Ask Kathleen
Applying Model-View-View Model in Silverlight
Careful planning can help improve the manageability and quality of your next-generation Silverlight applications.
Q: I'm creating a Silverlight application and I'm trying to decide what architecture to use. The more I read the more confused I become. Why is a View Model important in Silverlight, and how do I avoid duplicating common code like validation logic? My background is writing WinForms applications.
A: Silverlight represents a new paradigm because it offers a fully isolated user interface that can only interact with the server in an asynchronous manner. In this way it's a bit like a Web app. But it also runs your client-side code within the CLR, rather than a browser-based scripting language like JavaScript. This opens the door to creating much richer user interfaces-similar to a rich client application but with less work. The best line-of-business Silverlight applications are built on new thinking, and not on dragging forward habits from WinForms or ASP.NET.
While you're running in a .NET CLR on the client side, it's not the same CLR, and you'll actually have entirely separate assemblies running on your Silverlight platform with a subset of the .NET CLR available.
Introducing this dual-platform mode and combining isolated asynchronous service access with a rich programming environment may be enough to confuse architectural issues. However, the introduction of Silverlight coincides with two other significant changes: breaking up apps into independent testable units, and moving behaviors out of objects and into logical services. "Exercise-Driven Development?" explains why building more granular applications with defined boundaries has many benefits, and that a testable app has benefits far beyond testability.
Designing your Silverlight applications is a good venue to introduce these techniques. I'll explain an architectural approach that addresses these issues called Model-View-View Model (MVVM). Keep in mind that this is a dynamic space where the Silverlight best practices are emergent. My goal is to clarify the general approach; the right details for your application may be a little different. You can also download sample code.
The approach I'll describe leverages Silverlight capabilities and maximizes code reuse. You can reconstitute the same object with data and behavior on both the Silverlight and .NET side of the application, but I think it's simpler to use data-only objects, which are often called Data Transfer Objects (DTOs) or just data objects. Classes containing logical services can use these DTOs and be compiled into both your Silverlight and .NET applications, without needing to actually reconstitute the classes with data.
Logical services provide an environment where you can manage your application as a series of granular pieces. Using composability tools like Managed Extensibility Framework (MEF), you can round up all the players that wish to contribute to the validation or authorization story. (See "MEF on Silverlight" and "Working with MEF," April 2009, to learn more about the role of MEF.)
Figure 1 shows one way to logically divide the Silverlight application pipeline. The orange line represents the physical service boundary. The dotted lines indicate one pattern for separating the logical units into differently assemblies, and I've superimposed the assembly names from the sample application. The decision around assembly boundaries is likely to raise quite a bit of discussion. I opt for more assemblies to enforce isolation and improve composability and testability. It's also easier to combine assemblies later than to separate them.
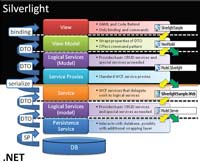
[Click on image for larger view.] |
| Figure 1. You'll make several key decisions as you develop Silverlight architectures. These decisions include managing code on two distinct platforms, which require separately compiled assemblies, handling asynchronous communications and passing data along the pipeline. Planning boundaries create a testable-and therefore more maintainable-application. |
Diving In
This design is probably more complex than your WinForms apps, but you could drop the View Model and the logical business services on the client side, and interact directly with the service. However, the logical business services allow a straightforward reduction in redundant code and the View Model simplifies the true UI layer, which is the view.
This MVVM pattern removes logic from the view by relying on data binding and a command pattern. The view is the user control, the model is the business data and logical services, and the View Model is the bridge between them. One of the benefits of MVVM is it simplifies the view and separates all your logic so you can find it and potentially reuse it across different technologies. Reuse is often an elusive goal, but even if you can't reuse it directly, relying solely on data binding and commanding makes it much easier to understand what your application accomplishes. One of the distinctions between logic in the View Model and logic in the model is that the model's code can be reused within the Silverlight application, as well as from ASP.NET, WinForms, Workflow and services.
The View Model has a direct one-to-one relationship with a specific view: It's literally the port between a specific view and the model. Views have identical structure whether they provide operational data, such as log-in username and password, or persisted data, such as customer detail. The binding data context of the view is the View Model, such as LoginViewModel. If you rely heavily on styles, and you apply implicit styles in code or through the upcoming implicit style manager, your view can be very simple:
<!-- Ommitting row/column defs -->
<TextBlock Grid.Row="1" Grid.Column="1" >UserName</
TextBlock>
<TextBlock Grid.Row="2" Grid.Column="1" >Password</
TextBlock>
<TextBox x:Name="userNameTextBox" Grid.Row="1" Grid.
Column="2" Text="{Binding Path=UserName,
Mode=TwoWay}" TextChanged="userNameTextBox_
TextChanged" />
<TextBox x:Name="passwordTextBox" Grid.Row="2" Grid.
