The Data Science Lab
Weighted k-Nearest Neighbors Regression Using C#
KNNR works well with small datasets and gives highly interpretable results but tends to be less accurate than more sophisticated techniques and works only with strictly numeric data.
The goal of a machine learning regression problem is to predict a single numeric value. For example, you might want to predict the price of a particular make and model of a used car based on its mileage, year of manufacture, number of doors and so on.
There are roughly a dozen major regression techniques, and each technique has several variations. The most common techniques include linear regression, linear ridge regression, k-nearest neighbors regression, kernel ridge regression, Gaussian process regression, decision tree regression and neural network regression. Each technique has pros and cons. This article explains how to implement k-nearest neighbors regression (KNNR) from scratch, using the C# language. Compared to other regression techniques, KNNR works well with small datasets, and the results are highly interpretable. However, KNNR tends to be less accurate than more sophisticated techniques, and works only with strictly numeric data.
A good way to see where this article is headed is to take a look at the screenshot of a demo program in Figure 1. The demo program uses synthetic data that was generated by a 5-10-1 neural network with random weights. There are five predictor variables which have values between -1.0 and +1.0, and a target variable to predict, which is a value between 0.0 and 1.0. There are 200 training items and 40 test items.
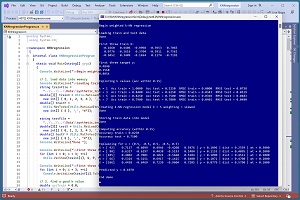 [Click on image for larger view.] Figure 1: Weighted k-Nearest Neighbors Regression in Action
[Click on image for larger view.] Figure 1: Weighted k-Nearest Neighbors Regression in Action
The demo program loads the training and test data from two text files into memory. Next, the demo investigates four different values of k, which is the number of nearest neighbors to use when creating a KNNR prediction model. The value k = 5 gave a balanced combination of classification accuracy and root mean squared error (RMSE).
The demo creates a weighted KNNR prediction model using the 200 training data items with k = 5. The model scores 0.8250 accuracy on the training data (165 out of 200 correct) and 0.7500 accuracy on the test data (30 out of 40 correct). A correct prediction is defined to be one that is within 0.15 of the true target value.
The demo concludes by predicting the y value for a dummy input of x = (0.5, -0.5, 0.5, -0.5, 0.5). The predicted y is 0.1070. The demo shows exactly how the prediction was calculated. The five closest training items to the unknown x are items [92], [80], [105], [66], [106]. Their corresponding true target y values are (0.2559, 0.4095, 0.4511, 0.4708, 0.5790). The demo uses skewed weighting where training items that are closer to the x input have larger weights than items that are farther away. The demo weights are (0.30, 0.20, 0.20, 0.20, 0.10).
This article assumes you have intermediate or better programming skill but doesn't assume you know anything about weighted k-nearest neighbors regression. The demo is implemented using C#, but you should be able to refactor the code to a different C-family language if you wish. All normal error checking has been removed to keep the main ideas as clear as possible.
The source code for the demo program is too long to be presented in its entirety in this article. The complete code is available in the accompanying file download. The demo code and data are also available online.
Understanding Weighted k-Nearest Neighbors Regression
Weighted k-nearest neighbors regression is probably best explained by using a concrete example. Suppose that your data has just two predictor variables (rather than five as in the demo) and you set k = 3. And suppose you want to predict the y value for x = (0.70, 0.60).
The KNNR algorithm scans through the training data to find the k = 3 items that are closest to x. Suppose those three items and their associated target y values are:
x1 = (0.70, 0.50) y1 = 0.23
x2 = (0.80, 0.40) y2 = 0.41
x3 = (0.80, 0.90) y3 = 0.18
If you use uniform weighting, each of three weights is 1/3 = 0.3333 and the predicted y is (0.23 * 0.3333) + (0.41 * 0.3333) + (0.18 * 0.3333) = 0.27. If you use skewed weighting with weights = (0.4000, 0.3500, 0.2500), the predicted y is (0.23 * 0.4000) + (0.41 * 0.3500) + (0.18 * 0.2500) = 0.28.
