on image for larger view.] Figure 2: Data Preparation Pipeline Typical Tasks
[Click on image for larger view.] Figure 2: Data Preparation Pipeline Typical Tasks
Data preparation for ML is deceptive because the process is conceptually easy. However, there are many steps, and each step is much trickier than you might expect if you're new to ML. This article explains the first four steps in Figure 2:
- Preliminary exploration of the data
- Dealing with extra lines
- Dealing with lines that have missing data
- Dealing with unwanted columns
Future Data Science Lab articles will explain the other steps. They can be found here.
The tasks in Figure 2 are usually not followed strictly sequentially. You often have to backtrack and jump around to different tasks. But it's a good idea to follow the steps shown in order as much as possible. For example, it's better to deal with missing data before dealing with bad data, because after you get rid of missing data, all lines will have the same number of fields which makes it dramatically easier to compute column metrics such as the mean of a numeric field or rare occurrences in a categorical field.
The Demo Program
The structure of the demo program, with a few minor edits to save space, is shown in Listing 1. I indent my Python programs using two spaces, rather than the more common four spaces or a tab character, as a matter of personal preference. The program has five worker functions plus a main() function to control program flow. The purpose of worker functions line_count(), show_file(), show_short_lines(), delete_lines(), and remove_cols() should be clear from their names.
Listing 1: Missing Data Preparation Demo Program
# file_missing.py
# Python 3.7.6 NumPy 1.18.1
# find and deal with missing data
import numpy as np
def line_count(fn): . . .
def show_file(fn, start, end, indices=False,
strip_nl=False): . . .
def show_short_lines(fn, num_cols, delim): . . .
def delete_lines(src, dest, omit_lines): . . .
def remove_cols(src, dest, omit_cols, delim): . . .
def main():
# 1. examine
fn = ".\\people_raw.txt"
ct = line_count(fn)
print("\nSource file has " + str(ct) + " lines")
print("\nLines 1-17: ")
show_file(fn, 1, 17, indices=True, strip_nl=True)
# 2. deal with missing data
print("\nLines with fewer or more than 6 columns:")
show_short_lines(fn, 6, "\t")
print("\nDeleting lines [1, 2, 9, 15]")
src = ".\\people_raw.txt"
dest = ".\\people_no_missing.txt"
delete_lines(src, dest, [1, 2, 9, 15])
# 3. remove unwanted columns
print("\nRemoving cols [3]")
src = ".\\people_no_missing.txt"
dest = ".\\people_no_missing_lean.txt"
remove_cols(src, dest, [3], "\t")
print("\nResult file: ")
show_file(dest, 1, 99999, indices=True,
strip_nl=True)
print("\nEnd demo")
if __name__ == "__main__":
main()
Program execution begins with:
def main():
# 1. examine
fn = ".\\people_raw.txt"
ct = line_count(fn)
print("\nSource file has " + str(ct) + " lines")
print("\nLines 1-17: ")
show_file(fn, 1, 17, indices=True, strip_nl=True)
. . .
The first step when working with machine learning data files is to do a preliminary investigation. The source data is named people_raw.txt and has only 17 lines to keep the main ideas of dealing with missing data as clear as possible. The number of lines in the file is determined by helper function line_count(). The entire data file is examined by a call to show_file().
The indices=True argument instructs show_file() to display 1-based line numbers. With some data preparation tasks it's more natural to use 1-based indexing, but with other tasks it's more natural to use 0-based indexing. The strip_nl=True argument instructs function show_file() to remove trailing newlines from the data lines before printing them to the shell so that there aren't blank lines between data lines in the display.
The demo continues with:
# 2. deal with missing data
print("\nLines with fewer or more than 6 columns:")
show_short_lines(fn, 6, "\t")
print("\nDeleting lines [1, 2, 9, 15]")
src = ".\\people_raw.txt"
dest = ".\\people_no_missing.txt"
delete_lines(src, dest, [1, 2, 9, 15])
. . .
There are two common forms of missing data: lines with fields that are completely missing and lines with fields that have special values such as "?" or "unknown." It's best to check for completely missing fields first, and deal with unusual or incorrect values later. Function show_short_lines() requires you to specify how many fields/columns there should be in each line. The function traverses the source file and displays any lines that have fewer than or more than the specified number of columns. This approach will also identify lines that have extra delimiters which aren't easy to see, such as double tab characters, and lines with incorrect delimiters, for example blank space characters instead of tab characters.
