Microsoft today announced Apache Storm technology for real-time Big Data analytics will be integrated with Microsoft Azure, highlighting several expansions of the company's cloud computing platform.
"We're announcing support of real-time analytics for Apache Hadoop in Azure HDInsight and new machine learning capabilities in the Azure Marketplace," said Microsoft exec T.K. Rengarajan in a blog post. "Our partner and Hadoop vendor Hortonworks also announced how they are integrating with Microsoft Azure with the latest release of the Hortonworks Data Platform." Hortonworks Inc., curator of one of the leading Big Data enterprise software distributions, teamed up with Microsoft to develop the HDInsight Hadoop-based service in the Azure cloud.
Storm is an open source, distributed, fault-tolerant real-time computation system, sometimes described as "real-time Hadoop." In addition to real-time analytics, the incubator project stewarded by the Apache Software Foundation can be used for online machine learning; continuous computation; and distributed remote procedure calls (RPC) and extract, transform and load (ETL) jobs, among other use cases described on the project's Web site.
"The preview availability of Storm in HDInsight continues Microsoft's investment in the Hadoop ecosystem and HDInsight," Rengarajan said. "Recently, we announced support for HBase clusters and the availability of HDInsight as the first global Hadoop Big Data service in China. And together with Hortonworks, we continue to contribute code and engineering hours to many Hadoop projects."
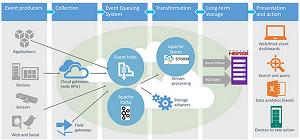 [Click on image for larger view.]Microsoft introduced Apache Storm for real-time analytics for Hadoop.
[Click on image for larger view.]Microsoft introduced Apache Storm for real-time analytics for Hadoop.
(source: Microsoft)
Also available in preview is Microsoft Azure Machine Learning, designed to help customers develop and manage predictive analytics projects. Use case examples for machine learning include search engines, online recommendations for products, credit card fraud prevention systems, traffic directions via GPS and mobile phone personal assistants.
"Today, we are introducing new machine learning capabilities in the Azure Marketplace enabling customers and partners to access machine learning capabilities as Web services," Rengarajan said. "These include a recommendation engine for adding product recommendations to a Web site, an anomaly detection service for predictive maintenance or fraud detection and a set of R packages, a popular programming language used by data scientists. These new capabilities will be available as finished examples for anyone to try."
The Microsoft exec also announced that the Hortonworks Data Platform (HDP) from its partner has achieved Azure certification, noting that the Hadoop vendor will include hybrid data connectors in the next HDP release to enable customers to extend on-premises deployments of Hadoop to Azure for easier backup, scaling and testing.
Posted by David Ramel on 10/15/20140 comments
The Espresso Logic Backend as a Service (BaaS) that can "join" SQL and NoSQL database calls now integrates with Microsoft Azure, the company announced yesterday.
The tool, which lets developers span multiple data sources with one RESTful API call via a point-and-click interface, now works with SQL Server, MongoDB and other services available on the Microsoft cloud.
The Silicon Valley startup last month announced its reactive programming-based universal API for "joining" calls to SQL and MongoDB databases, for example, while also providing the ability to apply business logic, authentication and access control, and validation and event handling to specific data stores.
"Espresso provides the fastest way to create REST APIs that span multiple data sources including SQL, NoSQL and enterprise services," the company said. "Using a unique reactive programming approach, Espresso enables developers to write clear and concise business rules to define logic and specify fine-grain security in a fraction of the time it takes using other approaches."
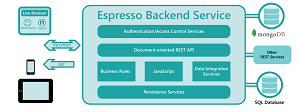 [Click on image for larger view.]
The Espresso Logic Approach(source: Espresso Logic Inc.)
[Click on image for larger view.]
The Espresso Logic Approach(source: Espresso Logic Inc.)
Reactive programming is a declarative approach in which variables are automatically propagated through the system when referenced values are changed, as in a spreadsheet where cells that contain a formula to present a value are automatically updated when values in dependent cells are changed.
"With reactive programming business rules, any rules defined on business objects perform many types of calculations and validations," the company said. Developers can further extend the logic using JavaScript.
The Espresso service previously worked with Azure SQL Database as a cloud-hosted database, but is now available as a service hosted in Azure and integrated with other Microsoft cloud services.
