Code Focused
Using Memory-Mapped Files in the .NET Framework 4
Find out how to use memory-mapped files to index and search the contents of document collections.
I recently had the pleasure of introducing Visual Studio 2010 and the Microsoft .NET Framework environment to Dean, a widely respected, unmanaged-code developer. Despite my best efforts to paint an attractive picture of the technical beauty of the depth and breadth of the .NET Framework development environment, he was barely interested.
Dean had devoted much of his career to writing software that indexes and searches the contents of very large document collections. He was keen to know how to do what he has always done, but with .NET Framework-based code. His very first question to me was, "How do I parse a 15GB text file?" Newbie questions always start easy and then get harder, right?
"Memory-mapped files," I replied. "They're definitely the way you want to work with very large files."
Memory-mapped files (MMFs) are not new. Windows NT and later versions of Windows are page-based virtual-memory OSes. MMFs are essentially an extension of an existing highly optimized internal memory management system. What is new with the release of the .NET Framework 4 is the ability to tap into the power of MMFs with managed code.
Non-persisted MMFs exist solely in system memory and are used for inter-process communication (IPC); persisted MMFs are used to read and/or write physical disk files. Both types allow concurrent access from multiple processes in either a random or sequential manner, and both types use the MemoryMappedFile namespace in the .NET Framework 4. To learn more about using non-persisted MMFs for IPC, see the CreateNew method.
MMFs use the virtual memory manager of the OS, which reads and writes all memory in 4KB chunks. This direct mapping between your application's memory space and physical disk file means that any file can be randomly or sequentially accessed in a single view up to the limit of the application's logical address space, which is 2GB for a 32-bit application. If your file exceeds that size -- and indexing a 15GB document certainly would -- additional views can be created and mapped to the file as needed. Views can start at any point in the file. The larger views and the ability to start a view at any desired position within the file ease the coding of working with very large files.
Can persisted MMFs provide superior performance when processing very large files? To answer Dean's question, we'll build a sample application using MMFs to create, index and validate the index for a 15GB text file. Figure 1 shows the main form of the sample application.
[Click on image for larger view.] |
| Figure 1. The sample application main form. |
Creating a Large Text File to Index
The first challenge is to create a 15GB text file. Using a source text file of more than 200,000 words, the TestFile.Create method writes a text file of a specified length, where each line of the text file consists of all the words separated by a single space, optionally removing 10 randomly selected words in each line in order to avoid completely duplicate lines. See Listing 1.
Indexing the File
Next we need to create an index that may be representative of the kind of indexing we might find in a real-world application. To make it interesting, the application will create an index of each five-letter word that contains the uppercase or lowercase letter "R." The index will consist of the word found and the exact position of the first letter of the word within the file. The same word will appear multiple times throughout the source file. The index will be written out as a comma-separated value (CSV) file, where each index entry is its own line. This will make the index easily accessible for later use.
Demonstration programs are often simple examples and shy away from any heavy lifting -- not this time. On my computer, this demonstration program processed the full 15GB text file, producing more than 15 million index entries in less than an hour, as shown in Figure 2. Your mileage may vary depending on your hardware configuration.
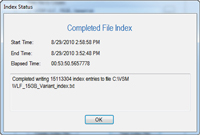
[Click on image for larger view.] |
| Figure 2. Using memory-mapped files, the sample application created more than 15 million index entries in less than an hour. |
Using an MMF for an existing file is straight-forward. First, we create an instance of the System.IO.MemoryMappedFiles.Memo- ryMappedFile object, using the CreateFromFile method. Next, we create a sequential or random view (accessor) of a specified length at a specified starting position. Data is obtained by reading individual value types by relative position within the view. Then we create a 100MB view into the large text file, and as each view is processed we create the next 100MB view at the beginning of the last word found. This ensures that no word is split across two views and eliminates the logic needed to handle partial words. In other words, if the view ended at the letter "g" of the word "tiger," the next view would start on the letter "t" of tiger. This ability to slightly backtrack to the beginning of the last word greatly simplifies the coding of the word-detection logic. The code that creates the index entry list in memory is shown in Listing 2. The list is then passed to a routine that dumps it out to disk, as shown here:
Public Sub WriteIndexFile(ByVal IndexEntries As List(
Of IndexEntry), ByVal IndexFilePath As String)
Try
Using IndexFile As
New System.IO.StreamWriter(IndexFilePath)
For i As Integer = 0 To IndexEntries.Count - 1
IndexFile.WriteLine(IndexEntries(i).CSV)
Next
End Using
Catch ex As Exception
Throw New Exception("IndexingLargeFiles.IndexEntry.
