The Data Science Lab
How to Fine-Tune a Transformer Architecture NLP Model
The goal is sentiment analysis -- accept the text of a movie review (such as, "This movie was a great waste of my time.") and output class 0 (negative review) or class 1 (positive review).
This article describes how to fine-tune a pretrained Transformer Architecture model for natural language processing. More specifically, this article explains how to fine-tune a condensed version of a pretrained BERT model to create binary classifier for a subset of the IMDB movie review dataset. The goal is sentiment analysis -- accept the text of a movie review (such as, "This movie was a great waste of my time.") and output class 0 (negative review) or class 1 (positive review).
You can think of a pretrained transformer architecture (TA) model as sort of an English language expert. But the TA expert doesn't know anything about movies and so you provide additional training to fine-tune the model so that it understands the difference between a positive movie review and a negative review.
There are several pretrained TA models for natural language processing (NLP). Two of the most well-known are BERT (bidirectional encoder representations from transformers) and GPT (generative pretrained transformer). TA models are huge, with millions of weights and bias parameters.
TA models have revolutionized NLP, but TA systems are extremely complex and implementing them from scratch can take hundreds or even thousands of man-hours. Hugging Face (HF) is an open source code library that provides pretrained models and an API set to work with the models. The HF library makes implementing NLP systems using TA models much less difficult (see "How to Create a Transformer Architecture Model for Natural Language Processing").
A good way to see where this article is headed is to take a look at the screenshot of a demo program in Figure 1. The demo program begins by loading a small 200-item subset of the IMDB movie review dataset into memory. The full dataset has 50,000 movie reviews -- 25,000 reviews for training and 25,000 reviews for testing, where there are 12,500 positive and 12,500 negative reviews. Working with the full dataset is very time-consuming so the demo data uses just the first 100 positive training reviews and the first 100 negative training reviews.
The movie reviews are in raw text form. The reviews are read into memory then converted to a data structure that holds integer tokens. For example, the word "movie" has token ID = 3185. The tokenized movie reviews data structure is fed to a PyTorch Dataset object that is used to send batches of tokenized reviews and their associated labels to training code.
After the movie review data has been prepared, the demo loads a pretrained DistilBERT model into memory. DistilBERT is a condensed ("distilled"), but still large, version of the huge BERT model. The uncased version of DistilBERT has 66 million weights and biases. Then the demo fine-tunes the pretrained model by training the model using standard PyTorch techniques. The demo concludes by saving the fine-tuned model to file.
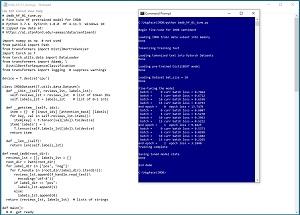 [Click on image for larger view.] Figure 1: Fine-Tuning a Condensed BERT Model for Movie Sentiment Analysis
[Click on image for larger view.] Figure 1: Fine-Tuning a Condensed BERT Model for Movie Sentiment Analysis
This article assumes you have an intermediate or better familiarity with a C-family programming language, preferably Python, and basic familiarity with PyTorch, but does not assume you know anything about the Hugging Face code library. The complete source code for the demo program is presented in this article, and the code is also available in the accompanying file download.
To run the demo program, you must have Python, PyTorch and HF installed on your machine. The demo programs were developed on Windows 10 using the Anaconda 2020.02 64-bit distribution (which contains Python 3.7.6) and PyTorch version 1.8.0 for CPU installed via pip and HF transformers version 4.11.3. Installation is not trivial. You can find detailed step-by-step installation instructions for PyTorch in my blog post. Installing the HF transformers library is relatively simple. You can issue the shell command "pip install transformers".
Overall Program Structure
The demo program structure is:
# import modules and packages
device = torch.device('cpu')
class IMDbDataset(T.utils.data.Dataset): . . .
def read_imdb(root_dir): . . .
def main():
# 0. preparation
# 1. load raw IMDB train data into memory
# 2. tokenize the raw data reviews text
# 3. load tokenized text, labels into PyTorch Dataset
# 4. load (possibly cached) pretrained HF model
# 5. fine-tune / train model using standard PyTorch
# 6. save trained model weights and biases
if __name__ == "__main__":
main()
The HF library can use either the PyTorch or TensorFlow libraries. The demo uses PyTorch. The IMDbDataset is a program-defined PyTorch class that holds training data and serves it up in batches. The read_imdb() function is a helper that reads movie review text data from file into memory. All the program logic is in a single main() function.
