Code Focused
Regular Expressions, Part 2: Positioning and More
Like riding a bike, knowledge of regular expressions will stay with you forever, allowing you to manipulate text quickly and easily. In this part of the series, Ondrej focuses in on groups, positioning and tools.
- By Ondrej Balas
- 02/05/2014
In my last column, I left off with an explanation of how groups can be used to divide a pattern into smaller pieces, or sub-expressions, allowing for repeating subsets of the pattern. But groups have other benefits as well, such as extracting information from a string. Take the following code, for example:
Dim input As String = "555-123-4567"
Dim pattern As String = "(\d\d\d)-\d\d\d-\d\d\d\d"
Dim match As Match = Regex.Match(input, pattern)
Dim areaCode As String = match.Groups(1).Value
In this code, there's a set of parentheses around what would be the area code portion of the pattern, forming a capturing group. When the Regex engine returns the Match object, it puts all those groups into a Groups property on that Match object. You can then use the indexer on the property to get the group you want to access. Notice that I used an index of 1 to get the area code group. While the Groups property is zero-based, the first group (Groups(0)) is always a match of the entire regular expression. Then, each left parenthesis in the pattern gets a subsequent number; the first one will be in Groups(1), the second in Groups(2) and so on.
Using numeric indexers like this is fine when working with simple patterns, but complexity increases quickly as the Regex grows in size. It can also be problematic when changing the expression, as the groups may end up with different numbers as the pattern is changed. To solve this problem, you can optionally name the groups in the pattern, and then retrieve them by name rather than by number. Named groups have a special syntax, as shown here:
Dim input As String = "555-123-4567"
Dim pattern As String = "(?<AreaCode>\d\d\d)-\d\d\d-\d\d\d\d"
Dim match As Match = Regex.Match(input, pattern)
Dim areaCode = match.Groups("AreaCode").Value
The group that was (\d\d\d) is now (?<AreaCode>\d\d\d). In this case, the question mark directly after the left parenthesis tells the Regex engine that the group should follow special rules. Because it's followed by a name within angle brackets, it knows to treat it as a named group. Now the group can be referenced by the name "AreaCode" instead of number (though it can still be accessed by number as well).
You may have noticed that I've been using the Value property of the Group object to get the matched text. The Group object also has a few other helpful properties, as listed in Table 1.
Table 1: The Properties of the Group Object
| Property |
Description |
| Captures |
A collection containing sub-captures within the group |
| Index |
The position at which this group matches within the input string |
| Length |
The length of the captured string |
| Success |
A Boolean that specifies whether the group matched or not. |
| Value |
The matching text |
|
Property Description
Captures A collection containing sub-captures within the group
Index The position at which this group matches within the input string
Length The length of the captured string
Success A Boolean that specifies whether the group matched or not.
Value The matching text
Position
Up to this point I've glossed over positioning and the difference between matching a character and matching the position between two characters (also known as an anchor). The two most commonly used position characters are the caret (^), which matches the position before the first character in the string, and the dollar sign ($), which matches the position at the very end of the string. Again, revisiting the phone number example, a pattern of \d\d\d-\d\d\d\d will match if a phone number appears anywhere within the match string. Even the string "abc123-4567def" would successfully be matched by that pattern. A better pattern would be "^\d\d\d-\d\d\d\d$," which reads as: "The position before the first character, immediately followed by three digits, then a hyphen, then four more digits, and then immediately followed by the position after the last character." The following code snippet demonstrates this:
Dim invalidInput As String = "abc123-4567def"
Dim validInput As String = "123-4567"
Dim pattern As String = "^\d\d\d-\d\d\d\d$"
Dim invalidMatchResult As Boolean = Regex.Match(invalidInput, pattern).Success 'False
Dim validMatchResult As Boolean = Regex.Match(validInput, pattern).Success 'True
Another positional character is \b, or word boundary. Word boundary (\b) matches successfully for a position between a word character and non-word character, where a word character is defined as any alphanumeric character or underscore. An example of this would be a search for how often the word "bot" appears within a log file. With a pattern of "bot," words such as "robot" would match as well, leading to an inaccurate word count. A pattern that would avoid this would be "\bbot\b," which reads as: "A word boundary, immediately followed by the word bot, immediately followed by another word boundary." Here's a usage example:
Dim input = "search bot | robots.txt"
Dim simplePattern = "bot"
Dim betterPattern = "\bbot\b"
Dim simpleCount As Integer = Regex.Matches(input, simplePattern).Count '2
Dim betterCount As Integer = Regex.Matches(input, betterPattern).Count '1
Using the simple pattern, the engine returns a count of 2 instances of the word "bot," when one instance is just its occurrence within the word "robots." By requiring word boundaries before and after the word "bot," the engine returns the correct count of 1.
