Neural Network Lab
How To Reuse Neural Network Models
Neural network models can be created, saved and reused. Here's how.
A neural network model consists of the network's architecture and defining numeric values. Did you know you can create, save and reuse a neural network model? I'll show you how in this month's column.
A network architecture is the number of input, hidden, and output nodes, and a description of how those nodes are connected. In most cases neural networks are fully connected so that all input nodes are connected to all hidden nodes, and all hidden nodes are connected to all output nodes.
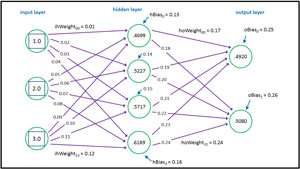
The defining numeric values are the values of the weights and biases. Each input-to-hidden node connection and hidden-to-output node connection has an associated weight. Each hidden node and each output node has an associated bias. For a neural network with n input nodes, h hidden nodes, and o output nodes, there are (n * h) + h + (h * o) + o weights and biases. For example, the 3-4-2 neural network in Figure 1 has (3 * 4) + 4 + (4 * 2) + 2 = 26 weights and biases.
 [Click on image for larger view.]
Figure 1. A 3-4-2 Network Has 26 Weights and Biases
[Click on image for larger view.]
Figure 1. A 3-4-2 Network Has 26 Weights and Biases
The behavior of a neural network is also defined by two activation functions. For neural network classifiers, where the goal is to predict a discrete value (for example, predicting the political party affiliation of a person), the softmax activation function is almost always used on the output nodes. The most common activation function for hidden nodes is the hyperbolic tangent (tanh) function, but the logistic sigmoid function is sometimes used.
Working with neural networks usually involves trial and error. The number of hidden nodes is a free parameter (sometimes called a hyper parameter), and the parameters used during training to find good values for the weights and biases are also free parameters. For the most common form of training, back-propagation, training parameters usually include the learning rate (how much weights and biases change during each training iteration), the momentum rate (an optional value that both increases training speed and can prevent training from getting stuck at poor values for the weights and biases) and, optionally, a weight decay rate (to prevent over-fitting).
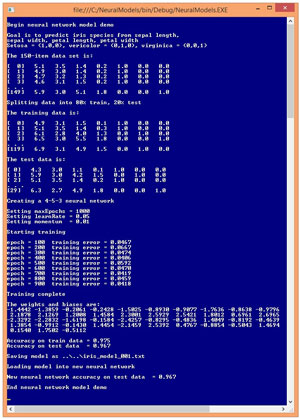
The best way to see where this article is headed is to examine the screenshot of a demo program shown in Figure 2. The goal of the demo program is to predict the species of an iris flower (Iris setosa or Iris versicolor or Iris virginica) using the flower's sepal (a leaf-like structure) length and width, and petal length and width.
 [Click on image for larger view.]
Figure 2. Neural Network Model Demo Run
[Click on image for larger view.]
Figure 2. Neural Network Model Demo Run
The demo data is part of a famous data set called Fisher's Iris Data. The full data set has three species and there are 50 examples of each species so the demo has a total of 150 data items. The raw data was preprocessed by using 1-of-N encoding where setosa is (1, 0, 0), versicolor is (0, 1, 0) and virginica is (0, 0, 1).
The four numeric predictor variables, sepal length and width, and petal length and width, were not normalized because the values all have roughly the same magnitude and so no one predictor will dominate the others.
The source data was randomly split into a training set and a test set. The training set has 80 percent of the items (120) and the test set has the remaining 20 percent of the items (30).
The demo creates a 4-5-2 neural network. There are four input nodes, one for each predictor variable. The number of hidden nodes, five, was determined using trial and error. There are three output nodes because the there are three possible classes to predict.
The demo program uses the back-propagation algorithm to find the values of the weights and biases so that the computed output values (using training data input values) closely match the known correct output values in the training data. After training the values of the 43 weights and biases are displayed, and the accuracy of the model is calculated and displayed. The model correctly predicts 97.5 percent of the training items (117 out of 120) and 96.7 percent of the test items (29 out of 30).
The demo then saves the information that defines the neural network in a text file named iris_model_001.txt. The demo creates a new, empty neural network, and loads the saved model into the new network. The accuracy of the new neural network on the test data is 96.7 percent as it should be, because the two neural networks are the same.
This article assumes you have at least intermediate-level developer skills and a basic understanding of neural networks. The demo program is too long to present in its entirety here, but complete source code is available in the download that accompanies this article. All normal error checking has been removed to keep the main ideas of neural network models as clear as possible.