The complete demo code, with a few minor edits to save space, is presented in Listing 1. I prefer to indent using two spaces rather than the standard four spaces. The backslash character is used for line continuation to break down long statements.
Listing 1: The Complete Fine-Tuning Demo Program
# imdb_hf_01_tune.py
# fine-tune HF pretrained model for IMDB
# zipped raw data at:
# https://ai.stanford.edu/~amaas/data/sentiment/
import numpy as np # not used
from pathlib import Path
from transformers import DistilBertTokenizer
import torch as T
from torch.utils.data import DataLoader
from transformers import AdamW, \
DistilBertForSequenceClassification
from transformers import logging # suppress warnings
device = T.device('cpu')
class IMDbDataset(T.utils.data.Dataset):
def __init__(self, reviews_lst, labels_lst):
self.reviews_lst = reviews_lst # list of token IDs
self.labels_lst = labels_lst # list of 0-1 ints
def __getitem__(self, idx):
item = {} # [input_ids] [attention_mask] [labels]
for key, val in self.reviews_lst.items():
item[key] = T.tensor(val[idx]).to(device)
item['labels'] = \
T.tensor(self.labels_lst[idx]).to(device)
return item
def __len__(self):
return len(self.labels_lst)
def read_imdb(root_dir):
reviews_lst = []; labels_lst = []
root_dir = Path(root_dir)
for label_dir in ["pos", "neg"]:
for f_handle in (root_dir/label_dir).iterdir():
reviews_lst.append(f_handle.read_text(\
encoding='utf-8'))
if label_dir == "pos":
labels_lst.append(1)
else:
labels_lst.append(0)
return (reviews_lst, labels_lst) # lists of strings
def main():
# 0. get ready
print("\nBegin fine-tune for IMDB sentiment ")
logging.set_verbosity_error() # suppress wordy warnings
T.manual_seed(1)
np.random.seed(1)
# 1. load raw IMDB train data into memory
print("\nLoading IMDB train data subset into memory ")
train_reviews_lst, train_labels_lst = \
read_imdb(".\\DataSmall\\aclImdb\\train")
print("Done ")
# consider creating validation set here
# 2. tokenize the raw data reviews text
print("\nTokenizing training text ")
toker = \
DistilBertTokenizer.from_pretrained(\
'distilbert-base-uncased')
train_tokens = toker(train_reviews_lst, \
truncation=True, padding=True) # token IDs and mask
# 3. load tokenized text and labels into PyTorch Dataset
print("\nLoading tokenized text into Pytorch Datasets ")
train_dataset = \
IMDbDataset(train_tokens, train_labels_lst)
print("Done ")
# 4. load (possibly cached) pretrained HF model
print("\nLoading pre-trained DistilBERT model ")
model = \
DistilBertForSequenceClassification.from_pretrained( \
'distilbert-base-uncased')
model.to(device)
model.train() # set into training mode
print("Done ")
# 5. fine-tune / train model using standard PyTorch
print("\nLoading Dataset bat_size = 10 ")
train_loader = DataLoader(train_dataset, \
batch_size=10, shuffle=True)
print("Done ")
print("\nFine-tuning the model ")
optim = AdamW(model.parameters(), lr=5.0e-5) # wt decay
for epoch in range(3):
epoch_loss = 0.0
for (b_ix, batch) in enumerate(train_loader):
optim.zero_grad()
inpt_ids = batch['input_ids'] # tensor
attn_mask = batch['attention_mask'] # tensor
lbls = batch['labels'] # tensor
outputs = model(inpt_ids, \
attention_mask=attn_mask, labels=lbls)
loss = outputs[0]
epoch_loss += loss.item() # accumulate batch loss
loss.backward()
optim.step()
if b_ix % 5 == 0: # 200 items is 20 batches of 10
print(" batch = %5d curr batch loss = %0.4f " % \
(b_ix, loss.item()))
# if b_ix >= xx: break # to save time for demo
print("end epoch = %4d epoch loss = %0.4f " % \
(epoch, epoch_loss))
print("Training complete ")
# 6. save trained model weights and biases
print("\nSaving tuned model state ")
model.eval()
T.save(model.state_dict(), \
".\\Models\\imdb_state.pt") # just state
print("Done ")
print("\nEnd demo ")
if __name__ == "__main__":
main()
Getting the IMDB Training Data
The online IMDB movie review data is stored in compressed form as file aclImdb_v1.tar.gz and on a Windows system must be unzipped and extracted using a utility program such as WinZip or 7-Zip. Both utilities are good, but I prefer 7-Zip.
