C# Corner
HTTP Basics for REST-Based App Development
Go inside the protocol that's the backbone for today's modern, cloud-based applications.
While typing in a URL and pressing Enter inside a browser is effortless, there's a lot more going on behind the scenes. In this article, I'll review some of the basics of HTTP and show how they're being used in today's modern, REST-based applications.
Tools of the Trade
Examining the raw HTTP traffic that goes back and forth between a client and server is actually quite easy these days. Many modern browsers allow you to view all of the network traffic they transmit and receive. I wrote an article earlier this year on using Chrome's developer tools to examine network traffic (using the "Network" panel). If you're running outside the browser, you may want to consider Fiddler2. It's a standalone Windows Forms application that can monitor and display traffic from any running application, as shown in Figure 1.
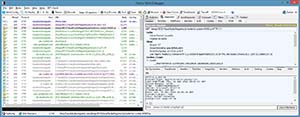 [Click on image for larger view.]
Figure 1. Sample Fiddler2 screen.
[Click on image for larger view.]
Figure 1. Sample Fiddler2 screen.
Protocol Versions
There are two main HTTP protocols: Version 1.0 and Version 1.1. I could spend an entire article going over the differences between the two. For brevity's sake, the key takeaway is that HTTP 1.1 was designed to be backward-compatible with 1.0. The 1.1 specification took the (never formally specified) 1.0 protocol and added some enhancements and clarifications. For this article, I'll be describing the 1.1 protocol, as many REST-based services require the 1.1 protocol.
Simple Communications
HTTP is a very simple protocol -- by design. A simpler protocol is easy to implement and, therefore, easier to adopt. Obviously, this simplicity has paid off: HTTP is used by millions of applications every day, most of those Web browsers (on both regular and mobile devices).
Every HTTP message is single request and a single response. That's it. No complicated sequences or any special handshaking. A client opens a connection (by default, on port 80) and sends a request to the server. The server processes the request and sends back a response. The connection is closed. This is done for every message. Obviously, with a connection being opened and closed each time, HTTP is a stateless protocol. Any state information to be shared between client and server must be retransmitted on each request. By being stateless, subsequent HTTP requests don't need to go to the same server as the first request (this makes a load balancer's job much easier).
If you've ever done any Web forms development and seen the giant hidden field called "__VIEWSTATE," that's an example of state transmission. The state of every control on a Web forms page is passed back and forth. This allows the server to "rehydrate" the state of the Web form, act on the request and send back a complete "state" of the new Web form. This response is then processed by the browser by rendering an updated page.
Requests
The first part of an HTTP message, the request, consists of three parts:
- The Uniform Resource Identifier (URI) : Identifies the resource the client wants to act on.
- The Method: Indicates what is to be done to the URI (explained in more detail below).
- Headers: Additional meta-data information about the request.
Request Methods
The most common methods you'll see are GET and POST (these two, along with "HEAD," were part of the original 1.0 protocol). Here's a basic description of the more common methods:
- GET: This is a request to return a particular resource to the client. This can be anything from an HTML document to a .ZIP file. From a protocol standpoint, HTTP doesn't care what is being returned.
- POST: This is a request to "accept" a resource being sent from the client. I put the term accept in quotes for a reason. The HTTP spec doesn't define this as a "create" or as an "update" operation. However, the POST method is generally considered a "create" operation in REST implementations.
- HEAD: This is identical to a GET request, except the resource itself isn't returned. This can be used to conserve bandwidth by skipping a full GET if it isn't necessary.
- PUT: Introduced in HTTP 1.1, this method is defined to be an update to an existing resource.
- DELETE: Introduced in HTTP 1.1, this method is used to delete an existing resource.
- OPTIONS: Introduced in HTTP 1.1, this method allows the client to query the server about its capabilities. One implementation of this method is for AJAX requests across different domains (a.k.a., CORS, or cross origin resource sharing).
Responses
Once a request has been sent, the server processes it and returns a response. The three parts of an HTTP response are:
- The Response Code: Identifies the result of the request.
- Headers: Additional meta-data information about the response.
- Body: The actual body of the response. This is not required and a response can contain a zero-length body (but will still contain the response code and headers).