Espresso says its RESTful BaaS integrates with Visual Studio and Microsoft's own back-end, Azure Mobile Services, accelerating the development of mobile and Web apps. It can also work with other Microsoft technologies such as Azure Active Directory identity and authentication, Microsoft Dynamics, Azure Scheduler, Message Bus and API Management tools.
"As many enterprise customers using Microsoft technologies move to using cloud, we hear time and time again that Azure support is high on their list," said company CEO R. Paul Singh in a statement. "With this integration, we want to make it easier and faster for enterprises and integrators developing new mobile and Web applications on Azure -- regardless of their data source."
The Espresso service is available for a free trial, with a paid developer version costing $50 per month and a production version starting at $500 per month.
Posted by David Ramel on 09/18/20140 comments
Windows Phone developers have spoken and Microsoft has listened: Mobile app builders can now respond to reviews of their wares posted in the store.
After a pilot program that started in April, the functionality is being rolled out to "all eligible Windows Phone developers," said Bernardo Zamora in a blog post yesterday, though it wasn't clear what makes a developer eligible.
You can find out if you're eligible from the Dev Center, where you select the dashboard, click on one of your published apps and look at the review screen. If a "Respond" button appears in the lower-right corner, you're eligible.
This capability was by far the most-requested feature posted on the Windows Platform Developer Feedback site, garnering 2,450 votes compared to 1,337 for the second-place item. More than 48 comments were posted to the "Provide ability for developers to respond to user reviews/feedback" item, which was dated April 17, 2011 (ok, so it took them a while to listen). In fact, a related post, "Rate and Review enhancement," received 945 votes, listing "Ability for Devs to contact the reviewer" as the first suggested enhancement.
"We are over 2,000 votes on this," read one comment posted just before the pilot program started. "Clearly it's something that developers want and Google Play has had this for a long time."
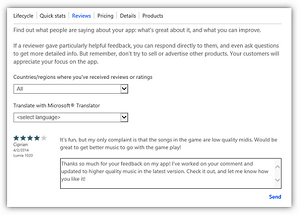 [Click on image for larger view.]
Responding to a review. (source: Microsoft)
[Click on image for larger view.]
Responding to a review. (source: Microsoft)
Zamora wrote yesterday, "The feedback from all developers who have been able to respond to reviews has been very positive so far, with developers using this feature to help users resolve questions, inform them of a new version of the app, and increase user satisfaction with their apps."
He cautioned developers to only use the new feature for those aforementioned purposes, as it "should not be used to spam your users, reengage with previous users, or advertise additional apps or services, as described in the Respond to Reviews guidelines."
Among other things, those guidelines state:
Respond to reviews lets you maintain closer contact with your customers: You can let them know about new features or bugs you've fixed that relate to their reviews, or get more specific feedback on how to improve your app. This feature should not be used for marketing purposes. Note that Microsoft respects customer preferences and won't send review responses to customers who have informed us that they don't want to receive them. Also note that you won't receive the customer's personal contact information as part of this feature; Microsoft will send your response directly to the customer.
This feature is available for reviews sent from:
- Windows Phone 7 and Windows Phone 8 devices with Country/Region set to United States.
- Any Windows Phone 8.1 device.
If developers don't follow the rules, Microsoft said customers can report inappropriate review responses from a developer via the Report Concern link in the Details section of an app's Store description. "Microsoft retains the right to revoke a developer's permission to send responses when developers don't follow the guidelines," Zamora wrote yesterday.
He also announced that developers can use PayPal as a payout method in a bunch more countries, bringing the total number of markets that offer that functionality to 41.
Posted by David Ramel on 08/13/20140 comments
Microsoft yesterday unveiled an updated SQL Server Migration Assistant (SSMA) to ease moving existing Oracle databases to SQL Server 2014.
It's the latest back-and-forth effort between the two companies to help users of competitors' RDBMS products switch to each company's own offering.
The free SSMA tool was announced on the TechNet SQL Server Blog.
"Available now, the SSMA version 6.0 for Oracle databases greatly simplifies the database migration process from Oracle databases to SQL Server," Microsoft said. "SSMA automates all aspects of migration including migration assessment analysis, schema and SQL statement conversion, data migration as well as migration testing to reduce cost and reduce risk of database migration projects."
SQL Server 2014 -- officially released in April -- features a new, much-publicized in-memory OLTP capability, and the new SSMA for Oracle can automatically move Oracle tables into SQL Server 2014 in-memory tables. Microsoft said SSMA can process up to 10,000 Oracle objects in one migration and boasts increased performance and report generation.