The three main issues when implementing weighted KNNR regression are:
- defining what nearest means
- determining the value of k
- determining the weights
Briefly:
- nearest usually means smallest Euclidean distance
- the value of k must be determined by trial and error based on classification accuracy and root mean squared error
- uniform weighting sometimes works well but skewed weighting is more principled
Euclidean Distance
The Euclidean distance between two vectors is the square root of the sum of the squared differences between corresponding elements. For example, if v1 = (0.80, 0.30) and v2 = (0.60, 0.40), then distance(v1, v2) = sqrt( (0.80 - 0.60)^2 + (0.30 - 0.40)^2 ) = sqrt(0.04 + 0.01) = 0.2236.
The demo program implements a Euclidean distance function as:
static double EucDistance(double[] v1,
double[] v2)
{
int dim = v1.Length;
double sum = 0.0;
for (int j = 0; j < dim; ++j)
sum += (v1[j] - v2[j]) * (v1[j] - v2[j]);
return Math.Sqrt(sum);
}
There are many other distance functions, such as Manhattan distance and Mahalanobis distance. But as far as I know, there are no research results that suggest any of these alternatives are better than Euclidean distance, except in relatively rare, specific scenarios.
When using KNNR you should normalize the predictor variables so that they're all roughly the same magnitude, typically between -1 and +1 or between 0 and 1. If you don't normalize, then when computing Euclidean distance, a variable with large magnitude values (such as a car mileage of 109,000 miles) will overwhelm a variable with small values (such as an engine size of 2.5 liters). Three common techniques are divide-by-constant normalization, min-max normalization and z-score normalization.
Because KNNR is based on distance between numeric vectors, a weakness of KNNR is that it only works with strictly numeric data. If you're new to machine learning, you might think that you could encode non-numeric data and apply a distance function, but, surprisingly, this is not feasible. The main advantages of KNNR are simplicity and interpretability.
Overall Program Structure
I used Visual Studio 2022 (Community Free Edition) for the demo program. I created a new C# console application and checked the "Place solution and project in the same directory" option. I specified .NET version 6.0. I named the project KNNregression. I checked the "Do not use top-level statements" option to avoid the confusing program entry point shortcut syntax.
The demo has no significant .NET dependencies and any relatively recent version of Visual Studio with .NET (Core) or the older .NET Framework will work fine. You can also use the Visual Studio Code program if you like.
After the template code loaded into the editor, I right-clicked on file Program.cs in the Solution Explorer window and renamed the file to the more descriptive KNNregressionProgram.cs. I allowed Visual Studio to automatically rename class Program.
The overall program structure is presented in Listing 1. The Program class houses the Main() method and helper Accuracy() and RootMSE() functions. An alternative design is to place these two functions as member methods in the KNNR class that houses all the k-nearest neighbors regression functionality such as the Predict() and Explain() methods. The Utils class houses all the matrix helper functions such as MatLoad() to load data into a matrix from a text file.
Listing 1: Overall Program Structure
using System;
using System.IO;
namespace KNNregression
{
internal class KNNregressionProgram
{
static void Main(string[] args)
{
Console.WriteLine("Begin weighted k-NN regression ");
// 1. load data into memory
// 2. find a good k value
// 3. create and pseudo-train model
// 4. evaluate model
// 5. use model
Console.WriteLine("End demo ");
Console.ReadLine();
} // Main
static double Accuracy(KNNR model, double[][] dataX,
double[] dataY, double pctClose) { . . }
static double RootMSE(KNNR model, double[][] dataX,
double[] dataY) { . . }
} // Program
public class KNNR
{
public int k;
public double[][]? trainX;
public double[]? trainY;
public string weighting;
public KNNR(int k, string weighting) { . . }
public void Store(double[][] trainX,
double[] trainY) { . . }
public double Predict(double[] x) { . . }
public void Explain(double[] x) { . . }
private static double EucDistance(double[] v1,
double[] v2) { . . }
private static double[] UniformWts(int k) { . . }
