The Data Science Lab
Binary Classification Using PyTorch: Training
Dr. James McCaffrey of Microsoft Research continues his examination of creating a PyTorch neural network binary classifier through six steps, here addressing step No. 4: training the network.
The goal of a binary classification problem is to predict an output value that can be one of just two possible discrete values, such as "male" or "female." This article is the third in a series of four articles that present a complete end-to-end production-quality example of binary classification using a PyTorch neural network. The example problem is to predict if a banknote (think euro or dollar bill) is authentic or a forgery based on four predictor variables extracted from a digital image of the banknote.
The process of creating a PyTorch neural network binary classifier consists of six steps:
- Prepare the training and test data
- Implement a Dataset object to serve up the data
- Design and implement a neural network
- Write code to train the network
- Write code to evaluate the model (the trained network)
- Write code to save and use the model to make predictions for new, previously unseen data
Each of the six steps is fairly complicated, and the six steps are tightly coupled which adds to the challenge. This article covers the fourth step.
A good way to see where this series of articles is headed is to take a look at the screenshot of the demo program in Figure 1. The demo begins by creating Dataset and DataLoader objects which have been designed to work with the well-known Banknote Authentication data. Next, the demo creates a 4-(8-8)-1 deep neural network. Then the demo prepares training by setting up a loss function (binary cross entropy), a training optimizer function (stochastic gradient descent), and parameters for training (learning rate and max epochs).
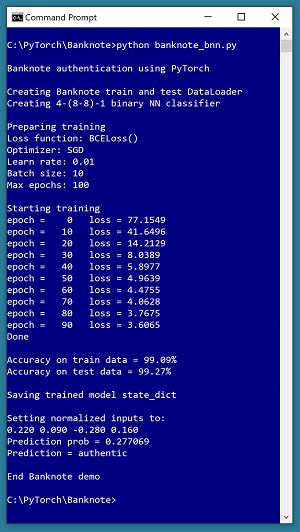 [Click on image for larger view.] Figure 1: Banknote Binary Classification in Action
[Click on image for larger view.] Figure 1: Banknote Binary Classification in Action
The demo trains the neural network for 100 epochs using batches of 10 items at a time. An epoch is one complete pass through the training data. For example, if there were 2,000 training data items and training was performed using batches of 50 items at a time, one epoch would consist processing 40 batches of data. During training, the demo computes and displays a measure of the current error. Because error slowly decreases, training is succeeding.
After training the network, the demo program computes the classification accuracy of the model on the training data (99.09 percent correct) and on the test data (99.27 percent correct). Because the two accuracy values are similar, it is likely that model overfitting has not occurred. After evaluating the trained model, the demo program saves the model using the state dictionary approach, which is the most common of three standard techniques.
The demo concludes by using the trained model to make a prediction. The four normalized input predictor values are (0.22, 0.09, -0.28, 0.16). The computed output value is 0.277069 which is less than 0.5 and therefore the prediction is class 0, which in turn means authentic banknote.
This article assumes you have an intermediate or better familiarity with a C-family programming language, preferably Python, but doesn't assume you know very much about PyTorch. The complete source code for the demo program, and the two data files used, are available in the download that accompanies this article. All normal error checking code has been omitted to keep the main ideas as clear as possible.
To run the demo program, you must have Python and PyTorch installed on your machine. The demo programs were developed on Windows 10 using the Anaconda 2020.02 64-bit distribution (which contains Python 3.7.6) and PyTorch version 1.6.0 for CPU installed via pip. You can find detailed step-by-step installation instructions for this configuration in my blog post.
The Banknote Authentication Data
The raw Banknote Authentication data looks like:
3.6216, 8.6661, -2.8073, -0.44699, 0
4.5459, 8.1674, -2.4586, -1.46210, 0
. . .
-2.5419, -0.65804, 2.6842, 1.1952, 1
The raw data can be found online. The goal is to predict the value in the fifth column (0 = authentic banknote, 1 = forged banknote) using the four predictor values. There are a total of 1,372 data items. The raw data was prepared in the following way. First, all four raw numeric predictor values were normalized by dividing by 20 so they're all between -1.0 and +1.0. Next, 1-based ID values from 1 to 1372 were added so that items can be tracked. Next, a utility program split the data into a training data file with 1,097 randomly selected items (80 percent of the 1,372 items) and a test data file with 275 items (the other 20 percent).