The new tool supports migrations of Oracle 9i databases and later to SQL Server 2005 editions and later. It's now available for download.
In addition to the in-memory OLTP capability, SQL Server 2014 features in-memory columnstore to boost query performance and hybrid cloud-related features such as the ability to back up to the cloud directly from SQL Server Management Studio. Microsoft also touted its ability to use the Microsoft Azure cloud as a disaster recovery site using SQL Server 2014 AlwaysOn. SQL Server 2014 is available for evaluation.
Oracle: your turn.
Posted by David Ramel on 07/25/20140 comments
The latest addition to the Microsoft Azure cloud offerings is a new manifestation of the NoSQL database MongoDB service.
The Microsoft Azure Store now offers a fully managed, highly available, MongoDB-as-a-Service add-on.
It runs MongoDB Enterprise edition and comes with support from MongoDB Inc. The company provides replication, monitoring and the MongoDB Management Service, which provides point-in-time recovery of deployments.
Announced at the database vendor's MongoDB World conference, the offering is a team effort with Microsoft, its Microsoft Open Technologies subsidiary and MongoLab, which provides the cloud service version of the popular database.
Microsoft Open Technologies' Brian Benz, blogging from the conference site, said the Database-as-a-Service (DBaaS) offering is the only one available directly from MongoDB Inc. and the only one backed up by MMS.
MongoDB instances have been available in Azure for a while now, but the new service add-on offers new support and development options.
"This is a significant milestone in a multi-year relationship between Microsoft Open Technologies, Microsoft Azure and MongoDB to provide developers with additional choices for a database designed for modern applications," said Microsoft Open Technologies exec Gianugo Rabellino in a statement. "A scalable, resilient and supported MongoDB is now just a few clicks away from our Azure customers, enabling new and exciting scenarios for cloud developers."
Posted by David Ramel on 06/26/20140 comments
Recent research sponsored by Database as a Service (DBaaS) company Tesora shows SQL databases are holding their own in cloud usage.
The start-up, which is developing a DBaaS product for the open source Trove DBaaS project introduced in the April "Icehouse" release of the open source OpenStack cloud platform, today released a report titled ""Database Usage in the Public and Private Cloud: Choices and Preferences." More than 500 developers in North American open source developer communities responded, providing insights into database usage in public and private clouds.
Of those respondents, 79 percent were using a SQL database, while 16 percent were using NoSQL.
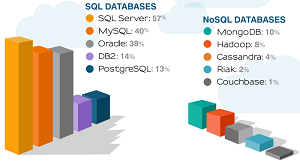 [Click on image for larger view.] Which Databases Does Your Company Currently Use?(source: Tesora)
[Click on image for larger view.] Which Databases Does Your Company Currently Use?(source: Tesora)
"Use of relational databases remains well ahead of NoSQL, whether as a traditional database system or as a service, and whether it is provided in a public or private cloud," Tesora said in a news release announcing the new research.
The research report itself provided more details. "The leaders were the 'Big Three' relational databases: Microsoft SQL Server, MySQL and Oracle," it stated. "MongoDB was the most popular NoSQL DB with slightly more than 10 percent, behind all relational database choices."
So much for SQL becoming obsolete in the new era of Big Data, mobile and cloud computing.
The new findings echo recent similar research, such as a recent "data connectivity" study, and reports of SQL usage in Big Data scenarios.
The whole SQL-vs.-NoSQL thing should have been long over by now, but the new research must be heartening to SQL Server developers whose livelihoods seemed to be threatened by upstart database movements not that long ago.
SQL Server was reported in use by 57 percent of respondents, followed by MySQL (40 percent), Oracle (38 percent), DB2 (14 percent) and PostgresSQL (13 percent). "The results suggest that relational databases still dominate despite rapid adoption of NoSQL solutions by high-profile enterprises like Twitter and Facebook," the survey report said.
Of course, things might change.
"Going forward, this gap can be expected to close since NoSQL databases have only been on the market for a few years or less, as opposed to decades for some of the incumbents," the report stated. "The results seem to indicate the need for coexistence rather than displacement (at least in large, established organizations), with relational databases running in tandem with NoSQL for specialized workloads."
Microsoft didn't fare so well in some other areas. For example, Azure placed third in public cloud usage, at just 8 percent of respondents, behind Amazon AWS (24 percent) and Google Compute Engine (16 percent).