After lines with completely missing columns have been identified, there are two common approaches for dealing with them. The first approach, which I recommend in most cases, is to just delete the line(s). The second approach, which I do not recommend, unless it's absolutely necessary, is to add the missing value. For example, for a numeric column you could add the average value of the column, and for a categorical column you could add the most common value in the column. The argument for deleting lines with missing fields instead of adding values is that in most cases, "no data is better than incorrect data."
In most situations, data files intended for use in a machine learning system should not have comment lines, header lines, or blank lines. The demo source data has one each of these in lines 1, 2, 9 so these lines are deleted along with line 15 which has a completely missing age column.
The demo concludes with statements that remove the employee ID column:
. . .
# 3. remove unwanted columns
print("\nRemoving cols [3]")
src = ".\\people_no_missing.txt"
dest = ".\\people_no_missing_lean.txt"
remove_cols(src, dest, [3], "\t")
print("\nResult file: ")
show_file(dest, 1, 99999, indices=True, strip_nl=True)
print("\nEnd demo")
if __name__ == "__main__":
main()
The idea here is that an employee ID value isn't useful for predicting a person's political leaning. You should use caution when deleting columns because sometimes useful information can be hidden. For example, suppose employee ID values were assigned in such a way that people in technical jobs have IDs that begin with A, B, or C, and people in sales roles have IDs that begin with D, E, or F, then the employee ID column could be useful for predicting political leaning.
Exploring the Data
When preparing data for an ML system, the first step is always to perform a preliminary examination. This means determining how many lines there are in the data, how many columns/fields there are on each line, and what type of delimiter is used.
The demo defines a function line_count() as:
def line_count(fn):
ct = 0
fin = open(fn, "r")
for line in fin:
ct += 1
fin.close()
return ct
The file is opened for reading and then traversed using a Python for-in idiom. Each line of the file, including the terminating newline character, is stored into variable named "line" but that variable isn't used. There are many alternative approaches. For example, the following function definition is equivalent in terms of functionality:
def line_count(fn):
ct = 0
with open(".\\people_raw.txt", "r") as fin:
while fin.readline():
ct += 1
return ct
The definition of function show_file() is presented in Listing 2. As is the case with all data preparation functions, there are many possible implementations.
Listing 2: Displaying Specified Lines of a File
def show_file(fn, start, end, indices=False,
strip_nl=False):
fin = open(fn, "r")
ln = 1 # advance to start line
while ln < start:
fin.readline()
ln += 1
while ln <= end: # show specified lines
line = fin.readline()
if line == "": break # EOF
if strip_nl == True:
line = line.strip()
if indices == True:
print("[%3d] " % ln, end="")
print(line)
ln += 1
fin.close()
Because the while-loop terminates with a break statement, if you specify an end parameter value that's greater than the number of lines in the source file, such as 99999 for the 17-line demo data, the display will end after the last line has been printed, which is usually what you want.
When writing custom ML data preparation functions there's a temptation to write several wrapper functions for specialized tasks. For example, you usually want to view the first few lines and the last few lines of a data file. So, you could write functions show_first(), and show_last() like so:
def show_first(fn, n, indices=False, strip_nl=False):
show_file(fn, 1, n, indices, strip_nl)
def show_last(fn, n, indices=False, strip_nl=False):
N = line_count(fn)
start = N - n + 1; end = N
show_file(fn, start, end, indices, strip_nl)
My preference is to resist this temptation for many wrapper functions and just use a minimal number of general-purpose functions. For me, the disadvantage of managing and remembering many specialized functions greatly outweighs the benefit of easier function calls.
Finding and Dealing with Missing Data
The demo program defines a function show_short_lines() as:
def show_short_lines(fn, num_cols, delim):
fin = open(fn, "r")
line_num = 0
for line in fin:
line_num += 1
tokens = line.split(delim)
if len(tokens) != num_cols:
print("[%3d]: " % line_num, end="")
print(line)
fin.close()
The function traverses the file line by line and you can use its definition as a template to write custom functions for specific ML data scenarios. For example, a function show_lines_with() could be useful to find lines with target values such as "?" or "unknown."
