In-Depth
Scale ASP.NET Apps Through Distributed Caching
High-transaction environments can use distributed caching to boost performance without major code changes.
ASP.NET has become a highly popular technology for developing Web applications. A large number of these ASP.NET applications need to scale to accommodate the growing number of transactions and traffic they support.
During the client/server era, scalability wasn't really a concern because there weren't that many concurrent users. Today, with Web technologies, you can easily have hundreds of thousands of users, which causes issues with data storage.
ASP.NET architecture allows applications to scale by adding more Web servers in a load-balanced Web farm. However, in ASP.NET, data storage is not very scalable when it comes to handling a growing number of transactions. As a result, if you increase the transaction load, the data storage starts to slow down and eventually grinds to a halt.
Reducing Bottlenecks
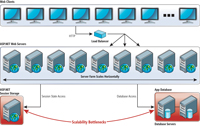
In an ASP.NET application, data storage usually means either the application database or the ASP.NET Session State storage -- and herein lie application-scalability bottlenecks, as shown in Figure 1. The application database is normally a relational database, such as SQL Server or another relational database. ASP.NET Session State storage is one of the three options that Microsoft provides -- namely InProc, State Server or SQLServer modes. In all of these storage options, scalability is a major issue. I'll explain this in more detail later in this article.
[Click on image for larger view.] |
| Figure 1. In an ASP.NET application, data storage usually means either the application database or the ASP.NET Session State storage. |
The question is: How do you resolve this scalability bottleneck? How do you ensure that you can keep growing the number of transactions, as well as the number of users supported by the ASP.NET application?
One way is to use an in-memory distributed cache. A distributed cache can be used for two types of data. One is caching application data that otherwise resides in your application. This helps your application reduce those expensive database trips and improve performance and scalability. The second is to store all transient data, including ASP.NET Session State, in the distributed cache and never store this type of data in a relational database. In this case, distributed cache becomes the master storage for this transient data.
Caching application data in a distributed cache allows you to reduce database trips for reading the same data over and over again, which can overwhelm the database server. This frees up the application database to handle writes more efficiently and support a larger number of users. And to really reap the benefits of caching, you don't just cache read-only data; you also cache transactional or read-write data. Transactional data changes frequently, sometimes every 15 to 30 seconds. Even during this short time, your application ends up reading this data many times. When you multiply this scenario by the total number of users and transactions, you quickly realize that the overall traffic to the database increases dramatically.
In caching application data, the goal is to reduce those application database trips by 70 percent to 90 percent. This means 70 percent to 90 percent of the time you shouldn't even be going to the database. Instead, you should just be getting your data from the distributed cache.
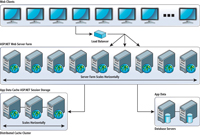
A distributed cache is an in-memory data store that can span multiple inexpensive cache servers. It pools together their memory and CPU power to provide a very scalable architecture. You can keep adding more cache servers to the distributed cache cluster as your transaction load increases, providing linear scalability for handling transactions. As shown in Figure 2, a distributed cache efficiently fits into the application architecture; it provides scalability and reduces pressure on the database.
[Click on image for larger view.] |
| Figure 2. A distributed cache efficiently fits into the application architecture; it provides scalability and reduces pressure on the database. |
Caching Application Data
You cache application data so you can reduce database trips and remove scalability bottlenecks in your application database. In most cases, you modify your application source code to make calls to a distributed cache API. Listing 1 is an example of how you can use a distributed cache in a .NET application for caching application data.
Using Cache Without Code Changes
In some cases, you can start using a distributed cache in your .NET application without modifying your code. NHibernate, for instance, is an open source object-relational mapping engine for .NET applications. It relieves developers from a significant portion of relational data persistence-related programming tasks. NHibernate has a pluggable L2 Cache provider architecture that allows you to seamlessly plug in a third-party distributed cache without making any code changes to your .NET application. You only modify your app.config file.
The Entity Framework (EF) is also an object-relational mapping engine for .NET provided by Microsoft. Although the EF does not yet provide a pluggable L2 Cache provider model like NHibernate, some third-party distributed caches have implemented a custom ADO.NET provider for the EF that intercepts database queries and caches their results based on your preferences. You can do this without making any code changes to your .NET application. Of course, if you prefer, you can always make code changes and directly call a distributed cache when you receive a collection of entities from the EF.