A report caveat noted: "This is a survey of open source software developers, and surveys of other groups will have different results."
Tesora used SurveyMonkey to conduct the survey (available for download after registration), while The Linux Foundation, MongoDB and Percona helped distribute it.
Posted by David Ramel on 06/18/20140 comments
The owner of "the most complete NoSQL database" is targeting the Microsoft .NET Framework for a new open source release. Sound strange? Welcome to the new world of cross-platform interoperability. Developers write their code once and -- with some automatic optimization -- it will run on anything, anywhere, even leveraging native device functionality.
In this case, Couchbase Inc. has partnered with cross-platform kingpin Xamarin to put into beta a native Couchbase Lite for .NET database, "the world's first and only full-featured, flexible, mobile JSON database that runs locally on the device and is built from the ground up for mobile devices."
The two companies will work together to make the new embedded database targeting mobile users generally available this fall. They will also make the code portable, targeting iOS and Android through the Xamarin technology. And, of course, the .NET product will work on phones, tablets and desktops running Microsoft OSes.
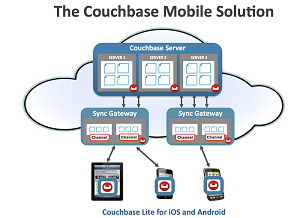 [Click on image for larger view.]
Now available for .NET apps, connected or not
[Click on image for larger view.]
Now available for .NET apps, connected or not
(source: Couchbase Inc.)
Couchbase Lite is now generally available in 1.0.0 releases for iOS, Android and Java, in both enterprise and free community editions. Couchbase also provides plug-in connectors for Xamarin and Adobe PhoneGap, another popular cross-platform development tool that uses HTML 5, CSS and JavaScript. The Xamarin approach differs from PhoneGap -- closely related to the open source project Apache Cordova -- in that developers write C# code that gets targeted for multiple platforms. Preview tooling support for Cordova was recently added to Visual Studio in the 2013 Update 2. Now, .NETdevelopers using Xamarin can more easily integrate the small-footprint database in their apps.
Couchbase is known for its Couchbase Server -- formerly called Membase -- a cloud-based JSON database for which it offers SDKs for programming in Java, Ruby, .NET, C, PHP and Python.
Couchbase Lite is combined with Sync Gateway under the newly available Couchbase Mobile umbrella to offer offline functionality for users on the go. Sync Gateway is used to synchronize data stored in the embedded Couchbase Lite database on a device with Couchbase Server when connectivity is available. Off-grid peer-to-peer support is provided through REST APIs.
"Our goal is to enable developers to build the next generation of mobile applications," said Couchbase exec Rahim Yaseen in a statement. "Xamarin has a community of more than 600,000 developers building native mobile apps for iOS, Android and Windows in C#. Building a native .NET version of Couchbase Lite gives that community a faster, easier way to handle mobile data synchronization, eliminating one of the biggest challenges to building always-available, always-responsive applications."
Coincidentally, a recent Visual Studio Magazine blog post by Keith Ward explored the notion of Microsoft buying Xamarin. That would make things really interesting, judging from the hundreds of social shares and a bunch of reader comments.
Posted by David Ramel on 05/22/20140 comments
MongoDB just won't go away. Two weeks after a major update to the popular NoSQL database, Microsoft announced new high-memory instances were available on its Microsoft Azure cloud platform.
The cloud-served MongoDB instances come from MongoLab, a fully managed database service provider that works with major cloud platforms such as those provided by Amazon and Google. The service has been available on Microsoft Azure since October 2012, but with some limitations.
"We have been working with MongoLab for a long time to bring a fully managed Database as a Service offering for MongoDB to Microsoft Azure," said Microsoft exec Scott Guthrie. "With full production support for all VM types across all datacenters, we are excited and optimistic for the future of MongoDB on our cloud platform."
The details were explained in a blog post yesterday by Brian Benz, who announced "the arrival of our newest high-memory MongoDB database plans, with virtual machine choices that now provide up to 56GB of RAM per node with availability in all eight Microsoft Azure datacenters worldwide."
Along with the new memory capacity, the service provides management tools for backups, performance monitoring of key metrics, analysis to speed up queries and index recommendations. Support is also provided via e-mail or an around-the-clock emergency hotline, depending on the plan.
