The Data Science Lab
Multi-Class Classification Accuracy by Class Using PyTorch
Dr. James McCaffrey of Microsoft Research: When multi-class data is skewed toward one or more classes, it's very important to analyze accuracy by class.
A multi-class classification problem is one where the goal is to predict a discrete value where there are three or more possibilities. For example, you might want to predict the political leaning (conservative, moderate, liberal) of a person based on their sex, age, state where they live and income.
A naive approach for evaluating the effectiveness of a trained multi-class model is to compute the accuracy of the model on all test data. But suppose your data is skewed toward a particular class. For example, if most of the data items are class moderate (say, 900 out of 1,000) and only a few are class conservative (say, 40 out of 1,000) and class liberal (60 out of 1,000), then a model that predicts class moderate for any input will score 90 percent accuracy.
This article shows how to compute classification accuracy class-by-class. A good way to see where this article is headed is to take a look at the screenshot of a demo program in Figure 1. The demo begins by loading a 200-item set of training data and a 40-item set of test data.
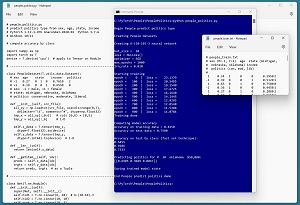 [Click on image for larger view.] Figure 1: Multi-Class Accuracy by Class
[Click on image for larger view.] Figure 1: Multi-Class Accuracy by Class
After training, the overall classification accuracy of the model on the test data is 75.00 percent. The demo then computes accuracy for each of the three classes: conservative (54.55 percent), moderate (92.86 percent) and liberal (73.33 percent). Interpreting accuracy by class is a bit subjective, but the demo results are reasonable.
To run the demo program, you must have Python and PyTorch installed on your machine. The demo programs were developed on Windows 10/11 using the Anaconda 2020.02 64-bit distribution (which contains Python 3.7.6) and PyTorch version 1.12.1 for CPU installed via pip. You can find detailed step-by-step installation instructions for this configuration in my blog posts here and here.
The complete demo program source code can be found here and is also attached to the article as a downloadable compressed file.
The Data
The format of the training and test data looks like:
1 0.24 1 0 0 0.2950 2
-1 0.39 0 0 1 0.5120 1
1 0.63 0 1 0 0.7580 0
-1 0.36 1 0 0 0.4450 1
1 0.27 0 1 0 0.2860 2
. . .
Each line of tab-delimited data represents a person. The fields are sex (male = -1, female = +1), age (divided by 100), state (Michigan = 100, Nebraska = 010, Oklahoma = 001), income (divided by $100,000) and political type (conservative = 0, moderate = 1, liberal = 2).
The complete training and test data can be found here.
The demo defines a PeopleDataset class in Listing 1. An instance of a PeopleDataset object can be passed to a DataLoader for training, or be used directly to compute classification accuracy.
Listing 1: PeopleDataset Class Definition
class PeopleDataset(T.utils.data.Dataset):
def __init__(self, src_file):
all_xy = np.loadtxt(src_file, usecols=range(0,7),
delimiter="\t", comments="#", dtype=np.float32)
tmp_x = all_xy[:,0:6] # cols [0,6) = [0,5]
tmp_y = all_xy[:,6] # 1-D
self.x_data = T.tensor(tmp_x,
dtype=T.float32).to(device)
self.y_data = T.tensor(tmp_y,
dtype=T.int64).to(device) # 1-D
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
preds = self.x_data[idx]
trgts = self.y_data[idx]
return preds, trgts # as a Tuple
The Demo Program
The structure of the demo program is presented in Listing 2. I prefer to indent my Python programs with two spaces rather than the more common four spaces. The backslash character is used for line continuation in Python.
Listing 2: Overall Demo Program Structure
# people_politics.py
# predict politics type from sex, age, state, income
# PyTorch 1.12.1-CPU Anaconda3-2020.02 Python 3.7.6
# Windows 10/11
# compute accuracy by class
import numpy as np
import torch as T
device = T.device('cpu') # apply to Tensor or Module
# -----------------------------------------------------------
class PeopleDataset(T.utils.data.Dataset): . . .