WriteIndexFile: " + ex.Message)
End Try
End Sub
In Listing 2, you see a simple IndexEntry class that will hold the word and its position. The ToString method is overridden to return the word as its display name in case it's used in a drop-down list. The CSV and TabSeparated methods were added to make it easy to export to those formats.
In the CreateIndexEntryList method, the majority of the variables are declared outside the Try-Catch block in order to have them remain in scope for examination should an exception occur. Only one view is active at any time; a new one is created each 100MB to "slide" down the file as it's processed. A message is written to the console each time a view is created to be able to monitor its progress with minimal impact. The text is read a byte at a time. When a word delimiter character is seen, the word and its starting position are added to the List(Of IndexEntry) if it has five letters and contains an uppercase or lowercase letter "R."
Note that there's no mechanism in a memory-mapped view to read a string, so reading the word to add it to the IndexEntry class requires a loop to read each byte, convert it to a character and append it to any previous characters of the word until finished. When indexing a very large file, this is likely being done thousands or millions of times, so a single instance of the StringBuilder object is used to construct each word. This eliminates the performance hit from garbage collection after creating and discarding a large number of strings.
Testing the Index
Finally, we need to test the index file to see if it was created properly. With more than 15 million entries to test, the validation must be automated. To be meaningful, the validation is done using a different method than the one used when the index was originally created. The method TestIndexFile uses the more conventional technique of reading the 15GB text file as lines of text and splitting up the line into words. This provides independent verification of the results. It also serves as a performance comparison of the MMF processing to the more standard approach for reading text files.
TestIndexFile reads the index created earlier and builds a List(Of IndexEntry) from it. Then it reads each line of the 15GB text file. It breaks this line up into words using the string.Split method and then determines the starting position of each word that matches our criteria of five letters and containing the letter "R." It creates the equivalent IndexEntry class and then searches the List(Of IndexEntry) for a match. If a match is found, it deletes the matching entry from the List. If a match is not found -- meaning the indexing process missed a word -- it writes the word and its file position to the console and increments the error count. If more than 100 errors are found, the validation process is terminated so that significant validation time is not spent on poorly indexed files.
Superior Performance
Using MMFs, an index containing more than 15 million entries was created in less than an hour from a 15GB source text file. Testing the index using the traditional sequential file line-input approach validated 45 percent of the entries in a 72-hour period. Using MMFs is at least two orders of magnitude faster.
Both the 15GB text file used for this article and the resulting index are in the code download. Using the open source 7-Zip program available at 7-zip.org, the 15GB text file has been compressed to only 3.3MB! You can use 7-Zip to expand both files to their full size.
Remember that MMFs are not just for reading large files. They can be used to create new files, update existing files or share information for IPC. I'm confident you'll find that MMF processing is an important tool in your developer toolbox.
About the Author
Joe Kunk is a Microsoft MVP in Visual Basic, three-time president of the Greater Lansing User Group for .NET, and developer for Dart Container Corporation of Mason, Michigan. He's been developing software for over 30 years and has worked in the education, government, financial and manufacturing industries. Kunk's co-authored the book "Professional DevExpress ASP.NET Controls" (Wrox Programmer to Programmer, 2009). He can be reached via email at [email protected].