Developers connect to the service using standard language-specific drivers or through a JSON-based REST API. JSON is the bedrock of MongoDB, which stores data in collections of JSON documents composed of fields with key-value pairs rather than relational tables and columns. This facilitates Big Data analytics, and the database is used by major organizations such as CERN, eBay, Craigslist, SAP and many others. The open source MongoDB database, which was developed by MongoDB Inc., is the most popular NoSQL system in use, according to the latest report from DB-Engines.com, which lists it as No. 5 among all databases.
On Microsoft Azure, MongoDB plans are available ranging from a free "sandbox" that includes 500MB of storage to a 56GB dedicated cluster that costs $5,200 per month.
Benz details how to set up a MongoLab service in a Microsoft Open Technologies blog post.
Are you planning to use MongoDB on Microsoft Azure? Please comment here or drop me a line.
Posted by David Ramel on 04/23/20140 comments
Developers today learned more about the recently released MongoDB version 2.6 when parent company MongoDB Inc. conducted a webinar to explain its new features.
Last week the company announced the "biggest release ever" of its popular NoSQL database, with improvements coming in the areas of aggregation, text-search integration, query engine performance, security and many more.
"With comprehensive core server enhancements, a groundbreaking new automation tool, and critical enterprise features, MongoDB 2.6 is by far our biggest release ever," said Eliot Horowitz, CTO and co-founder.
With standard and enterprise editions, MongoDB is an open source, document-oriented database popular in Big Data implementations. Instead of storing data in tables or columns, the alternative to a traditional relational database management system (RDBMS) uses JSON-like documents with dynamic schemas, what the company calls BSON, short for binary JSON. The company claims MongoDB is the leading NoSQL database, based on metrics such as user searches, job postings and comparison of the skills listed by LinkedIn members, among others.
In today's webinar, company vice president Dan Pasette joined Horowitz to explain the new features of special import to developers. Pasette said most of the 500-plus enhancements to version 2.6 -- which was in development for about a year -- wouldn't be that noticeable to coders, aside from increased performance.
Pasette, who said the MongoDB engineering team numbered about 15 or 20 when he first started at the company but now has more than 100, cited aggregation pipeline enhancement as "one of the most compelling features." It's been around for two versions, he said, but developers can now use it to unlock larger result sets. These had been limited to 16MB, Pasette said, but developers can now get results back with a cursor, which means they can be of unlimited size. Also, he said, developers can use the $out feature to pipe results into a new collection.
Other improvements developers would be interested in, Pasette said, were index aggregation and integrated text search, which is now fully available and directly integrated in queries and pipelines. Also, he said, developers can now use new update operators, such as $multiple and $min.
Horowitz said the company -- originally called 10gen -- used its five years of experience garnered from hundreds of thousands of deployments to create the groundwork for more innovation in the next 10 years.
"You'll see the benefits in better performance and new innovations," Horowitz said. "We rewrote the entire query execution engine to improve scalability, and took our first step in building a sophisticated query planner by introducing index intersection. We've made the codebase easier to maintain, and made it easier to implement new features. Finally, MongoDB 2.6 lays the foundation for massive improvements to concurrency in MongoDB 2.8, including document-level locking."
According to release notes, both editions of MongoDB feature support for variables and new operations that will handle sets and redact data.
Text search is enabled by default in the new release, while the query system now includes a $text operator to resolve text-search queries.
Insert and update improvements include new operations and better consistency of modified data.
A new write operation protocol features improved support for bulk operations and also integrates write operations and write concerns.
Security improvements include better SSL support, x.509 authentication, an enhanced authorization system that features more granular controls, centralized storage of credentials and better tools for user management. The new version also features TLS encryption, along with user-defined roles, auditing functionality and field-level redaction, which Horowitz described as "a critical building block for trusted systems." The database auditing feature is extended by the new capability to integrate with IBM InfoSphere Guardium.
The improved query engine features a new index intersection that will fulfill queries that are supported by more than one index. Also, index filters will limit the indexes that can "become the winning plan for a query." Developers using the database can now use the count method in conjunction with the hint method. You can learn more about that here.
Also counted in the raft of improvements are better geospatial support, index build enhancements, and augmented sharding and replication administration.
Ted Neward, an expert database developer, author and presenter, told me he thought "most of the features introduced in this release are more about Mongo 'growing up' as an enterprise-class database, and it's less developer-centric than previous releases. Consider: a new security model, several administration features, and LDAP support and SNMP functionality. These are the things that a world-class enterprise has come to expect of their data storage systems, and this removes significant blockers for many companies."