Distributed Cache for Application Data
Although I can't detail all of the caching features and capabilities that a distributed cache should have in this article, here are some important ones with respect to application data:
Absolute and sliding expirations: This allows you to specify when individual cache items should expire and be automatically removed from the cache. You can either specify an absolute date-time or an interval of inactivity as criteria.
Cache dependency for managing data relationships: Most data that you cache comes from relational databases and therefore has relationships. By keeping track of these in the cache, you can let the cache manage data integrity in the cache and simplify your application.
Synchronize cache with database: For application data caching, the cache is keeping only a copy of the data in the database. So, if this data changes in the database, it would be nice if the cache could learn about it automatically and synchronize itself either by removing that item from the cache or reloading a new copy from the database.
Read-through and write-through: Sometimes your application directly reads data from the database and caches it. Other times, you want the cache to read the data for you because this simplifies your application code and also provides other benefits. For this latter case, you need read-through and write-through.
Groups and tags: If you can group multiple cached items in various ways, you can find them more easily later. Groups allow each item to belong to only one group, whereas Tags provide a many-to-many grouping with cached items. Both features give you great flexibility in fetching data or keeping track of it in the cache.
SQL-like Cache Query and LINQ: Typical cache fetch is based on a key, because every cached item has a key. Many times, however, you want to search for items based on other criteria. Cache Query allows you to provide a SQL-like query to search the cache based on object attributes rather than the key. And LINQ makes it really simple to do so from within a .NET environment.
Event notifications: Often, your application wants to be notified when some of the data changes in the cache. A good cache should provide various event-propagation mechanisms. One is key-based event notification, which is triggered by an individual cached item update. Second is a general-purpose event triggered whenever anything in the cache is updated or removed. Third is a Continuous Query that's triggered whenever an item in a criteria-based data set in the cache is updated or removed. All of these allow your applications to fully make use of the cache.
Storing ASP.NET Sessions in Distributed Cache
The second use of a distributed cache is to store temporary data in the cache and never store this data in the database. One good example is ASP.NET Session State. The three storage options for ASP.NET Session State storage that Microsoft provides -- InProc, State Server and SQLServer -- are all inadequate. InProc can't handle multiple server (Web farm) or even multiple worker process (Web garden) configurations. State Server is a standalone, out-of-process store and doesn't replicate sessions, and also doesn't scale at all. And the SQLServer option has the same performance and scalability problems.
But a distributed cache resolves both of these issues. A distributed cache is linearly scalable. It also replicates the ASP.NET Sessions intelligently to ensure that there's no data loss even if a cache server goes down.
The best thing about storing ASP.NET Session State in a distributed cache is that, unlike application data caching, it requires no programming. The reason is that the ASP.NET Session State storage framework offers a "custom" mode that allows you to seamlessly plug in third-party data stores to an ASP.NET application.
With the "custom" mode, you can plug in any of the leading distributed caches available. Some products are free; others are commercial. Whichever one you choose, make sure that cache provides not only scalability but intelligent replication, so there's no data loss.
Caching Topologies
Unlike a database that uses persistent storage, a distributed cache uses volatile memory as its store. Therefore, a distributed cache has to ensure data reliability through data replication across multiple cache servers to make certain that all data is kept on at least two cache servers. Then, if any one server goes down, no data is lost.
There are various caching topologies (or data storage and replication strategies) for distributed cache.
In a replicated cache topology, the entire cache is stored on more than one server and copied on multiple servers. The more servers there are in the distributed cache cluster, the more copies of the cache you make. Therefore, this type of topology is only effective if you're performing a lot of reads but very few updates of data in the cache.
The reason for fast reads is that each cache server contains the entire cache. So, all applications connected to this server have very quick access to this data.
However, updates aren't as fast as reads because all cache servers have to be updated synchronously whenever an application issues an update against any one cache server. "Synchronously" here means the application waits until all cache servers are successfully updated. So the more cache servers you have, the slower the updates become, because you have to update that many servers simultaneously.