private static double[] SkewedWts(int k) { . . }
} // class KNNR
public class Utils
{
public static double[][] MatCreate(int rows,
int cols) { . . }
static int NumNonCommentLines(string fn,
string comment) { . . }
public static double[][] MatLoad(string fn,
int[] usecols, char sep, string comment) { . . }
public static void MatShow(double[][] m,
int dec, int wid) { . . }
public static double[] MatToVec(double[][] m) { . . }
public static void VecShow(double[] vec,
int dec, int wid, bool newLine) { . . }
public static void VecShow(int[] vec, int wid,
bool newLine) { . . }
} // class Utils
} // ns
Although the demo program is long, most of the program is made of short, relatively simple functions. The demo program begins by loading the synthetic training data into memory:
Console.WriteLine("Loading train and test data ");
string trainFile =
"..\\..\\..\\Data\\synthetic_train.txt";
double[][] trainX = Utils.MatLoad(trainFile,
new int[] { 0, 1, 2, 3, 4 }, ',', "#");
double[] trainY =
Utils.MatToVec(Utils.MatLoad(trainFile,
new int[] { 5 }, ',', "#"));
The code assumes the data is located in a subdirectory named Data. The MatLoad() utility function specifies that the data is comma delimited and uses the "#" character to identify lines that are comments. The test data is loaded into memory in the same way:
string testFile =
"..\\..\\..\\Data\\synthetic_test.txt";
double[][] testX = Utils.MatLoad(testFile,
new int[] { 0, 1, 2, 3, 4 }, ',', "#");
double[] testY = Utils.MatToVec(Utils.MatLoad(testFile,
new int[] { 5 }, ',', "#"));
Console.WriteLine("Done ");
Next, the demo displays the first three test predictor values and target values:
Console.WriteLine("First three train X: ");
for (int i = 0; i < 3; ++i)
Utils.VecShow(trainX[i], 4, 9, true);
Console.WriteLine("First three target y: ");
for (int i = 0; i < 3; ++i)
Console.WriteLine(trainY[i].ToString("F4"));
In a non-demo scenario you'd probably want to display all training and test data to make sure it was loaded correctly. Finding a good value for k is the key to getting a good KNNR prediction model. In pseudo-code:
set candidate k values = ( 1, 3, 5, 7, etc. )
for-each k
create and train KNNR model using k
compute accuracy and root mean squared error of model
end-for
It is common, but not required, to use odd values of k. A good value for k is one that balances accuracy with root mean squared error. Accuracy is a crude metric but one that you're ultimately interested in. RMSE is a granular metric but relying on it alone can produce a model that is overfitted (predicts well on training data but poorly on new, previously unseen data).
The demo creates and trains a KNNR model with k = 5 using these statements:
Console.WriteLine("Creating k-NN regression" +
" model k = 5 weighting = skewed ");
KNNR knnr_model = new KNNR(5, "skewed");
Console.WriteLine("Done ");
Console.WriteLine("Storing train data into model ");
knnr_model.Store(trainX, trainY);
Console.WriteLine("Done ");
The "skewed" parameter instructs the model to programmatically compute weights of (0.3, 0.2, 0.2, 0.2, 0.1). If "uniform" had been passed, the weights would have been computed as 1/k = (0.2, 0.2, 0.2, 0.2, 0.2).
Compared to most regression techniques, weighted k-nearest neighbors regression is unusual because making a prediction requires all of the training data. Most regression techniques use training data to compute a prediction equation and then the training data is no longer needed. Therefore, for KNNR, there is no explicit Train() method and a Store() method is used instead. An alternative design is to pass the training and test data to the KNNR constructor and store it during model initialization.
The model is evaluated like so:
Console.WriteLine("Computing accuracy" +
" (within 0.15) ");
accTrain = Accuracy(knnr_model, trainX,
trainY, 0.15);
Console.WriteLine("Accuracy train = " +
accTrain.ToString("F4"));
accTest = Accuracy(knnr_model, testX,
testY, 0.15);
Console.WriteLine("Accuracy test = " +
accTest.ToString("F4"));
Because there is no inherent definition of regression accuracy, it's necessary to implement a custom accuracy function. The demo defines accuracy as a predicted output value that is within a specified percent of the true target data, 15 percent in the case of the demo. A reasonable percentage to use for accuracy will vary from problem to problem, but 0.05, 0.10 and 0.15 are common.