Response Codes
The response code is the key part of the response. It lets the client know exactly what happened during the processing of the request. Response codes are three-digit codes. The first digit defines the class of the response:
- 1xx: Informational. You normally don't see these in browser-based or REST-based applications.
- 2xx: Successful. A 2xx-level response code means the request was received, understood and processed successfully.
- 3xx: Redirection. Further action must be taken by the client to complete the request.
- 4xx: Client error. There was an error with the request sent by the client.
- 5xx: Server error. The server encountered a problem processing the request from the client.
Here are some typical response codes you'll see while monitoring HTTP traffic:
- 200 OK: The request has succeeded. The requested resource has been returned in the response body.
- 201 Created: This response from a POST indicates a new resource was created.
- 301 Moved Permanently: The URI requested has been assigned to a new URI, and that new URI will be returned as a response header (specifically, the "Location" header).
- 302 Found: The URI requested was found, but it resides temporarily at a new URI, which is indicated in the "Location" header.
- 304 Not Modified: When a resource is originally requested, the client sometimes saves information about the URI (i.e., the browser caches the response). Later calls for this same resource will include information (like last modified date) as a way to eliminate the need for retransmission of the resource if it hasn't changed. We'll look at this one later.
- 400 Bad Request: The client sent a poorly formed request.
- 401 Unauthorized: The URI requested requires authentication, but that authentication was not included with the request.
- 403 Forbidden: The URI requested exists, but the client does not have access to it.
- 404 Not Found: We've all seen this one. No explanation required, right?
- 405 Method Not Allowed: The method in the request is not allowed for the particular URI.
- 503 Service Unavailable: The server is not able to process the request.
The Browser in Action
Now I can show you how all of this comes together in a typical Web request. Figure 2 shows a screenshot of the HTTP messages sent back and forth by Chrome when loading the Visual Studio Magazine home page:
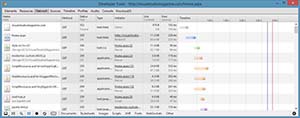 [Click on image for larger view.]
Figure 2. Loading the Visual Studio Magazine home page.
[Click on image for larger view.]
Figure 2. Loading the Visual Studio Magazine home page.
To see this information, press F12 to open up the Chrome Developer Tools. Click on the "Network" tab, then go to the address bar and enter "http://visualstudiomagazine.com."
You'll notice the very first request (GET on visualstudiomagazine.com) resulted in a status code of 302 (Found). Remember that a 302 instructs the client to look elsewhere for the resource. I can click on the request in Chrome and see details for that one request, as shown in Figure 3:
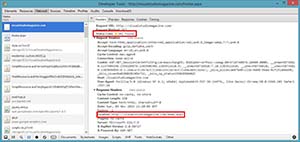 [Click on image for larger view.]
Figure 3. HTTP Redirect.
[Click on image for larger view.]
Figure 3. HTTP Redirect.
With a 302 response code, the server sent a response header of "Location" with the new location. The browser then made a request to "Home.aspx", which resulted in a 200 (OK). You can also see the "Type" column shows "text/html." At this point, the browser actually has the HTML that defines the home page.
The rest of the requests are all part of the browser parsing the HTML and processing it. There are follow-up requests for images, JavaScript, stylesheets and so on. This is all specific to the application (a Web browser), but it's all being done via the HTTP protocol.
To see more examples of how a browser can use the HTTP protocol effectively, I intentionally cleared my browser cache before doing the request above. This meant all of the images, stylesheets and other elements of the page had to be requested and downloaded to my machine. In doing that, the server returned information on "last-modified" dates of some of the resources. The browser will use this information and send it, along with subsequent requests. This gives the server the option to not send all of that data again if it hasn't changed.
Figure 4 is a screenshot of my network traffic after hitting F5 to refresh the VisualStudioMagazine.com home page:
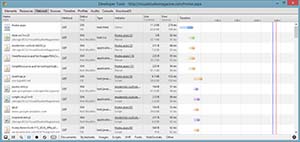 [Click on image for larger view.]
Figure 4. HTTP Refresh.
[Click on image for larger view.]
Figure 4. HTTP Refresh.
Notice that what was previously 200 (OK) responses for some of the resources (images, stylesheets and so on) are now all 304 (Not Modified). This means the server saw that the client already had the most recent copy of these resources and didn't need to re-download it. This saves bandwidth and response times. These savings can be substantial. On the initial request (with nothing in my browser's cache), the bottom of the Network panel in Chrome displayed the statistics for what it captured:
99 requests, 2.3 MB transferred
The F5 refresh produced the following statistics:
74 requests, 328KB transferred.
