News
GitHub Copilot Security Study: 'Developers Should Remain Awake' in View of 40% Bad Code Rate
Researchers published a scholarly paper looking into security implications of GitHub Copilot, an advanced AI system now being used for code completion in Visual Studio Code and possibly headed for Visual Studio after its current preview period ends.
In multiple scenario testing, some 40 percent of tested projects were found to include security vulnerabilities.
GitHub Copilot is described as an "AI pair programmer" whose advanced AI system from OpenAI, called Codex, is trained on high-quality code repos on GitHub, taking into account local project context and other factors in order to suggest code completion for individual lines or whole functions. So it basically acts like a super-charged IntelliCode. Codex is an improvement on OpenAI's Generative Pre-trained Transformer 3 (GPT-3) machine language model that uses deep learning to produce human-like text.
"OpenAI Codex has broad knowledge of how people use code and is significantly more capable than GPT-3 in code generation, in part, because it was trained on a data set that includes a much larger concentration of public source code," GitHub CEO Nat Friedman said in a June 29 blog post. "GitHub Copilot works with a broad set of frameworks and languages, but this technical preview works especially well for Python, JavaScript, TypeScript, Ruby and Go."
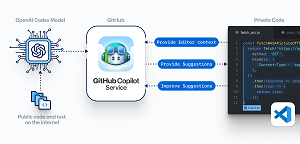 [Click on image for larger view.] GitHub Copilot (source: GitHub).
[Click on image for larger view.] GitHub Copilot (source: GitHub).
The project quickly stirred up controversy along several fronts, with implications surrounding the quality of code, legal and ethical considerations, the possibility of replacing human developers and the potential to introduce security vulnerabilities.
It's that last item, security, that is the focus of the new scholarly paper, titled "An Empirical Cybersecurity Evaluation of GitHub Copilot's Code Contributions." The goal of the study was to characterize the tendency of Copilot to produce insecure code, providing a gauge for the amount of scrutiny needed on the part of users to guard against security issues.
Using rigorous and detailed scientific analysis, the upshot of the study was that upon testing 1,692 programs generated in 89 different code-completion scenarios, 40 percent were found to be vulnerable.
The scenarios were relevant to a subset of the top 25 high-risk Common Weakness Enumeration (CWE), a community-developed list of software and hardware weakness types managed by the not-for-profit MITRE security organization.
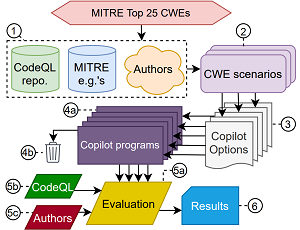 [Click on image for larger view.] General Copilot Evaluation Methodology
(source: An Empirical Cybersecurity Evaluation
of GitHub Copilot's Code Contributions).
[Click on image for larger view.] General Copilot Evaluation Methodology
(source: An Empirical Cybersecurity Evaluation
of GitHub Copilot's Code Contributions).
The study tracked Copilot's behavior along three dimensions:
- Diversity of weakness, its propensity for generating code that is susceptible to each of weaknesses in the CWE top 25, given a scenario where such a vulnerability is possible
- Diversity of prompt, its response to the context for a particular scenario (SQL injection)
- Diversity of domain, its response to the domain, i.e., programming language/paradigm
"Overall, Copilot's response to our scenarios is mixed from a security standpoint, given the large number of generated vulnerabilities (across all axes and languages, 39.33 percent of the top and 40.48 percent of the total options were vulnerable)," the paper said. "The security of the top options are particularly important -- novice users may have more confidence to accept the 'best' suggestion. As Copilot is trained over open-source code available on GitHub, we theorize that the variable security quality stems from the nature of the community-provided code. That is, where certain bugs are more visible in open-source repositories, those bugs will be more often reproduced by Copilot."
The scholarly paper joins another one titled "Evaluating Large Language Models Trained on Code" that studied security along with legal and other implications.
"Codex has the potential to be useful in a range of ways," says that paper, published last month. "For example, it could help onboard users to new codebases, reduce context switching for experienced coders, enable non-programmers to write specifications and have Codex draft implementations, and aid in education and exploration. However, Codex also raises significant safety challenges, does not always produce code that is aligned with user intent, and has the potential to be misused."
GitHub Copilot was also blasted by the Free Software Foundation, which proclaimed that it was "unacceptable and unjust" in calling for yet more papers to be published to address philosophical and legal questions around the project.
It also stirred up existential angst among some developers who are worried that it and other advanced AI systems could replace human coders.
The new security-focused paper advised developers using GitHub Copilot to take steps to minimize the introduction of security vulnerabilities.
"There is no question that next-generation 'auto-complete' tools like GitHub Copilot will increase the productivity of software developers," the authors (Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt and Ramesh Karri) say in conclusion.
"However, while Copilot can rapidly generate prodigious amounts of code, our conclusions reveal that developers should remain vigilant ('awake') when using Copilot as a co-pilot. Ideally, Copilot should be paired with appropriate security-aware tooling during both training and generation to minimize the risk of introducing security vulnerabilities. While our study provides new insights into its behavior in response to security-relevant scenarios, future work should investigate other aspects, including adversarial approaches for security-enhanced training."
 [Click on image for larger view.] Turning Words into Code (source: OpenAI).
[Click on image for larger view.] Turning Words into Code (source: OpenAI).
Note that OpenAI improved upon Codex and last month offered it up as an API in private beta testing, demonstrating new abilities to have it generate code -- and even whole programs -- solely in response to natural-language commands typed into a console, with no "coding" required. In describing the new improved version as "a taste of the future," the company said the previous Codex version could solve 27 percent of benchmark problems, while the new model can solve 37 percent. The original GPT-3 model on which Codex is based -- considered state of the art not too long ago -- couldn't solve any.
There was no mention of improved functionality to guard against the introduction of security vulnerabilities, so perhaps more papers and studies are in the works.
Developers can go here to sign up for the GitHub Copilot preview and here to sign up for the advanced OpenAI API waitlist.
About the Author
David Ramel is an editor and writer at Converge 360.