Q&A
Q&A with Ken Muse: Designing Azure Modern Data Warehouse Solutions
The Modern Data Warehouse (MDW) pattern makes it easier than ever to deal with the increasing volume of enterprise data by enabling massive, global-scale writes operations while making the information instantly available for reporting and insights.
As such, it's a natural fit for cloud computing platforms and the field of DataOps, where practitioners apply DevOps principles to data pipelines built according to the architectural pattern on platforms like Microsoft Azure.
In fact, Microsoft has published DataOps for the modern data warehouse guidance and a GitHub repo featuring DataOps for the Modern Data Warehouse as part of its Azure Samples offerings.
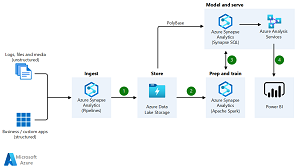 [Click on image for larger view.] Architecture of an Enterprise Data Warehouse (source: Microsoft).
[Click on image for larger view.] Architecture of an Enterprise Data Warehouse (source: Microsoft).
And, speaking of GitHub, one of the leading experts in the MDW field is Ken Muse, a senior DevOps architect at the Microsoft-owned company who has published an entire series of articles on the pattern titled "Intro to the Modern Data Warehouse." There, he goes into detail on storage, ingestion and so on.
It just so happens that Muse will be sharing his knowledge at a big, five-day VSLive! Developer Conference in Nashville in May. The title of his presentation is Designing Azure Modern Data Warehouse Solutions, a 75-minute session scheduled for May 16.
Attendees will learn:
- Define and understand how to implement the MDW architecture pattern
- How to determine appropriate Azure SQL and NoSQL solutions for a workload
- Understand how to ingest and report against high volume data
We caught up with Muse, a four-time Microsoft Azure MVP and a Microsoft Certified Trainer, to learn more about the MDW pattern in a short Q&A.
VisualStudioMagazine: What defines a Modern Data Warehouse in the Azure cloud?
Muse: A Modern Data Warehouse combines complementary data platform services to provide a secure, scalable and highly available solution for ingesting, processing, analyzing and reporting on large volumes of data. This architectural pattern supports high-volume data ingestion as well as flexible data processing and reporting. In the Azure cloud, it often takes advantage of services such as Azure Data Lake Storage, Azure Synapse Analytics, Azure Data Factory, Azure Databricks, Azure Cosmos DB, Azure Analysis Services, and Azure SQL.
How does the cloud improve a MDW approach as opposed to an on-premises implementation?
The cloud provides an elastic infrastructure that can dynamically scale to meet ingestion and analysis needs. Teams only pay for what they need, and they have access to virtually limitless storage and compute capacity that can be provisioned in minutes. This makes it faster and easier to turn data into actionable insights.
With an on-premises environment, the infrastructure must be sized to meet the peak needs of the application. This often results in over-provisioning and wasted resources. Hardware failures and long supply chain lead times can restrict teams from scaling quickly or exploring new approaches.
 "Maintaining and optimizing each service can be time-consuming and complex. The cloud eliminates these issues by providing optimized environments on demand."
"Maintaining and optimizing each service can be time-consuming and complex. The cloud eliminates these issues by providing optimized environments on demand."
Ken Muse, Senior DevOps Architect, GitHub
In addition, maintaining and optimizing each service can be time-consuming and complex. The cloud eliminates these issues by providing optimized environments on demand.
As developers often struggle to figure out the right tools -- like SQL vs. NoSQL -- for implementation, can you briefly describe what goes into making that choice, like the benefits and/or drawbacks of each?
The choice between SQL and NoSQL is often driven by the type of data you need to store and the types of queries you need to run. SQL databases are optimized for highly structured data, complex queries, strong consistency, and ACID transactions. They are natively supported in nearly every development language, making it easy to get started quickly. They can be an optimal choice for applications that commit multiple related rows in a single transaction, perform frequent point-updates, or need to dynamically query structured datasets. The strong consistency model is often easier for developers to understand. At the same time, horizontal scaling can be challenging and expensive, and performance can degrade as the database grows.
NoSQL ("not only SQL") solutions are optimized for unstructured and semi-structured data, rapidly changing schemas, eventual consistency, high read/write volumes, and scalability. They are often a good choice for applications that need to store large amounts of data, perform frequent reads and writes, or need to dynamically query semi-structured data. They can ingest data at extremely high rates, easily scale horizontally, and work well with large datasets. They are often the best choice for graph models and understanding complex, hidden relationships.
At the same time, eventual consistency can be challenging for developers to understand. NoSQL systems frequently lack support for ACID transactions, which can make it more difficult to implement business logic. Because they not designed as a relational store, they are often not an ideal choice for self-service reporting solutions such as Power BI.
