News
Complex AI Prompting: 'Putting the Prompt Last Helps the LLM to Stay on Task'
As AI takes hold in the enterprise, Microsoft is educating developers with guidance for more complex use cases in order to get the best out of advanced, generative machine language models like those that power ChatGPT and the company's Copilot assistants that are popping up all over.
And, as the industry has discovered, that means becoming more facile with prompt engineering, which is simply constructing queries to be fed to large language models (LLMs) in order to get back relevant, business-actionable results. In fact, the new discipline of prompt engineering earlier this year gave rise to help wanted ads with top annual salary ranges of more than $300,000.
Just today, Microsoft continued its complex prompting education with a treatment for summarizing medical research publications, detailed in the post, "Large Language Model Prompt Engineering for Complex Summarization." The goal of the exercise is to demonstrate the leveraging of LLM capabilities to generate summaries of medical documents for non-specialist readers.
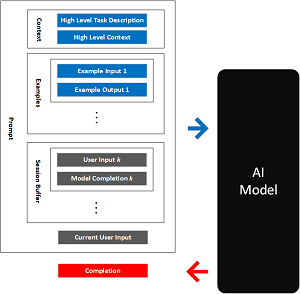 [Click on image for larger view.] An Example LLM Prompt (source: Microsoft).
[Click on image for larger view.] An Example LLM Prompt (source: Microsoft).
Microsoft's John Stewart ran through the process, which required multiple prompting tweaks to finally get a suitable outcome. Along the way, he provides developers with helpful tips that can only be learned through real-world trial and error. For just one example, he explained how in one iteration of the prompt he received better results by transposing the example text with the prompt. Most prompts typically start out with directions to do something, like analyze some text to be submitted later by the user (such as the medical document to be examined and summarized). Stewart, though, demonstrated how he got better results by first providing the example text, followed by the prompt, along with some other fine-tuning steps.
"This is quite a bit better!" he said of the new response. "It includes some context from the patient-perspective. It's got a nice disclaimer at the end. One thing to note is we're now including the source study text above our prompt. This helps with the recency problem with LLMs. Putting the prompt last helps the LLM to stay on task."
Microsoft describes that "recency problem" thusly: "Models can be susceptible to recency bias, which in this context means that information at the end of the prompt might have more significant influence over the output than information at the beginning of the prompt. Therefore, it is worth experimenting with repeating the instructions at the end of the prompt and evaluating the impact on the generated response."
Stewart's demo involved Microsoft's Azure OpenAI service, along with the LangChain Python library as a harness for using the cloud service along with OpenAI's GPT-3 LLM.
His starting hypothesis was:
A model like OpenAI's Davinci-3, the original LLM that underpinned ChatGPT, could produce a passable Plain Language Summary of medical text describing a drug-study, which could then be refined by an author or editor in short time. We targeted a complete summary, including important details from the source text like patient population, treatment outcomes, and how the research impacted disease treatment. In particular, we wanted the following:
- Summaries should be approximately 250 words
- Specialist medical terms should be replaced with common language
- Complex medical concepts should be explained 'in-context' with a short plain language definition
- The summary should explain the study aim, protocol, subject population, outcome, and impact on patient treatment and future research
- The summary should be informative enough for the reader to get a full understanding of the source paper
He started with this basic prompt:
prompt_template = """
Write a Plain Language Summary of the medical study below:
{study_text}
"""
chain = LLMChain(llm=llm, prompt=PromptTemplate.from_template(prompt_template))
summary = chain.run(study_txt)
print(summary)
# count the number of words in the summary
print(f"PLS length: {len(summary.split())}")
and after several tweaks and tunes, ended up with this prompt, which he described as not perfect and requiring more work to get even better results:
prompt_template = """
You are a medical researcher writing a Plain Language Summary of your study for a layperson.
{study_text}
Write a Plain Language Summary of the above medical study for a layperson.
Translate any medical terms to simple english explanations.
Use first-person 'We'. Use short bullet points.
Answer these questions:
- What was the purpose of the study?
- What did the researchers do?
- What did they find?
- What does this mean for me?
Write 250 words at a 6th grade reading level.
"""
chain = LLMChain(llm=llm, prompt=PromptTemplate.from_template(prompt_template))
summary = chain.run(study_txt)
print(summary)
Stewart listed the following key takeaways from his exercise:
- Ensure your 'source' text to be summarized is above the prompt to help mitigate the 'recency problem'
- Give detailed, direct prompts that specify the output such as number of words, reading level, etc.
- If you can guide the model by providing the start of the output you want. In our example you could provide the first question of a question/answer style summary as the start of model generation
- If necessary consider 'multi-step' summary generation to ensure you get more consistent, focused output
"In the future we hope to bring you examples of managing longer text input, usage of GPT4, and chat-based interactions for fine-tuning the summarization output," Stewart said in conclusion. "As well we may be able to exploit GPT4's abilities to 'understand' charts, graphs and tables. We also hope to explore the idea of using GPT to 'grade itself' by evaluating the generated output against our ideal summary criteria. In this way we hope to move from qualitative prompt generation to quantitative Prompt Engineering."
About the Author
David Ramel is an editor and writer at Converge 360.