After the structure of the training and test files was established, I coded a PyTorch Dataset class to read data into memory and serve the data up in batches using a PyTorch DataLoader object. A Dataset class definition for the normalized and ID-augmented Banknote Authentication is shown in Listing 1.
Listing 1: A Dataset Class for the Banknote Data
class BanknoteDataset(T.utils.data.Dataset):
def __init__(self, src_file, num_rows=None):
all_data = np.loadtxt(src_file, max_rows=num_rows,
usecols=range(1,6), delimiter="\t", skiprows=0,
dtype=np.float32) # strip IDs off
self.x_data = T.tensor(all_data[:,0:4],
dtype=T.float32).to(device)
self.y_data = T.tensor(all_data[:,4],
dtype=T.float32).reshape(-1,1).to(device)
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
preds = self.x_data[idx,:] # idx rows, all 4 cols
lbl = self.y_data[idx,:] # idx rows, the 1 col
sample = { 'predictors' : preds, 'target' : lbl }
return sample
Preparing data and defining a PyTorch Dataset is not trivial. You can find the article that explains how to create Dataset objects and use them with DataLoader objects here in The Data Science Lab.
The Neural Network Architecture
In the previous article in this series, I described how to design and implement a neural network for binary classification using the Banknote Authentication data. One possible definition is presented in Listing 2. The code defines a 4-(8-8)-1 neural network.
Listing 2: A Neural Network for the Banknote Data
class Net(T.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hid1 = T.nn.Linear(4, 8) # 4-(8-8)-1
self.hid2 = T.nn.Linear(8, 8)
self.oupt = T.nn.Linear(8, 1)
T.nn.init.xavier_uniform_(self.hid1.weight)
T.nn.init.zeros_(self.hid1.bias)
T.nn.init.xavier_uniform_(self.hid2.weight)
T.nn.init.zeros_(self.hid2.bias)
T.nn.init.xavier_uniform_(self.oupt.weight)
T.nn.init.zeros_(self.oupt.bias)
def forward(self, x):
z = T.tanh(self.hid1(x))
z = T.tanh(self.hid2(z))
z = T.sigmoid(self.oupt(z))
return z
If you are new to PyTorch, the number of design decisions for a neural network can seem overwhelming. But with every program you write, you learn which design decisions are important and which don't affect the final prediction model very much, and the pieces of the puzzle quickly fall into place.
The Overall Program Structure
The overall structure of the PyTorch binary classification program, with a few minor edits to save space, is shown in Listing 3. I indent my Python programs using two spaces rather than the more common four spaces as a matter of personal preference.
Listing 3: The Structure of the Demo Program
# banknote_bnn.py
# PyTorch 1.6.0-CPU Anaconda3-2020.02
# Python 3.7.6 Windows 10
import numpy as np
import torch as T
device = T.device("cpu")
# IDs 0001 to 1372 added
# data has been k=20 normalized (all four columns)
# ID variance skewness kurtosis entropy class
# [0] [1] [2] [3] [4] [5]
# (0 = authentic, 1 = forgery) # verified
# train: 1097 items (80%), test: 275 item (20%)
class BanknoteDataset(T.utils.data.Dataset):
def __init__(self, src_file, num_rows=None): . . .
def __len__(self): . . .
def __getitem__(self, idx): . . .
# ----------------------------------------------------
def accuracy(model, ds): . . .
# ----------------------------------------------------
class Net(T.nn.Module):
def __init__(self): . . .
def forward(self, x): . . .
# ----------------------------------------------------
def main():
# 0. get started
print("Banknote authentication using PyTorch ")
T.manual_seed(1)
np.random.seed(1)
# 1. create Dataset and DataLoader objects
# 2. create neural network
# 3. train network
# 4. evaluate model
# 5. save model
# 6. make a prediction
print("End Banknote demo ")
if __name__== "__main__":
main()
It's important to document the versions of Python and PyTorch being used because both systems are under continuous development. Dealing with versioning incompatibilities is a significant headache when working with PyTorch and is something you should not underestimate.
I like to use "T" as the top-level alias for the torch package. Most of my colleagues don't use a top-level alias and spell out "torch" dozens of times per program. Also, I use the full form of sub-packages rather than supplying aliases such as "import torch.nn.functional as functional." In my opinion, using the full form is easier to understand and less error-prone than using many aliases.