This is why the MDW pattern is important. It rely on the strengths of each tool and selects the right one for each job. It enables using both NoSQL and SQL together to support complex storage, data processing, and reporting needs.
What are a couple of common mistakes developers make in implementing the MDW pattern?
There are three common mistakes developers make in implementing the MDW pattern:
- Using the wrong storage type for ingested data: Teams frequently fail to understand the differences between Azure storage solutions such as Azure Blob Storage, Azure Files, and Azure Data Lake Storage. Picking the wrong one for the job can create unexpected performance problems.
- Forgetting that NoSQL solutions rely on data duplication: NoSQL design patterns are not the same as relational design patterns. Using NoSQL effectively often relies on having multiple copies of the data for optimal querying and security. Minimizing the number of copies can restrict performance, limit security, and increase costs.
- Using Azure Synapse Analytics for dynamic reporting: Azure Synapse Analytics is a powerful tool for data processing and analysis, but it is not designed for high-concurrency user queries. Direct querying from self-service reporting solutions such as Power BI is generally not recommended. It can provide a powerful solution for building the data models that power self-service reporting when used correctly or combined with other services.
With the massive amounts of data being housed in the cloud, what techniques are useful to ingest and report against high-volume data?
For ingesting high volume data as it arrives, queue-based and streaming approaches are often the most effective way to capture and land data. For example, Azure Event Hubs can be used to receive data, store it in Azure Data Lake Storage, and optionally deliver it as a stream to other services, including Azure Stream Analytics. For larger datasets, it can be advisable to store the data directly into Azure Blob Storage or Azure Data Lake Storage. The data can then be processed using Azure Data Factory, Azure Synapse Analytics, or Azure Databricks. They key is to land the data as quickly as possible to minimize the risk of data loss and enable downstream rapid analysis.
For reporting, it's important to optimize the data models for the queries that will be run. The optimal structures for reporting are rarely the same as those used for ingestion or CRUD operations. For example, it's often more efficient to denormalize data for reporting than it is to store it in a normalized form. In addition, column stores generally perform substantially better than row-based storage for reporting. As a result, separating the data capture and data reporting aspects can help optimize the performance of each.
How can developers support high volumes of read/write operations without compromising the performance of an application?
An important consideration for developers is the appropriate separation of the read and write operations. When read and write operations overlap, it creates contention and bottlenecks. By separating the data capture and data reporting aspects, you can optimize the performance of each. You can also select services which are optimized for that scenario, minimizing the development effort required.
For applications that need to support CRUD (create, read, update, delete) operations, this can require changing the approach. For example, it may be necessary to use a NoSQL solution that supports eventual consistency. It may also be necessary to persist the data in multiple locations or use change feeds to propagate updates to other services.
In other cases, tools such as Azure Data Factory may be more appropriate. It can periodically copy the data to a different data store during off-peak hours. This can help minimize the impact of the changes to the application. This can be important when the needs of the application change suddenly or when the application does not have to provide up-to-the-moment reporting data.
What are some key Azure services that help with the MDW pattern?
The key services used in the MDW pattern are typically Azure Data Lake Storage Gen2, Azure Synapse Analytics, Azure Databricks, Azure SQL, and Azure Event Hubs.
That said, there are many other services that can be used to support specific application and business requirements within this model. For example, Azure Machine Learning can be used to quickly build insights and models from the data. Azure Cosmos DB can be used to support point-queries and updates with low latency. Services like Azure Purview can be used to understand your data estate and apply governance. The MDW pattern is about understanding the tradeoffs between the different services to appropriate select ones that support the business requirements.
As AI is all the rage these days, do any of those Azure services use hot new technology like large language models or generative AI?
Absolutely! A key part of the Modern Data Warehouse pattern is supporting machine learning, and that includes generative AI and new techniques that development teams might be working to create themselves.
Azure's newest offering, Azure OpenAI Service, is a fully managed service that provides access to the latest state-of-the-art language models from OpenAI. It is designed to help developers and data scientists quickly and easily build intelligent applications that can understand, generate, and respond to human language.
In addition, Azure recently announced the preview of the ND H100 v5 virtual machine series. These are optimized to support the training of large language models and generative AI. These virtual machines boost the performance for large-scale deployments by providing eight H100 Tensor Core CPUs, 4th generation Intel Xeon Processors, and high-speed interconnects with 3.6 TBps of bidirectional bandwidth among the eight local GPUs. You can learn more here.
About the Author
David Ramel is an editor and writer at Converge 360.