The Demo Program
To create the demo program I launched Visual Studio and selected the C# console application project template. I named the project NeuralModels. The demo has no significant Microsoft .NET Framework dependencies so any version of Visual Studio will work.
After the template code loaded, in the Solution Explorer window I right-clicked on file Program.cs and renamed it to the more descriptive NeuralModelsProgram.cs and then allowed Visual Studio to automatically rename class Program. At the top of the template-generated code in the Editor window, I deleted all unnecessary using statements, leaving just the reference to the top-level System namespace. Then I added a using statement for the System.IO namespace so that methods to read from and write to text files could be accessed easily.
The overall structure of the demo program is shown in Listing 1. Helper method load data reads the source iris data from a text file and stores it into an array-of-arrays-style matrix. Method SplitData creates a reference copy of the source data and splits it into a training set and a test set. All of the neural network logic is contained in a program-defined class called NeuralNetwork
Listing 1: Demo Program Structure
using System;
using System.IO;
namespace NeuralModels
{
class NeuralModelsProgram
{
static void Main(string[] args)
{
// All program control statements
}
static double[][] LoadData(string dataFile,
int numRows, int numCols) { . . }
static void SplitData(double[][] allData,
double trainPct, int seed,
out double[][] trainData,
out double[][] testData) { . . }
public static void ShowMatrix(double[][] matrix,
int numRows, int decimals,
bool indices) { . . }
public static void ShowVector(double[] vector,
int decimals, int lineLen,
bool newLine) { . . }
}
public class NeuralNetwork { . . }
} // ns
The Main method loads and displays the source data with these statements:
double[][] allData =
LoadData("..\\..\\IrisData.txt", 150, 7); // 150 rows, 7 cols
ShowMatrix(allData, 4, 1, true); // 4 items, 1 decimal
You can easily find the raw iris data set in several places on the Internet, and then encode the species values using a text editor replace command. The source data is split into training and test sets, like so:
double[][] trainData = null;
double[][] testData = null;
double trainPct = 0.80;
int splitSeed = 1;
SplitData(allData, trainPct, splitSeed,
out trainData, out testData);
The choice of the seed value (1) for the random number generator was arbitrary. The neural network is created with these statements:
int numInput = 4;
int numHidden = 5;
int numOutput = 3;
NeuralNetwork nn =
new NeuralNetwork(numInput, numHidden, numOutput);
The neural network is fully connected, and the tanh hidden node activation function is hardcoded. A big advantage of writing custom neural network code is that you can keep the size of your source code much smaller than when writing code intended to be used by people who do not have access to the source code. The neural network is trained with these statements:
int maxEpochs = 1000;
double learnRate = 0.05;
double momentum = 0.01;
bool progress = true;
double[] wts = nn.Train(trainData, maxEpochs,
learnRate, momentum, progress);
The accuracy of the neural network is then calculated:
double trainAcc = nn.Accuracy(trainData);
double testAcc = nn.Accuracy(testData);
At this point the program could be closed, losing the values of the weights and biases. This isn't a problem because the neural network could be easily recreated and retrained. But in more complex situations where training can take hours or even days, you'd want to save your model. The demo model is saved with these statements:
string modelName = "..\\..\\iris_model_001.txt";
nn.SaveModel(modelName);
Here the model is saved as a text file. With rise of more sophisticated data formats such as XML, OData, and JSON, sometimes it's easy to forget that ordinary text files are often simple and effective. The contents of the resulting model text file are:
numInput:4
numHidden:5
numOutput:3
weights:-1.4442,-1.3859,-0.2061,(etc),-0.5112
The weights and bias values are stored together. The first 4 * 5 = 20 values are for the input-to-hidden weights matrix, in row major form (left to right, top to bottom). The next five values are the hidden node biases. Next come 5 * 3 = 15 values for the hidden-to-output weights matrix. And then the last three values are the output node biases.
A new neural network is created and the saved model is loaded with these statements:
NeuralNetwork nm = new NeuralNetwork();
nm.LoadModel(modelName);
double modelAcc = nm.Accuracy(testData);
The new neural network, named nm, has data members for the number of input nodes, the input-to-hidden node weights, and so on, but none of these data members are initialized. The LoadModel method takes the information from the trained network and uses it to initialize the network.
What Defines a Model?
Understanding exactly what a neural network model is, is probably best understood by looking at code. The definition for class method SaveModel is presented in Listing 2.