The demo program defines a program-scope CPU device object. I usually develop my PyTorch programs on a desktop CPU machine. After I get that version working, converting to a CUDA GPU system only requires changing the global device object to T.device("cuda") plus a minor amount of debugging.
The demo program defines just one helper method, accuracy(). All of the rest of the program control logic is contained in a single main() function. It is possible to define other helper functions such as train_net(), evaluate_model(), and save_model(), but in my opinion this modularization approach unexpectedly makes the program more difficult to understand rather than easier to understand.
Training the Neural Network
The details of training a neural network with PyTorch are complicated so buckle up. In very high level pseudo-code, the process to train a neural network looks like:
loop max_epochs times
loop until all batches processed
read a batch of training data (inputs, targets)
compute outputs using the inputs
compute error between outputs and targets
use error to update weights and biases
end-loop (all batches)
end-loop (all epochs)
The difficult part of training is the "use error to update weights and biases" step. PyTorch does most of the hard work for you. It's not easy to understand neural network training without seeing a working program. The program shown in Listing 4 demonstrates how to train a network for binary classification. The screenshot in Figure 2 shows the output from the test program.
Listing 4: Training a Neural Network
# test_training.py
import numpy as np
import torch as T
device = T.device("cpu")
class BanknoteDataset(T.utils.data.Dataset): . . .
# see Listing 1
class Net(T.nn.Module): . . .
# see Listing 2
print("Begin test of training ")
T.manual_seed(1)
np.random.seed(1)
train_file = ".\\Data\\banknote_k20_train.txt"
train_ds = BanknoteDataset(train_file) # all rows
bat_size = 10
train_ldr = T.utils.data.DataLoader(train_ds,
batch_size=bat_size, shuffle=True)
net = Net().to(device)
net = net.train() # set training mode
lrn_rate = 0.01
loss_obj = T.nn.BCELoss() # binary cross entropy
optimizer = T.optim.SGD(net.parameters(),
lr=lrn_rate)
for epoch in range(0, 100):
epoch_loss = 0.0 # sum of avg loss/item/batch
for (batch_idx, batch) in enumerate(train_ldr):
X = batch['predictors'] # [10,4] inputs
Y = batch['target'] # [10,1] targets
optimizer.zero_grad()
oupt = net(X) # [10,1] computeds
loss_val = loss_obj(oupt, Y) # a tensor
epoch_loss += loss_val.item() # accumulate
loss_val.backward() # compute all gradients
optimizer.step() # update all wts, biases
if epoch % 10 == 0:
print("epoch = %4d loss = %0.4f" % \
(epoch, epoch_loss))
print("Done ")
The training demo program begins execution with:
T.manual_seed(1)
np.random.seed(1)
train_file = ".\\Data\\banknote_k20_train.txt"
train_ds = BanknoteDataset(train_file) # all rows
The global PyTorch and NumPy random number generator seeds are set so that results will be reproducible. Unfortunately, due to multiple threads of execution, in some cases your results will not be reproducible even if you set the seed values. The demo assumes that the training data is located in a subdirectory named Data. The BanknoteDataset object reads all 1,097 training data items into memory. If your training data size is very large you can read just part of the data into memory using the num_rows parameter.
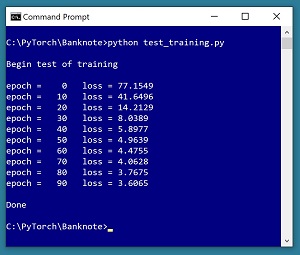 [Click on image for larger view.] Figure 2: Testing the Training Code
[Click on image for larger view.] Figure 2: Testing the Training Code
The demo program prepares training with these statements:
bat_size = 10
train_ldr = T.utils.data.DataLoader(train_ds,
batch_size=bat_size, shuffle=True)
net = Net().to(device)
net = net.train() # set training mode
The training data loader is configured to read batches of 10 items at a time. In theory, the batch size doesn't matter but in practice the batch size affects how quickly training works. When you have a choice, it makes sense to make the batch size and number of training items evenly divisible so that all batches have the same size. Because the demo test Banknote data has 1,097 rows, there will be 109 batches of size 10 and a final batch of size 7. It is very important to set shuffle=True when training because the default value is False which will usually result in failed training.