Column="2" Text="{Binding Path=Password,
Mode=TwoWay}" TextChanged="passwordTextBox_
TextChanged"></TextBox>
<Button Content="Login" Grid.Column="3" Grid.Row="1"
x:Name="LoginButton" IsEnabled="{Binding
Path=CanLogin}" Click="LoginButton_Click"/>
<Button Content="Cancel" Grid.Column="3" Grid.Row="2"
x:Name="CancelButton" Click="CancelButton_Click"/>
Commanding makes it abundantly clear what functions the user expects to perform when using the application. Commanding presents challenges because Silverlight doesn't offer a command pattern. Keeping things simple, the sample View Model contains a property named CanLogin. I bind the IsEnabled property of the log-in button to this property. This works because the View Model implements INotifyPropertyChanged, and the UserName and Password properties raise the PropertyChanged event both for themselves and CanLogin. One other small detail is that Silverlight only updates the source of two-way data-binding when the user leaves the field. This would cause a delay that would be confusing to the user. So, I catch the TextChanged event of the textboxes to force the update of the LoginViewModel on every keystroke.
All interaction with the server is asynchronous and goes through Windows Communication Foundation (WCF) Services. For most business apps, this means a large percentage of the behavior is asynchronous on the Silverlight side and synchronous on the server side. Asynchronous behavior requires a request to perform an action and a callback or event mechanism to handle completion of the action.
The sample application uses log in as an example of a process. It's not intended as a true log-in process and ignores security implications to focus on the mechanics. The view routes the log-in request to the View Model via a simple command model. The user name and password are available in the View Model because of the two-way data binding. The View Model routes the request to the model (logical service), which makes an asynchronous call to the WCF service and sets a callback delegate.
When the service completes, WCF plumbing calls the callback method in the model. This callback method creates the data object and raises an event. The argument for this event contains the data object. The LoginViewModel catches this event and creates a UserViewModel. The LoginViewModel raises an event containing the UserViewModel in its argument.
The log-in view catches this event to initiate UI navigation by raising a view-specific event. The point of using events is the focus on what has happened, which is known by each of these players. They don't know what should happen next. In this case, a startup user control catches the log-in view event and replaces the log-in view with the user view. Your application will probably display the chrome of a master view at this point. While this multi-step route takes some getting used to, it preserves the isolation of each piece. Like the log-in view, the user view contains only data-binding, commanding and technology-specific code.
View Models are slaves of their views, and there's a one-to-one relationship between views and View Models. Navigation happens in the view, or perhaps in a navigation engine or service. As a precursor to navigation, View Models sometimes interact with each other. In the sample, the log-in View Model creates the user View Model.
Note that the logical business layer appears on both the .NET and Silverlight sides. I generally keep the common files on the .NET side, with the Silverlight project accessing these files as links. Linked files exist only in the main location and any changes to them are reflected in all assemblies. In Solution Explorer, you create links by right-clicking the project and selecting Add/Existing Item and navigating to its actual location. Once you've selected the files, use the down arrow on the Add button to select Add As Link.
While you want to share certain types of code between the server and Silverlight assemblies, sharing other types of code is not appropriate. For example, the synchronous and asynchronous pipelines for log in will each be used only on one side. You can share part of a class while isolating other parts with partial classes. The UserServices.Silverlight and UserServices.Server files contain the part of the UserServices class that should exist only on one platform. There's no need to create platform-specific code for the data class, so it has no associated partial classes.
Displaying a message when log in is not successful illustrates the power of Silverlight (or WPF) data binding. Rather than have the view make its own determination, you can add a Boolean property to the log-in View Model that indicates an invalid attempt, and add a string property for the message. Binding to the text is straightforward, but the visibility property is an enumeration that's specific to Silverlight, not a Boolean. You can use a
Silverlight value converter to bridge the gap between these two types and maintain appropriate isolation:
<TextBlock x:Name="invalidMessageTextBlock"
Grid.Row="3" Grid.Column="1" Grid.ColumnSpan="2"
Text="{Binding Path=InvalidMessage}"
Visibility="{Binding Path=InvalidAttempt,
Converter={StaticResource VisibilityConverter}}
"/>
There are a number of details that can trip you up when you build this architecture. When you create the service reference, it creates the ServiceReferences.ClientConfig in the assembly that contains the service reference. However, the client configuration file must be available in the main Silverlight assembly, so you'll need to add a link to this file. Because of the large number of parts that make up a Silverlight application, good naming is essential. Add an extra suffix to clarify the intent of projects and partial classes. You'll need to manually remove this suffix from the namespace specified in the project properties.
Regardless of the complexity of the pipeline you choose, draw it out and be clear with your team on the logical, assembly and service-boundary locations. If you don't understand the intended boundaries, you can't possibly maintain a consistent architecture. You'll also want to be clear on where data exists: In Figure 1, data is outside the pipeline, in data objects that are passed along the pipeline (as shown on the left side of the graphic).
As testability is also a measure of composability and separation of concerns, be sure to understand where the testing boundaries lie, and while you're prototyping your architecture, write at least enough tests to ensure the validity of these boundaries. The yellow and green arrows on the right side of Figure 1 indicate planned testing boundaries. The yellow arrows indicate where testing can commence in the application, and the green arrows indicate where mocks can be inserted. Note that I've combined the Silverlight logical business services and the service references (called service proxies in Figure 1) in the same assembly without a commitment to mocking. This means business logic on the Silverlight side can't be tested without involving a WCF service, although that WCF service could be an alternate service providing mock data. Ideally every logical break would be testable, but architecture is not a perfect sculpture for display. Rather, your architecture is a pragmatic solution that produces an application today and eases maintenance and evolution across the life of the application.