With the browser caching all of those resources, the follow-up request only needed to download 328KB -- a whopping 86 percent reduction in traffic! The details of how this caching is done is out of the scope of this article, but if you're curious, research the HTTP headers "if-modified-since" and "if-none-match." A very interesting use of the HTTP protocol!
HTTP and REST
REST is an architectural style, and HTTP is a protocol. It's entirely possible to do REST over something other than HTTP, but REST was developed in parallel with HTTP 1.1, so it utilizes many of the same concepts.
For these examples, I'm going to use Fiddler2 to monitor my HTTP traffic from a WPF application that uses a REST service for maintaining a list of author names.
When I run the application, the first request I see is an HTTP GET on the "/api/authors" resource, as shown in Figure 5.
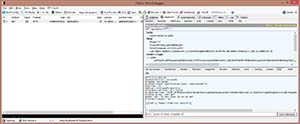 [Click on image for larger view.]
Figure 5. HTTP Request on REST endpoint.
[Click on image for larger view.]
Figure 5. HTTP Request on REST endpoint.
On the right side of the screen, Fiddler2's "Inspectors" tab is split into two sections: The top part is information about the request, and the bottom part shows the response. On the bottom part, I've selected "Raw" as the display mode which shows the raw HTTP response. Since I know this is a JSON request, I can click on the "JSON" tab and Fiddler2 will treat the response body as a JSON packet and display it in a more organized format, as shown in Figure 6.
 [Click on image for larger view.]
Figure 6. Fiddler2 displaying JSON data.
[Click on image for larger view.]
Figure 6. Fiddler2 displaying JSON data.
Now I go in to my WPF application and add a new author. When I hit "Save," I see Fiddler2 captures the POST that creates the new resource shown in Figure 7.
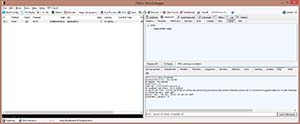 [Click on image for larger view.]
Figure 7. HTTP POST to REST endpoint.
[Click on image for larger view.]
Figure 7. HTTP POST to REST endpoint.
I then change the type of display for the HTTP Request to show JSON data, like I did earlier for the bottom part. This allows you to see the structured JSON data that was sent to the URI. Also note the 201 (Created) response. This lets the WPF client know that the author entry was created. If I were to call the initial GET again, I would see the new author in the response body, as shown in Figure 8.
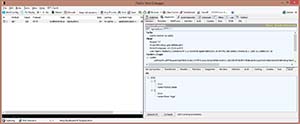 [Click on image for larger view.]
Figure 8. HTTP GET showing updated data.
[Click on image for larger view.]
Figure 8. HTTP GET showing updated data.
Finally, I decide to delete the author I just created (nothing personal, Peter!). The WPF application uses the HTTP "DELETE" method, along with the URI that represents the author to delete, as shown in Figure 9.
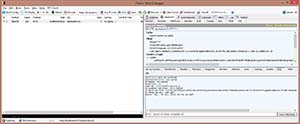 [Click on image for larger view.]
Figure 9. HTTP call to DELETE resource.
[Click on image for larger view.]
Figure 9. HTTP call to DELETE resource.
The response to a DELETE is really up to the server. Some REST endpoints will return a copy of the deleted resource. This one simply returns a 204 (No Content) response. It's a 2xx response, so the WPF application knows the delete was successful.
Real-World Usage
You may question the value of knowing some of the details of the HTTP protocol -- especially since the browser and/or REST framework handles a lot of this for you. The value comes in to play when you have a problem. Let's say a client is calling your REST service and getting a 401 (Unauthorized) message. They swear they're doing the authentication properly. You could have them install Fiddler2 and capture one of the requests, e-mail it to you and verify the request. Or maybe one of your own apps is interfacing with a third-party REST service. Watching the network traffic with Fiddler2 can help diagnose problems you may be seeing.
I hope this basic overview of HTTP has answered some of those "How does that work?" questions you may have asked in the past. If you'd like to learn more about the HTTP protocols, you can review the complete spec in all its goodness here.