After the neural network is created, it is set into training mode using the statement net = net.train(). If your neural network has a dropout layer or a batch normalization layer, you must set the network to train() mode during training and to eval() mode when using the network at any other time, such as making a prediction or computing model classification accuracy. The default state is train() mode so setting the mode isn't necessary for the demo network for two reasons: it's already in train() mode and it doesn't use dropout or batch normalization. However, in my opinion it's good practice to always explicitly set the network mode. The train() mode method works by reference so you can write just net.train() instead of net = net.train() but in my opinion the second form is clearer. The statement net.train() looks like it's training a net object, which is not what's happening.
The demo continues training preparation with these two statements:
lrn_rate = 0.01
loss_obj = T.nn.BCELoss() # binary cross entropy
optimizer = T.optim.SGD(net.parameters(),
lr=lrn_rate)
For binary classification, the two main loss (error) functions are binary cross entropy error and mean squared error. In the early days of neural networks, mean squared error was more common but now binary cross entropy is far more common. PyTorch has a CrossEntropyLoss() class two but it is not compatible with binary classification unless you format the training target values as (1, 0) and (0, 1) instead of 0 and 1.
The demo program uses the simplest possible training optimization technique which is stochastic gradient descent (SGD). Understanding all the details of PyTorch optimizers is blisteringly difficult. PyTorch 1.6 supports 11 different techniques. Each technique's method has several parameters which are very complex and which often have a dramatic effect on training performance. See the list in Figure 3.
 [Click on image for larger view.] Figure 3: PyTorch Optimizers
[Click on image for larger view.] Figure 3: PyTorch Optimizers
Fortunately, almost all of the PyTorch optimizers' parameters have reasonable default values. As a general rule of thumb, for binary classification problems I start by trying SGD using the default parameter values. Then if SGD fails after a few hours of experimentation, I try the Adam algorithm (Adam is not an acronym but its name derives from "adaptive moment estimation"). In theory, any one of the PyTorch optimizers will work -- there is no magic algorithm. Loosely expressed, the key difference between SGD and Adam is that SGD uses a single fixed learning rate for all weights and biases, but Adam uses a dedicated, adaptive learning rate for each weight and bias.
A learning rate controls how much an associated network weight or bias changes on each update during training. For SGD, a small learning rate will slowly but surely improve weights and biases, but the changes might be so slow that training takes too long. A large learning rate trains a neural network faster but at the risk of speeding by good values and leaving them behind.
The key takeaway is that if you're new to PyTorch you could easily spend weeks exploring the nuances of different training optimizers and never get any programs written. Optimizers are important, but it's better to learn about different optimizers by experimenting with them slowly over time with different problems, than it is to try and master all their details before writing any code.
After training has been prepared, the demo program starts the training:
for epoch in range(0, 100):
epoch_loss = 0.0 # sum of batch losses
for (batch_idx, batch) in enumerate(train_ldr):
X = batch['predictors'] # [10,4] inputs
Y = batch['target'] # [10,1] targets
optimizer.zero_grad()
oupt = net(X) # [10,1] computeds
. . .
It's important to monitor the cross entropy loss during training so that you can tell if training is working or not. There are three main ways to monitor loss. A loss value is computed for each batch of input values. This batch loss value is the average of the loss values for each item in the batch. For example, if a batch has four items and the cross entropy loss values for each of the four items are (8.00, 2.00, 5.00, 3.00) then the batch loss is 18.00 / 4 = 4.50. The simplest approach is to just display the loss for either the first batch or the last batch for each training epoch. It's not feasible to print the loss value for every batch because there are just too many batches processed in almost all realistic scenarios.
A second approach for monitoring loss during training is to accumulate each batch loss value and then, after all the batches in one epoch have been processed in one epoch, you can display the sum of the batch losses. For example, if one epoch consists of 3 batches of data and the batch loss values are (3.50, 6.10, 2.30) then the sum of the batch losses is 3.50 + 6.10 + 2.30 = 11.90. This approach for monitoring loss is the one used by the demo program.
A third approach for monitoring loss is to accumulate batch loss values and then instead of displaying the sum of the batch values, compute and display the average of the sum of the batch values. For 3 batches of data where the batch loss values are (3.50, 61.0, 2.30) then the average of the batch loss values is (3.50 + 61.0 + 2.30) / 3 = 11.90 / 3 = 3.90. This approach is the most granular.