Horowitz also emphasized the benefits of the new release to IT operations staffers.
"From the very beginning, MongoDB has offered developers a simple and elegant way to manage their data," Horowitz said. "Now we're bringing that same simplicity and elegance to managing MongoDB. MongoDB Management Service (MMS), which already provides 35,000 MongoDB customers with monitoring and alerting, now provides backup and point-in-time restore functionality, in the cloud and on-premises."
Neward said the emphasis on operations is good "because it signals that MongoDB Inc. is being persuaded/pressured/forced (depending on whose view you take) to put the necessary features in that commercial-scale enterprises need, which in turn signals a growing culture of adoption around non-relational data stores."
Horowitz last week also teased an automation feature for hosted and on-premises options, coming later this year. He said the "game-changing" automation functionality "will allow you to provision and manage MongoDB replica sets and sharded clusters via a simple yet sophisticated interface."
Is the new MongoDB 2.6 now enterprise-ready? Comment here or drop me a line
.
Posted by David Ramel on 04/17/20140 comments
Developers today were still weighing in on a recent Microsoft decision to switch directions on OData support to focus on ASP.NET Web API instead of WCF Data Services, angering many who had invested much work into the latter.
OK, this is somewhat involved, but I think it deserves a close look because it touches on so many issues developers have with Microsoft's support of new products and technologies and changes in direction. In this case, data devs in particular.
In a nutshell, Microsoft last week announced it will shift its OData-related development tool efforts from WCF Data Services to ASP.NET Web API, moving WCF Data Services to open source for further development. That angered many frontline developers whose teams or companies have invested a lot of work in WCF Data Services and now feel abandoned. They now have to consider their options and move forward with a new strategy. Sound familiar?
First, to get everybody on the same page regarding terminology, including those readers who might not be data developers, I'll provide brief descriptions of the terms.
WCF Data Services lets data devs easily build services that use the open OData protocol to expose and consume data over the Web using REST semantics.
REST is an architectural style relying on a stateless, cacheable communications protocol, basically HTTP. Instead of using SQL commands, for example, you can get a list of customers from the sample OData Northwind database service's Customers table by sending the URL: http://services.odata.org/Northwind/Northwind.svc/Customers
OData is an open, standardized protocol for providing and consuming data APIs using HTTP and REST.
ASP.NET Web API is described by Microsoft as an ideal platform for creating RESTful applications on the Microsoft .NET Framework.
OData recently advanced to version 4.0. Microsoft began work on WCF Data Services to support the new features. It ran into two major problems, as explained in the announcement blog by Michael Pizzo,
principal architect, Microsoft OData Team:
First, it required that the underlying data source support fairly rich query semantics. This made it difficult to implement over diverse sources of data such as data returned from a function invocation or collected from other services. Even for queryable sources, computing the best query to perform on the underlying store was often difficult because the query passed to the data provider lacked a lot of the context of the initial request.
Second, because WCF Data Services was somewhat of a monolithic "black box," services had no way to expose new features until supported for each feature was added to the WCF Data Services stack. Adding support to WCF Data Services often in turn required defining new interfaces that each data provider would then have to implement before the functionality was available to the service.
Long story short: Microsoft is putting its OData weight behind ASP.NET Web API as the tool of choice for creating OData services. Using the model-view-controller (MVC) pattern, service developers have much more control over data requests by implementing custom controllers for each route. This will require developers to write more code, Pizzo admitted, but much of that is boilerplate code and developers can get a head start writing it via controller scaffolding.
"We didn't make this decision lightly," Pizzo said, adding that Microsoft has been moving over internal services dependent upon WCF Data Services to ASP.NET Web API. The amount of work required varies, he said, though teams using Entity Framework or who have already implemented custom data handlers find it an easier task.
"So far, though, the migrations have gone well with the teams enjoying the benefits of more control in how requests are processed, and in the features they expose through their service," Pizzo said.
Most of the work to upgrade WCF Data Services to handle features OData 4.0 has already been done, but some of the features still wouldn't be available because of the "monolithic nature" of WCF Data Services.
Thus Microsoft is moving the project to open source so developers can customize it to suit their own needs. Pizzo asked developers if Microsoft should invest more work in the product to make it more OData version 4.0-compliant before moving it to open source or just do it immediately and let the open source community finish the upgrade work.