The demo concludes by using the trained model to predict for X = (0.5, -0.5, 0.5, -0.5, 0.5) using these statements:
Console.WriteLine("Explaining for " +
"x = (0.5, -0.5, 0.5, -0.5, 0.5) ");
double[] x =
new double[] { 0.5, -0.5, 0.5, -0.5, 0.5 };
knnr_model.Explain(x);
Console.WriteLine("End demo ");
Console.ReadLine();
The Explain() method computes a predicted y value but also prints messages that show how the prediction is made. In essence Explain() is a verbose Predict() method and so an alternative design is to combine the Predict() and Explain() methods.
The Predict Method
The implementation of the Predict() method begins with:
public double Predict(double[] x)
{
if (this.trainX == null)
Console.WriteLine("Error: Store() not yet called ");
// 0. set up ordering/indices
int n = this.trainX.Length;
int[] indices = new int[n];
for (int i = 0; i < n; ++i)
indices[i] = i;
. . .
The purpose of the indices array will become clear in a moment. Next, the distances from the input vector x to all training data items are computed and then sorted from closest to farthest:
double[] distances = new double[n];
for (int i = 0; i < n; ++i)
distances[i] = EucDistance(x, this.trainX[i]);
Array.Sort(distances, indices);
The C# language Array.Sort() method physically sorts its first argument, the distances, and also sorts in parallel the second argument, the indices of each training item. It would be possible to sort the distances, and the training x data, and the target y data in parallel, but that approach is a lot of unnecessary effort.
The weights are computed by two statements:
double[]? wts = null;
if (this.weighting == "uniform")
wts = UniformWts(this.k);
else if (this.weighting == "skewed")
wts = SkewedWts(this.k);
When called, the Predict() method expects an explicit string of "uniform" or "skewed." Using magic strings is often a bad design choice, but in this case the technique is simpler than using an enumeration in my opinion.
The Predict() method finishes by computing the weighted sum of the k-nearest target y values:
. . .
double result = 0.0;
for (int i = 0; i < this.k; ++i)
result += wts[i] * this.trainY[indices[i]];
return result;
} // Predict
Computing Skewed Weights
The demo program computes skewed weights using a micro-algorithm I devised a few years ago. It's best explained by example. Suppose k = 5, as in the demo. A uniform weight scheme would return 1/5 = 0.20 for each of the five weight values. The demo program gives more weight to the closest training item by multiplying a uniform weight by 1.5, and gives less weight to the farthest item by multiplying by 0.5. So weight[0] = 0.20 * 1.5 = 0.30 and weight[4] = 0.20 * 0.5 = 0.10.
Because the weights must sum to 1.0, this leaves 1 - (0.30 + 0.10) = 0.60 to be shared by the remaining three weights. Therefore weight[1] = weight[2] = weight[3] = 0.60 / 3 = 0.20.
This skewed weighting technique doesn't work for k = 1 or 2 or 3 and so skewed weights are explicitly returned:
if (k == 1) {
result[0] = 1.0;
}
else if (k == 2) {
result[0] = 0.60; result[1] = 0.40;
}
else if (k == 3) {
result[0] = 0.40; result[1] = 0.35; result[2] = 0.25;
}
To be sure, these weight values are arbitrary to some extent, but they have worked well for me in practice and in a series of experiments with synthetic data. A perfectly good alternative design is to use uniform weighting for small values of k and use skewed weighting for k = 4 or larger.
In some machine learning libraries, notably scikit-learn, the weighted k-nearest neighbors regression module allows you to apply a mini-algorithm called inverse distance. Based on my experience, this weighting technique usually works poorly because when a distance is very small, the inverse distance is huge and the resulting weight overwhelms all other weights.
Wrapping Up
Weighted k-nearest neighbors regression is arguably the simplest technique for regression. The main strengths of weighted KNNR are simplicity, interpretability and ability to scale to large (but not huge) datasets. The main weaknesses of KNNR are that it works with only strictly numeric data, and sensitivity to the value of the k parameter.
In practice, weighted KNNR is often less accurate than more sophisticated techniques such as kernel ridge regression and neural network regression. But sometimes weighted KNNR works better than more sophisticated techniques. A common approach is to apply weighted KNNR and one or more other regression techniques to see if they all give consistent results.
Most machine learning libraries have a k-nearest neighbors regression module. But implementing weighted KNNR from scratch allows you to fully customize your code, easily integrate your prediction model with other systems, and gives you a complete understanding of how results are computed.