A partitioned cache breaks up the cache into partitions and assigns one partition to each cache server. All application instances (or cache clients) connect to all cache servers so they can directly go to the server where their desired data is stored.
This partitioning provides two benefits. First, the storage space keeps growing as you add more servers. This doesn't happen in replicated cache, where total storage space is based on how much memory is available in any one cache server.
The second benefit is that the cost of individual reads and writes remains the same even when you add more cache servers (again, this is unlike the replicated cache, where writes slow down). This allows you to linearly scale your transaction capacity and handle extreme transaction loads just by adding more cache servers to the cache cluster.
Partitioned cache is a really powerful caching topology. But it has one drawback, which is that it doesn't do any replication. The lack of replication in partitioned cache can be a major drawback for you for two reasons.
First, if you're storing transient data like ASP.NET Session State, the distributed cache is your only master data store. Therefore, any data loss may be very undesirable for your business.
Second, even if you're caching application data and have all data in your database, losing a partition at peak hours could have high performance costs because suddenly your application is making a lot more database trips until all data from this lost partition is fetched again from the database.
There's a variation of partitioned cache called partitioned and replicated cache. This hybrid topology provides the benefits of partitioned cache in terms of scalability, and replicated cache in terms of reliability. All data is copied to two different servers.
The ideal situation for you might be to have the scalability benefit of partitioning but at the same time have reliability similar to that of a replicated cache. In this caching topology, each partition has a replica on a different cache server. This ensures that there are two copies of all data, but also avoids having too many copies. So, although there's additional cost of replication in partitioned-replicated caching topology, it's very small and this cost stays linear and doesn't hamper your linear-scalability requirement.
Finally, a client cache is a "local cache" on the Web or the app server, but with one difference: It's connected to the distributed cache cluster in order to stay synchronized with it for any data changes. Client cache is not a replacement of replicated cache, partitioned cache or replicated-partitioned cache. Rather, it works with any of them. The purpose of a client cache is to provide a "local cache" very close to your application, and in-process caching if needed.
If any data changes in the distributed cache, the distributed cache notifies the client caches with this data item so they can update themselves. Client cache gives your application a very powerful "local cache" without worrying about data-integrity issues.
A distributed cache should provide client cache as a configurable option so you don't have to write special code in your application to use it. All you do is enable it through your configuration file. Client cache keeps data automatically based on the usage pattern of each cache client application to which it's attached.
The benefit of a client cache is that it's a cache on top of your distributed cache. It caches data close to your application so your application doesn't even have to go to the distributed cache, just like a distributed cache caches data so you don't have to go to the database. Thus, client cache adds a further boost to the overall performance and scalability of your ASP.NET application. It does so because accessing data really close by makes the performance much faster -- and it also reduces the pressure on the distributed cache, which makes it more scalable. When a distributed cache becomes more scalable, then the database also becomes more scalable.
One thing to keep in mind is that you're using distributed cache because you're anticipating a high-transaction environment for your application. This usually means your ASP.NET application has a greater impact on your business. Therefore, you can't afford any unscheduled downtimes for your application, and even the scheduled downtimes should be short and infrequent.
A distributed cache runs in your datacenter as part of your ASP.NET application, so it must provide high availability in itself.
Self-Healing Cache Clustering
An important aspect of this high availability is that the cache cluster must be self-healing and totally, dynamically configurable. Some caches provide a manually fixed cache cluster (so your application code creates and manages the cluster). Other caches use master/slave architecture; if the master node goes down, all the slaves either stop working or become read-only. Both architectures are severely limiting and inflexible.
A good distributed cache has a peer-to-peer cache clustering that corrects itself automatically at runtime (thus self-healing) if you add or remove cache servers from the cache cluster or if a cache server crashes for some reason.
You should seriously consider incorporating a distributed cache for application data caching and for ASP.NET Session State storage if you're developing an ASP.NET application targeted for a high-transaction environment.
One thing to keep in mind is that there are a number of free distributed caches available, and it might be tempting to adopt one of them. However, if your ASP.NET application is business-critical, you must consider the total cost of ownership and not just the price of a distributed cache (even if it's free).