Developers weighed in, and many weren't happy:
- I don't think it really matters when you release the source code. No one is going to care when the owner has stated it's dead. It's a shame I had put a lot of time and investment into WCF Data Services.
- This is very sad news indeed.
- Very disappointing.
- Not telling us until so recently is lame, epic lame.
- I have no faith in the Web API team prioritizing this issue very high and I fear we end up waiting a long time on the Web API team to catch up -- history shows this to be correct.
- I know MS wants people to adopt OData and now the people that have are being screwed over. Really not happy with this decision or the thought process that went into it.
Several commenters said Microsoft was erring by focusing on consumer development instead of enterprise development and eroding the trust of front-line coders in the latter camp.
"They need something that can hook to Twitter, Facebook and other Web sources," one commenter said. "In the end, WCF Data Services is just another casualty in Microsoft's pursuit of part of the pie that Google and Apple are getting most of right now."
Others, however, were supportive, and offered their opinions on which way Microsoft should go in open sourcing WCF Data Services, which was the point of Pizzo's blog post.
Pizzo addressed some of the questions and concerns in his own comment on the blog post.
And in response to a query from me, the team provided this:
First, it's important to note that WCF Data Services as it stands today will continue to be supported, including continued support for existing OData 3.0 in WCF Data Services.
We are currently planning to release OData V4 compatibility in WCF Data Services through Open Source, enabling the community to drive the feature set as appropriate.
At the same time, we will be taking the feedback provided to make Web API OData easier to use for scenarios where developers might prefer WCF Data Services today, as well as to make it easier for developers who have invested in WCF Data Services and chose to migrate in order to get the benefits of Web API + OData to do so.
Besides comments in blog posts, much of the feedback provided by developers comes in suggestions on the UserVoice site that Microsoft uses to gather feedback, features suggestions and so on.
A recent entry to the User Voice site is titled "Don't abandon WCF Data Services" and implored the OData team to reconsider the plan outlined in Pizzo's blog post. It had 52 votes today.
Pizzo responded and said the team would consider his feedback "as we prioritize work between enhancing WCF Data Services and providing better support for new features in the WebAPI OData libraries."
I asked the poster of that UserVoice item, Adam Caviness, a senior developer, to expound further. This is what he wrote me:
We were not expecting this news. Based on UserVoice tickets and team blog posts we believed that Microsoft was investing in WCF Data Services alongside of Web API.
In fact, the UserVoice page and Blog were actually named with the WCF Data Services moniker. Microsoft has a tendency to provide multiple offerings of a similar story to their own detriment--just consider why we have the Blend designer in Visual Studio. This is another case where multiple offerings is not a commitment but rather an experiment. Wait, am I a lab rat?
After getting further
feedback from the OData Team, we discovered they had been working with internal teams to migrate for some time while we were left in the dark. The OData team also stated twice in posts that "part of our charter is to help Microsoft align behind the OData protocol." I can only gather that Microsoft is making a good technical decision to switch to OData internally, but what meets our needs is more or less a coincidence.
This is a decision they should have contacted the community over and it shouldn't have been mentioned in such a nonchalant [way] in a blog post. WCF Data Services is still listed on MSDN as a viable N-Tier OData strategy so I suppose new unsuspecting developers are even unaware of this direction.
We are investigating the impact of moving to Web API and OWIN. The strategy to reorient Microsoft to a more consumer-centric company is eroding away our confidence in building long-term dependable solutions for this platform.
Me? I can see both sides of this thing. On one hand, you see some of the behavior that leads to such prevalent animosity toward Microsoft on the part of developers who invest in a technology for long-term, line-of-business applications and then see the company going in another direction.
On the other hand, the new direction seems to provide developers with more control and opportunity for customization and might benefit them in the long run. And Microsoft team members are noting the feedback and are answering questions from developers and journalists like me, even though they were quite preoccupied with the just-started Build conference.
Still, I can't help feeling that if I were an enterprise developer as described above, I might hearken back to the immortal words of Johnny Rotten at the end of the Sex Pistols' last concert before the punk band imploded: "Ever get the feeling you've been cheated? Good night!"
What direction do you think Microsoft should go in sending WCF Data Services to open source for OData 4.0 support? Please comment here or drop me a line.
Posted by David Ramel on 04/02/20140 comments
Microsoft last week released a minor version update of its popular Object Relational Mapping (ORM) tool with numerous bug fixes and new features, including the ability to reverse engineer an existing database to create a Code First model.