Once lines with missing columns/fields have been identified, function delete_lines() can be used to delete those lines:
def delete_lines(src, dest, omit_lines):
fin = open(src, "r"); fout = open(dest, "w")
line_num = 1
for line in fin:
if line_num in omit_lines:
line_num += 1
else:
fout.write(line) # has embedded nl
line_num += 1
fout.close(); fin.close()
The function accepts a list of 1-based line numbers to delete. Notice that the function does not strip trailing newlines so a line can be written to a destination file without adding an additional fout.write("\n") statement.
You have to be a bit careful when using delete_lines() because the statement delete_lines(src, dest, [1,2]) is not the same as the statement delete_lines(src, dest, [1]) followed by delete_lines(src, dest, [2]) since line numbering will change after the first call to delete_lines().
Function delete_lines() uses a functional programming paradigm and accepts a source file and writes the results to a destination file. It's possible to implement delete_lines() so that the source file is modified. I do not recommend this approach. It's true that using source and destination files in a data preparation pipeline creates several intermediate files. But you can always delete intermediate files when they're no longer needed. If you corrupt a data file, especially a large one, recovering your data can be very painful or in some cases, impossible.
Removing Columns
In many situations you'll want to remove some of the columns in an ML data file. This is a bit trickier than deleting rows/lines. The demo program defines a function remove_cols(src, dest, cols, delim) that deletes specified 1-based columns from a source text file and saves the result as a destination file. There are several ways to remove specified columns. In pseudo-code, the approach taken by the demo is:
loop each line of src file
split line into tokens by column
create new line without target cols
write the new line to dest file
end-loop
Like many file manipulation functions, removing columns is not conceptually difficult but there are several details that can trip you up, such as remembering that columns-to-delete are 1-based not 0-based, and remembering not to add a delimiter character before or after the newline character at the end of a newly created line. The function implementation is presented in Listing 2.
Listing 2: Removing Specified Columns
def remove_cols(src, dest, omit_cols, delim):
# cols is 1-based
fin = open(src, "r")
fout = open(dest, "w")
for line in fin:
s = "" # reconstucted line
line = line.rstrip() # remove newline
tokens = line.split(delim)
for j in range(0, len(tokens)): # j is 0-based
if j+1 in omit_cols: # col to delete
continue
elif j != len(tokens)-1: # interior col
s += tokens[j] + delim
else:
s += tokens[j] # last col
s += "\n"
fout.write(s)
fout.close(); fin.close()
return
Suppose the source data file is tab-delimited and the current line being processed is stored into a string variable named line:
M 32 AB123 eastern 59200.00 moderate
The first step is to strip the trailing newline character using the statement line = line.rstrip() because if you don't, after splitting by the statement tokens = line.split(delim) the tokens list will hold tokens[0] = "M", tokens[1] = "32", tokens[3] = "AB123", tokens[4] = "eastern", tokens[5] = "59200.00", tokens[6] = "moderate\n." Notice the newline character in tokens[6]. But if you strip before splitting, then tokens[6] will hold just "moderate".
If the column to delete is [3] and the delimiter is a tab character, then the goal reconstruction is
tokens[0] + tab + tokens[1] + tab +
tokens[2] + tab + tokens[4] + tab +
tokens[5] + tab + tokens[6] + newline
Therefore, if you reconstruct the new line using a loop you need to remember not to add a tab delimiter after the last token because the reconstructed line would end with tokens[6] + tab + newline.
Wrapping Up
The techniques presented in this article will remove most, but not all, lines with missing data. But all lines will have the same number of columns, which makes the next steps in the data preparation pipeline much easier than dealing with variable-length lines. These next data preparation steps will be explained in future VSM Data Science Lab articles.
When starting out on a machine learning project, there are ten key things to remember: 1.) data preparation takes a long time, 2.) data preparation takes a long time, 3.) data preparation takes a long time, and, well, you get the idea. I work at a very large tech company and one of my roles is to oversee a series of 12-week ML projects. It's not uncommon for project teams to use10 weeks, or even more, of the 12-week schedule for data preparation.
The strategy presented in this article is to write custom Python programs for file manipulation. An alternative strategy is to use a code library such as Pandas. Using an existing code library can have a steep learning curve, but this approach is well-suited for beginners or data scientists who don't have strong coding skills.