Greedy or Lazy
In my last column, I showed off many of the quantifiers that Regex offers, such as the asterisk (*). To get the most out of quantifiers, it's important to understand the distinction between greedy and lazy behaviors. By default, quantifiers behave in a "greedy" fashion, meaning they consume as many characters as possible. It's possible to individually change that behavior to "lazy" by following them with a question mark. Consider this example:
Dim input As String = "http://www.example.com/samples/demo.html"
Dim greedyPattern As String = "http://(.*)/"
Dim lazyPattern As String = "http://(.*?)/"
Dim greedyMatch As String = Regex.Match(input, greedyPattern).Value 'http://www.example.com/samples/
Dim lazyMatch As String = Regex.Match(input, lazyPattern).Value 'http://www.example.com/
The patterns are almost identical, with the difference being that the greedy pattern uses a group of (.*) while the lazy pattern uses (.*?). The results are quite different, however. When using the greedy pattern, the resulting match was "http://www.example.com/samples/," but with the lazy pattern it was "http://www.example.com/." The difference is in the way the Regex engine steps through the input string to find a match.
When parsing the greedy expression, it matches the http:// and starts stepping through the input, matching as many periods (any character) as it can. It will do this until it reaches the end of the string, and then attempt to match the slash. Because there's no slash after the end of the string, the engine will start back-tracking until it finds a slash. See Figure 1 for a simplified example of how this might be parsed by the Regex engine.
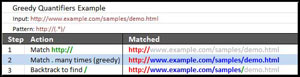 [Click on image for larger view.]
Figure 1. Simplified example of behavior when matching the greedy expression.
[Click on image for larger view.]
Figure 1. Simplified example of behavior when matching the greedy expression.
The engine deals with the lazy expression much differently. Instead of matching as much as it can, it matches as little as it can get away with while still matching the slash (/) following the quantifier. Figure 2 shows a simplified example of this behavior.
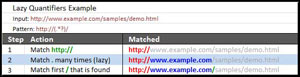 [Click on image for larger view.]
Figure 2. Simplified example of behavior when matching the lazy expression.
[Click on image for larger view.]
Figure 2. Simplified example of behavior when matching the lazy expression.
Tools
Regular expressions can be difficult both to write and to read; fortunately, there are some great tools that can help. To jump-start your understanding of more complex expressions, I recommend a free tool called Expresso.
If you're interested in a deeper understanding of how the engine handles your expressions, or just want to debug a complex expression, try out RegExpose, an open source tool written by Brian Friesen and available on GitHub.
Advanced Scenarios
In the next part of this series, I'll be exploring some advanced scenarios for regular expressions, such as using them as part of the Find & Replace feature in Visual Studio, or in applying them to business intelligence. I hope you find as much value in regular expressions as I continue to, year after year.
About the Author
Ondrej Balas owns UseTech Design, a Michigan development company focused on .NET and Microsoft technologies. Ondrej is a Microsoft MVP in Visual Studio and Development Technologies and an active contributor to the Michigan software development community. He works across many industries -- finance, healthcare, manufacturing, and logistics -- and has expertise with large data sets, algorithm design, distributed architecture, and software development practices.