None of the three approaches for monitoring loss during training give values that are easy to interpret. The important thing is to watch the values to see if they are decreasing. It is possible for training loss values to bounce around a bit, where a loss value might increase briefly, especially if your batch size is small. Because there are many ways to monitor and display cross entropy loss for binary classification, loss values usually can't be compared for different systems unless you know the systems are computing and displaying loss in the exact same way.
The for-loop that enumerates the DataLoader object will automatically exit after all batches of the training data have been retrieved. The statement optimzer.zero_grad() is critically important because it resets all weight and bias gradients to 0. If you accidentally forget to call the zero_grad() method you will get some strange results and training will fail. The demo program continues training with:
. . .
loss_val = loss_obj(oupt, Y) # a tensor
epoch_loss += loss_val.item() # accumulate
loss_val.backward()
optimizer.step()
The statement loss_val = loss_obj(oupt, Y) is slightly misleading because it's using a quirky Python language feature called callable-class. The loss_obj object has an invisible, inherited method named __call__() and when you write loss_obj(oupt, Y) it is magically translated by the Python interpreter to loss_obj.__call__(oupt, Y). In fact, you can verify this by explicitly writing loss_val = loss_obj(oupt, Y) in the demo program and the program will give the exact same results.
The oupt and Y arguments which are fed to loss_obj are both 10 x 1 tensors and so 10 loss values are computed. But the return result is a tensor with a with a single value that is the average of the 10 loss values. That single value is accumulated using the statement epoch_loss += loss_val.item().
The item() method is used when you have a tensor that has a single numeric value. The item() method extracts the single value from the associated tensor and returns it as a regular scalar value. Somewhat unfortunately (in my opinion), PyTorch 1.6 allows you to skip the call to item() so you can write the shorter epoch_loss += loss_val instead. Because epoch_loss is a non-tensor scalar, the interpreter will figure out that you must want to extract the value in the loss_val tensor. You can think of this mechanism as similar to implicit type conversion. However, the shortcut form with item() is misleading in my opinion and so I use item() in most situations, even when it's not technically necessary.
The loss_val is a tensor that is the last value in the behind-the-scenes computational graph that represents the neural network being trained. The loss_val.backward() method uses the back-propagation algorithm to compute all the gradients associated with the weights and biases that a part of the network containing loss_val. Put another way, loss_val.backward() computes the gradients of the output node weights and bias, and then the hid2 layer gradients, and then the hid1 layer gradients.
The optimizer.step() statement uses the newly computed gradients to update all the weights and biases in the neural network so that computed output values will get closer to the target values. When you instantiate an optimizer object for a neural network, you must pass in the network parameters object and so the optimizer object effectively has full access to the network and can modify it.
If you understand what each training statement does, you can vary the order in which you place the training statements. For example, this code is equivalent to the code shown above:
X = batch['predictors'] # [10,4] inputs
Y = batch['target'] # [10,1] targets
oupt = net(X) # [10,1] computeds
loss_val = loss_obj(oupt, Y) # a tensor
epoch_loss += loss_val.item() # accumulate
optimizer.zero_grad() # zero all gradients
loss_val.backward() # compute new gradients
optimizer.step() # update all weights
The demo program concludes training with these statements:
. . .
optimizer.step()
if epoch % 10 == 0:
print("epoch = %4d loss = %0.4f" % \
(epoch, epoch_loss))
print("Done ")
After all batches have been processed, an epoch has been completed and program execution exits the innermost for-loop. Although it's possible to display the accumulated loss value for every epoch, in most cases that's too much information and so the demo just displays the accumulated loss once every 10 epochs. In many problem scenarios you might want to store all accumulated epoch loss values in memory, and then save them all to a text file after training completes. This allows you to analyze training without slowing it down.
Wrapping Up
Training a PyTorch binary classifier is paradoxically simple and complicated at the same time. Training in PyTorch works at a low level. This requires a lot of effort but gives you maximum flexibility. The behind-the-scenes details and options such as optimizer parameters are very complex. But the good news is that the demo training code presented in this article can be used as a template for most of the binary classification problems you're likely to encounter.
Monitoring cross entropy loss during training allows you to determine if training is working, but loss isn't a good way to evaluate a trained model. Ultimately prediction accuracy is the metric that's most important. Computing model accuracy, and saving a trained model to file, are the topics in the next article in this series.