Listing 2: Method SaveModel
public void SaveModel(string modelName)
{
FileStream ofs = new FileStream(modelName,
FileMode.Create);
StreamWriter sw = new StreamWriter(ofs);
sw.WriteLine("numInput:" + this.numInput);
sw.WriteLine("numHidden:" + this.numHidden);
sw.WriteLine("numOutput:" + this.numOutput);
sw.Write("weights:");
for (int i = 0; i < ihWeights.Length; ++i)
for (int j = 0; j < ihWeights[0].Length; ++j)
sw.Write(ihWeights[i][j].ToString("F4") + ",");
for (int i = 0; i < hBiases.Length; ++i)
sw.Write(hBiases[i].ToString("F4") + ",");
for (int i = 0; i < hoWeights.Length; ++i)
for (int j = 0; j < hoWeights[0].Length; ++j)
sw.Write(hoWeights[i][j].ToString("F4") + ",");
for (int i = 0; i < oBiases.Length - 1; ++i)
sw.Write(oBiases[i].ToString("F4") + ",");
sw.WriteLine(oBiases[oBiases.Length-1].ToString("F4"));
sw.Close();
ofs.Close();
}
Method SaveModel essentially creates a configuration file. The number of input, hidden and output nodes are written, one to a line, with a leading identifier. The weights and biases are written sequentially, to four decimal places, with a comma character as a delimiter. This is about as simple a format as possible and is feasible because the code is intended for someone who has the ability to access and modify the source code.
The definition for class method LoadModel is presented in Listing 3. The method opens the model file without doing any error checking. When writing code for personal use, it's often a tough decision to decide when to put error checking code in, often doubling the number of lines of code, and when to leave error checking out. Of course, in a production environment you must include error checking.
Listing 3: Method LoadModel
public void LoadModel(string modelName)
{
FileStream ifs = new FileStream(modelName,
FileMode.Open);
StreamReader sr = new StreamReader(ifs);
int numInput = 0;
int numHidden = 0;
int numOutput = 0;
double[] wts = null;
string line = "";
string[] tokens = null;
while ((line = sr.ReadLine()) != null)
{
if (line.StartsWith("//") == true) continue;
tokens = line.Split(':');
if (tokens[0] == "numInput")
numInput = int.Parse(tokens[1]);
else if (tokens[0] == "numHidden")
numHidden = int.Parse(tokens[1]);
else if (tokens[0] == "numOutput")
numOutput = int.Parse(tokens[1]);
else if (tokens[0] == "weights")
{
string[] vals = tokens[1].Split(',');
wts = new double[vals.Length];
for (int i = 0; i < wts.Length; ++i)
wts[i] = double.Parse(vals[i]);
}
}
sr.Close();
ifs.Close();
this.numInput = numInput;
this.numHidden = numHidden;
this.numOutput = numOutput;
this.inputs = new double[numInput];
this.ihWeights = MakeMatrix(numInput, numHidden);
this.hBiases = new double[numHidden];
this.hOutputs = new double[numHidden];
this.hoWeights = MakeMatrix(numHidden, numOutput);
this.oBiases = new double[numOutput];
this.outputs = new double[numOutput];
this.rnd = new Random(4); // Same as ctor
this.SetWeights(wts);
}
Notice method LoadModel is coded to allow you to insert C#-style comment lines. In most cases you'd want to add information such as the training parameter values, location of the training data and so on.
After reading the saved values from the model text file, method LoadModel uses the values to allocate space for the arrays that hold the weights and bias values, and then assigns values for numInput, numHidden, numOutput, and the weights and biases.
The seed value for the Random object, 4, is the same as used in the primary constructor method. This is a brittle design and a more robust alternative is to parameterize the primary constructor to accept a seed value, and modify methods SaveModel and LoadModel so that the constructor seed value is saved and loaded just as the other model parameters.
Wrapping Up
Saving and retrieving a custom neural network model isn't too difficult from a technical point of view. The more difficult aspect of neural network models is defining exactly what constitutes your model and designing a good calling interface. Based on my experience at least, there are very few useful general guidelines other than the saying attributed to Albert Einstein, "Everything should be as simple as possible, but not simpler."
The software theme of this article is that when you're writing code intended to be used by yourself, or possibly a colleague, you can make your code much simpler than when you're writing code intended for an external audience of some sort. For example, the demo program presented in this article used a hardcoded hyperbolic tangent function as the hidden node activation function. This permits the model design to leave out the choice of activation function. This is fine because as long as you have access to the source code, you can easily change the activation function. But if you were writing neural network code as a general library, you'd have to include every imaginable activation function, which in turn would complicate any model.