The unzipped files will be in a root folder named aclImdb ("ACL IMDB"). The root folder contains subdirectories named test and train. The test and train directories contain subdirectories named pos and neg. Each of these two directories contain 12,500 text files where each file is one movie review.
The file names look like 0_9.txt and 113_3.txt where the first part of the name, before the underscore, is a 0-based index and the second part of the name is the actual numeric rating of the review. Ratings of 7, 8, 9, 10 are positive reviews (all are in the "pos" directory) and ratings of 1, 2, 3, 4 are negative reviews. Movie reviews that received ratings of 5 and 6 (neither strongly positive nor negative) are not included in the IMDB dataset. Note that the actual 1-10 ratings are not used in the demo.
To reduce the IMDB dataset down to a size that's manageable for experimentation, I used only the training files, and deleted all reviews except for the first 100 positive and first 100 negative, leaving 200 total training reviews.
The program-defined read_imdb() function reads reviews text and labels into memory. It's implemented as:
from pathlib import Path
def read_imdb(root_dir):
reviews_lst = []; labels_lst = []
root_dir = Path(root_dir)
for label_dir in ["pos", "neg"]:
for f_handle in (root_dir/label_dir).iterdir():
reviews_lst.append(f_handle.read_text(\
encoding='utf-8'))
if label_dir == "pos": labels_lst.append(1)
else: labels_lst.append(0)
return (reviews_lst, labels_lst) # list of strings
The Python pathlib library is relatively new (from Python 3.4) and is bit more robust than the older os library (which still works just fine). The read_imdb() function return result is a Python tuple where the first item is a Python list of comma-separated reviews, and the second item is a list of associated class labels, 0 for a negative review and 1 for positive.
Loading the Movie Reviews
The demo program begins execution with these statements:
def main():
# 0. get ready
print("Begin fine-tune for IMDB sentiment ")
logging.set_verbosity_error() # suppress warnings
T.manual_seed(1)
np.random.seed(1)
. . .
Suppressing warnings isn't a good idea, but I did so to keep the output tidy for the screenshot in Figure 1. Setting the torch and NumPy random number seeds isn't required but is usually a good idea to try and make program runs reproducible.
The movie review text and labels are loaded into memory like so:
# 1. load raw IMDB train data into memory
print("Loading IMDB train data subset into memory ")
train_reviews_lst, train_labels_lst = \
read_imdb(".\\DataSmall\\aclImdb\\train") # text list
print("Done ")
Tokenizing the Reviews Text
The demo creates a tokenizer object and then tokenizes the reviews text with these two statements:
# 2. tokenize the raw data reviews text
print("Tokenizing training text ")
toker = \
DistilBertTokenizer.from_pretrained( \
'distilbert-base-uncased')
train_tokens = toker(train_reviews_lst, \
truncation=True, padding=True)
In general, each HF model has its own associated tokenizer to break the source sequence text into tokens. This is different from earlier language systems that often use a generic tokenizer such as spaCy. Therefore, the demo loads the distilbert-base-uncased tokenizer. The return result of calling the tokenizer on the IMDB reviews is a data structure that has two components: an input_ids field that holds the integer IDs that correspond to the words in the review text, and attention_mask field that holds 0s and 1s indicating which tokens are active and which tokens to ignore (typically padding tokens).
The tokenized text and attention mask, and the list of class labels are fed to the IMDbDataset constructor:
# 3. load tokenized text and labels into PyTorch Dataset
print("Loading tokenized text into Pytorch Datasets ")
train_dataset = \
IMDbDataset(train_tokens, train_labels_lst)
print("Done ")
The return result is a PyTorch Dataset object that can serve up training items in batches. The underlying items are Dictionary collections with keys [input_ids], [attention_mask], [label].