# -----------------------------------------------------------
class Net(T.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hid1 = T.nn.Linear(6, 10) # 6-(10-10)-3
self.hid2 = T.nn.Linear(10, 10)
self.oupt = T.nn.Linear(10, 3)
T.nn.init.xavier_uniform_(self.hid1.weight)
T.nn.init.zeros_(self.hid1.bias)
T.nn.init.xavier_uniform_(self.hid2.weight)
T.nn.init.zeros_(self.hid2.bias)
T.nn.init.xavier_uniform_(self.oupt.weight)
T.nn.init.zeros_(self.oupt.bias)
def forward(self, x):
z = T.tanh(self.hid1(x))
z = T.tanh(self.hid2(z))
z = T.log_softmax(self.oupt(z), dim=1) # NLLLoss()
return z
# -----------------------------------------------------------
def accuracy(model, ds):
# assumes model.eval()
# item-by-item version
n_correct = 0; n_wrong = 0
for i in range(len(ds)):
X = ds[i][0].reshape(1,-1) # make it a batch
Y = ds[i][1].reshape(1) # 0 1 or 2, 1D
with T.no_grad():
oupt = model(X) # logits form
big_idx = T.argmax(oupt) # 0 or 1 or 2
if big_idx == Y:
n_correct += 1
else:
n_wrong += 1
acc = (n_correct * 1.0) / (n_correct + n_wrong)
return acc
# -----------------------------------------------------------
def do_acc(model, dataset, n_classes):
X = dataset[0:len(dataset)][0] # all X values
Y = dataset[0:len(dataset)][1] # all Y values
with T.no_grad():
oupt = model(X) # [40,3] all logits
for c in range(n_classes):
idxs = np.where(Y==c) # indices where Y is c
logits_c = oupt[idxs] # logits corresponding to Y == c
arg_maxs_c = T.argmax(logits_c, dim=1) # predicted class
num_correct = T.sum(arg_maxs_c == c)
acc_c = num_correct.item() / len(arg_maxs_c)
print("%0.4f " % acc_c)
# -----------------------------------------------------------
def main():
# 0. get started
print("Begin People predict politics type ")
T.manual_seed(1)
np.random.seed(1)
# 1. create DataLoader objects
print("Creating People Datasets ")
train_file = ".\\Data\\people_train.txt"
train_ds = PeopleDataset(train_file) # 200 rows
test_file = ".\\Data\\people_test.txt"
test_ds = PeopleDataset(test_file) # 40 rows
bat_size = 10
train_ldr = T.utils.data.DataLoader(train_ds,
batch_size=bat_size, shuffle=True)
# -----------------------------------------------------------
# 2. create network
print("Creating 6-(10-10)-3 neural network ")
net = Net().to(device)
net.train()
# -----------------------------------------------------------
# 3. train model
max_epochs = 1000
ep_log_interval = 100
lrn_rate = 0.01
loss_func = T.nn.NLLLoss() # assumes log_softmax()
optimizer = T.optim.SGD(net.parameters(), lr=lrn_rate)
print("bat_size = %3d " % bat_size)
print("loss = " + str(loss_func))
print("optimizer = SGD")
print("max_epochs = %3d " % max_epochs)
print("lrn_rate = %0.3f " % lrn_rate)
print("Starting training")
for epoch in range(0, max_epochs):
epoch_loss = 0 # for one full epoch
for (batch_idx, batch) in enumerate(train_ldr):
X = batch[0] # inputs
Y = batch[1] # correct class/label/politics
optimizer.zero_grad()
oupt = net(X)
loss_val = loss_func(oupt, Y) # a tensor
epoch_loss += loss_val.item() # accumulate
loss_val.backward()
optimizer.step()
if epoch % ep_log_interval == 0:
print("epoch = %5d | loss = %10.4f" % \
(epoch, epoch_loss))
print("Training done ")
# -----------------------------------------------------------
# 4. evaluate model accuracy
print("Computing overall model accuracy")
net.eval()
acc_train = accuracy(net, train_ds) # item-by-item
print("Accuracy on training data = %0.4f" % acc_train)
acc_test = accuracy(net, test_ds)
print("Accuracy on test data = %0.4f" % acc_test)
print("Accuracy on test by class (fast technique): ")
do_acc(net, test_ds, 3)
# 5. make a prediction
print("Predicting for M 30 oklahoma $50,000: ")
X = np.array([[-1, 0.30, 0,0,1, 0.5000]],
dtype=np.float32)
X = T.tensor(X, dtype=T.float32).to(device)
with T.no_grad():
logits = net(X) # do not sum to 1.0
probs = T.exp(logits) # sum to 1.0
probs = probs.numpy() # numpy vector prints better
np.set_printoptions(precision=4, suppress=True)
print(probs)
# 6. save model (state_dict approach)
print("Saving trained model state")
# fn = ".\\Models\\people_model.pt"
# T.save(net.state_dict(), fn)
print("End People predict politics demo")
if __name__ == "__main__":
main() main()
All the control logic is in a program-defined main() function. The program begins with some preparation statements:
import numpy as np
import torch as T
device = T.device('cpu') # apply to Tensor or Module
def main():
# 0. get started
print("Begin People predict politics type ")
T.manual_seed(1)
np.random.seed(1)
. . .
After loading data into memory, the multi-class classifier is created and training is prepared. Training is accomplished using standard techniques.
Evaluating Accuracy by Class
The key do_acc() function that defines accuracy by class is presented in Listing 3. The function accepts a Dataset object which holds either training or test data.
Listing 3: Accuracy by Class Function
def do_acc(model, dataset, n_classes):
X = dataset[0:len(dataset)][0] # all X values
Y = dataset[0:len(dataset)][1] # all Y values
with T.no_grad():
oupt = model(X) # [40,3] all logits
for c in range(n_classes):
idxs = np.where(Y==c) # indices where Y is c
logits_c = oupt[idxs] # logits corresponding to Y == c
arg_maxs_c = T.argmax(logits_c, dim=1) # predicted class
num_correct = T.sum(arg_maxs_c == c)
acc_c = num_correct.item() / len(arg_maxs_c)
print("%0.4f " % acc_c)
First, all the inputs are stored into X and all the target outputs are stored into Y. The outputs are in the form of logits where the location of the largest output corresponds to the class (0, 1, 2). The output of the do_acc() function is a print() statement that summarizes the classification for each class. In a non-demo scenario, you might want to return the acc_c matrix that holds the results.
Wrapping Up
When multi-class data is skewed toward one or more classes, it's very important to analyze accuracy by class. This means that before starting work on a multi-class prediction system, it's almost always a good idea to analyze the training data to determine if there is any data skewed by class.
About the Author
Dr. James McCaffrey directs the data science and research efforts at Quaetrix, a data analytics company located near Redmond, Washington. Before joining Quaetrix, James was a senior research engineer at Microsoft. James can be reached at [email protected].