Entity Framework (EF) 6.1 is the first ".x" update since Microsoft open sourced the tool moving to version 6 and moved it to CodePlex. It features tooling consolidation that "extends the ADO.NET Entity Data Model wizard to support creating Code First models, including reverse engineering from an existing database," Microsoft's Rowan Miller explained in an ADO.NET Blog post.
Miller said this new functionality was available in beta quality in the EF Power Tools package, used by the engineering team to preview features under consideration for inclusion in a main release.
Developers can now right-click on a C# project to get a context menu item to "Reverse Engineer Code First," according to Data Developer Center documentation for the EF Power Tools. This command generates a derived DbContext class, "plain-old CLR object" (POCO) classes and Code First mapping classes from an existing database.
Another context menu item is available to "Customize Reverse Engineer Templates," which lets developers customize code generation via reverse engineer T4 templates added to projects.
According to project meeting notes that Microsoft developers now put online, the Code First models that can now be created with the wizard will lack certain features, such as the ability to split tables and entities, and support for complex types and enums, among others.
Microsoft has posted a
Code First to an Existing Database video and walk-through where you can learn more about this new feature.
EF6.1 also includes a new IndexAttribute functionality that lets developers specifically identify database table indexes with an [Index] attribute attached to properties in Code First models.
Other enhancements to Entity Framework in version 6.1 listed by Miller include a CommitFailureHandler, public mapping API, performance improvements and many others.
Microsoft engineers such as Diego Vega and Pawel Kadluczka have been busy this week helping developers who reported problems with the new version update in the comments section of Miller's blog.
For more support, Microsoft recommends developers post questions on the StackOverflow site, where six questions had been posted as of today.
For future releases, the EF team's roadmap indicates it's considering "EF Everywhere," described as "a lighter-weight version of EF that can be used across a wide variety of platforms (including Windows Store and Windows Phone)."
Posted by David Ramel on 03/25/20140 comments
I like tinkering around with OData. And since a certain industry giant has been pushing open JavaScript development over its own vastly superior technologies, I've been trying to wrap my mind around that language using my old friend OData. The jQuery getJSON function helps working with OData, but it's still JavaScript.
(Don't get me started on JavaScript. Actually, I am started, so send me your reasons for hating the language and I'll put them in a future "10 Reasons to Hate JavaScript" post. Should be easy enough.)
Anyway, back to the point: OData is marching smartly forward, with version 4.0 having this week been approved by the OASIS international standards consortium. It has come a long way since being introduced by industry giant Microsoft in May 2011.
Specifically, OData 4.0 and OData 4.0 JSON Format have been approved as standards, with OData 4.0 ATOM being advanced and headed for official sanction.
"OData provides a way to break down data silos and increase the shared value of data by creating an ecosystem in which data consumers can interoperate with data producers in powerful ways, enabling more applications to make sense of a broader set of data," explained OASIS in its announcement.
To me, that reads: "OData is an easy way to access all kinds of interesting public and private data feeds and present the information in cool visualizations and such." You can get lost for hours just exploring the astounding amount of data generated by the federal government, such as, "Job Openings and Labor Turnover Survey," for an example that just happened to catch my eye.
All kinds of goodies are packed into v4.0, like Entity Data Model improvements, better support for distributed services, dynamic schema and an asynchronous pattern for long-running data requests, to name just a few.
Microsoft earlier this month got a jump on v4.0 support, with core .NET libraries, an OData client and a pre-release WebAPI library.
"This is an incredibly exciting time for Open Data, as products and libraries are quickly rev'ing to support OData v4.0," said Microsoft's Michael Pizzo in his announcement that listed all of the goodness I mentioned here and more. "Support for building OData V4.0-compliant clients and servers in Java, as well as consuming OData V4.0 from JavaScript clients, is already underway in the open source Apache Olingo incubator project."
Yi Ding yesterday provided some status updates on the libraries that support v4.0. Ding noted that Java libraries will be part of the Olingo project, due to be completed in the second quarter of this year. A core JavaScript library, Data.js, will also be part of that project. And work is being done to accommodate C++ developers, with a preview client library expected to be available this month. Stay tuned.
Forget this OData stuff. Tell me why you hate JavaScript. Comment here or drop me a line.
Posted by David Ramel on 03/21/20140 comments