The pretrained DistilBERT language model is loaded into memory:
# 4. load (possibly cached) pretrained HF model
print("Loading pre-trained DistilBERT model ")
model = \
DistilBertForSequenceClassification.from_pretrained( \
'distilbert-base-uncased')
model.to(device)
model.train() # set mode
print("Done ")
The HF library has many different transformer architecture language models. The demo loads the distilbert-base-uncased model (110 million parameters) into memory. Examples of other models include bert-large-cased (335 million weights trained using Wikipedia articles and book texts), and gpt2-medium (345 million weights), The first time you run the program, the code will reach out using your Internet connection and download the model. On later program runs, the code will use the cached version of the model. On Windows systems the cached HF models are stored by default at C:\Users\(user)\.cache\huggingface\transformers.
Fine-Tuning the Pretrained Model
The pretrained model is fine-tuned by training it using the IMDB data. The HF library has specialized classes for training but you can also train by using standard PyTorch techniques. The demo uses standard PyTorch.
The demo creates a PyTorch DataLoader like so:
# 5. fine-tune / train model using standard PyTorch
print("Loading Dataset bat_size = 10 ")
train_loader = DataLoader(train_dataset, \
batch_size=10, shuffle=True)
print("Done ")
The batch size is a hyperparameter. Because there are 200 reviews, I used a batch size (10) that divides 200 evenly so all batches are the same size.
The training code continues with:
print("Fine-tuning the model ")
optim = AdamW(model.parameters(), lr=5.0e-5) # wt decay
for epoch in range(3):
epoch_loss = 0.0
for (b_ix, batch) in enumerate(train_loader):
optim.zero_grad()
inpt_ids = batch['input_ids']
attn_mask = batch['attention_mask']
lbls = batch['labels']
AdamW is an HF specific optimizer that adds weight decay to a standard PyTorch Adam optimizer. This helps prevent model overfitting. The demo only trains for 3 epochs. In a non-demo scenario you'd train until the loss/error stabilizes. The IMDbDataset works with a DataLoader to serve up items as a Dictionary objects with fields input_ids, attention_mask and labels.
The input information is fed to the pretrained model, loss/error is computed, the loss is used to compute gradients, and the gradients are used to update the model weights and biases:
outputs = model(inpt_ids, \
attention_mask=attn_mask, labels=lbls)
loss = outputs[0]
epoch_loss += loss.item() # accumulate batch loss
loss.backward()
optim.step()
if b_ix % 5 == 0: # 200 items is 20 batches of 10
print(" batch = %5d curr batch loss = %0.4f " % \
(b_ix, loss.item()))
print("end epoch = %4d epoch loss = %0.4f " % \
(epoch, epoch_loss))
# end-batches
# end-epochs
print("Training complete ")
Saving the Fine-Tuned Model
The demo program concludes by saving the trained model to file:
# 6. save trained model weights and biases
print("Saving tuned model state ")
model.eval()
T.save(model.state_dict(), ".\\Models\\imdb_state.pt")
print("Done ")
There are several ways to save a trained PyTorch model. The demo saves the model weights and biases stored in a state dictionary object, but does not save the model definition. The "pt" file extension is not required but is often used. The "pt" extension is slightly preferable to "pth" because "pth" is sometimes used for Python configuration files.
Because the demo only saves model weights, biases and related state information, to use the saved model, you need to instantiate a pretrained distilbert-base-uncased model and then load the saved weights using the torch.load_state_dict() function.
An alternative approach to using PyTorch save and load techniques is to use the HF model.save_pretrained() and model.from_pretrained() methods.
Wrapping Up
The demo program presented in this article is based on an example in the Hugging Face documentation. Fine-tuning a transformer architecture language model is not limited to binary classification. The general pattern is to start with a pretrained language model to get a software English language expert. Then by training/fine-tuning the pretrained language model you can add specific problem domain expertise.
As recently as a few years ago, most of my colleagues were deep learning generalists, meaning that they worked on image recognition, natural language processing and tabular data classification and regression. But over the past three years or so, deep learning has advanced so quickly that many of my colleagues are now specializing in one particular area, such as NLP. That said, there's a general agreement that both generalists and specialists are needed for current and future deep learning systems.