In-Depth
LINQ Query Enters the Age of Big Data
Integrating distributed, in-memory computing with distributed caching can easily extend LINQ semantics to create important new capabilities for real-time analytics on fast-changing data.
- By William L. Bain
- 08/08/2016
In the age of big data, web applications increasingly need to track huge volumes of fast-changing data. Distributed caching helps these applications capture and manage this data with low latency, but it provides only rudimentary APIs for querying and analyzing data in real time. In this article we will show how integrating distributed, in-memory computing with distributed caching can easily extend LINQ semantics to create important new capabilities for real-time analytics on fast-changing data.
Scaling In-Memory Data Storage
Whether it's e-commerce shopping carts, real-time IoT telemetry, or live ticker prices, today's web applications need to track huge volumes of fast-changing data. Because this data needs to be accessible with sub-millisecond latency, it typically is held in DRAM instead of on disk.
However, the amount of data that must be tracked by these applications easily can exceed a terabyte and outstrip the capacity of a single server's primary memory. To address this challenge, in-memory data grid (IMDG) middleware, also known as distributed caching, distributes a shared, in-memory data store across a cluster of servers. IMDGs transparently scale memory capacity and throughput while keeping access times low. They also incorporate techniques for maintaining high availability if a server fails.
To enable seamless incorporation into object-oriented applications that implement business logic, IMDGs usually provide APIs which create, access, update, and delete serialized objects organized as collections of a given type within a key/value store. For example, consider a customer's shopping cart object, shown in Listing 1.
Listing 1. ShoppingCartItem Class
class ShoppingCartItem
{
public string Name { get; set; }
public decimal Price { get; set; }
public int Quantity { get; set; }
}
class ShoppingCart
{
public string CustomerId { get; set; }
public IList<ShoppingCartItem> Items { get; } = new List<ShoppingCartItem>();
public decimal TotalValue
{
get { return Items.Sum((item) => item.Quantity * item.Price); }
}
public decimal ItemCount
{
get { return Items.Sum((item) => item.Quantity); }
}
}
var myCart = new ShoppingCart() { CustomerId = "cust17023" };
myCart.Items.Add(new ShoppingCartItem()
{
Name = "Acme Widget",
Price = 199.99m,
Quantity = 2
});
myCart.Items.Add(new ShoppingCartItem()
{
Name = "Acme Snow Globe",
Price = 2.99m,
Quantity = 400
});
This shopping cart can be stored in an IMDG with a simple API that names the collection of shopping cart objects ("carts") and then creates an instance using the customer's identifier as the key for accessing the object within the IMDG:
var carts = CacheFactory.GetCache("carts");
carts.Add(myCart.CustomerId, myCart); // CustomerId serves as key
Using Distributed Query for Data Analytics
Accessing objects individually by key enables IMDGs to maintain consistently fast access times (sub-millisecond for small objects) with constant-time overhead; this handles most use cases. However, it is often important to query groups of related objects for data analytics. IMDGs usually allow stored objects within a typed collection to be queried by their class properties. The result of the query is the set of objects which match a query specification.
Some IMDG APIs implement .NET's IQueryProvider interface so that queries to the IMDG conveniently can be expressed as LINQ expressions. For example, consider an e-commerce site manager who wants to examine a site's shopping carts to analyze the mix of products for shopping carts larger than $100. This could be expressed as a LINQ query to the IMDG:
var carts = CacheFactory.GetCache("carts");
var q = from c in carts.QueryObjects<ShoppingCart>()
where c.TotalValue >= 100.00m
select c;
// Query execution is deferred until we iterate:
foreach (var cart in q)
{
// analyze contents...
}
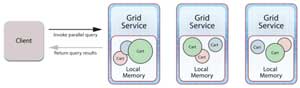
To implement this query, the IMDG's client library builds an expression tree and ships it to all servers within the cluster, and the IMDG runs the query in parallel to find matching objects stored on the servers. This returns a set of result objects to the requesting application for analysis. By integrating object-oriented query with the IMDG's object-oriented data storage, applications can extend basic key/value access with a powerful mechanism for accessing groups of logically related objects. Because of their transparent, data-parallel processing, IMDGs scale query performance simply by adding servers as the size of the workload grows (see Figure 1).
 [Click on image for larger view.]
Figure 1: In-memory data grid middleware can scale query performance by addings servers as workloads grow. Here's an example with a 3-server cluster of grid servers.
[Click on image for larger view.]
Figure 1: In-memory data grid middleware can scale query performance by addings servers as workloads grow. Here's an example with a 3-server cluster of grid servers.
Querying an in-memory data grid is appropriate for examining large sets of objects but not for simply reading objects from the grid. Because it examines objects on all servers for a match to the query specification, it incurs significantly more CPU and network overhead than is needed to access individual objects.
Large Datasets Create Query Bottlenecks
While IMDGs can hold large datasets and quickly query them in parallel, this can create two significant bottlenecks for the requesting client. First, queries can return a large set of result objects which have to be returned to the client, and this can saturate the network. Also, the client has to analyze a potentially large result set within a single server, which may require significant processing and create a CPU bottleneck.
For example, suppose an e-commerce site manager is querying all shopping carts worth $100 or more in order to determine which customers have selected a combination of products that makes them eligible for a special offer. This processing could be performed within the client as follows, assuming that we have a Boolean method called Eligible() which examines a shopping cart to determine eligibility for an offer defined by an instance of ShoppingOffer (see Listing 2).
Listing 2. ShoppingOffer Class Determines Offer Eligibility
class ShoppingOffer
{
public decimal RequiredCartValue { get; set; }
public int RequiredCartItemCount { get; set; }
}
var offer = new ShoppingOffer()
{
RequiredCartValue = 500.00m,
RequiredCartItemCount = 5
};
static bool Eligible(ShoppingCart cart, ShoppingOffer offer)
{
if (cart.TotalValue >= offer.RequiredCartValue &&
cart.ItemCount >= offer.RequiredCartItemCount)
return true;
else
return false;
}
var q = from c in carts.QueryObjects<ShoppingCart>()
where c.TotalValue >= 100.00m
select c;
foreach (var cart in q)
if (Eligible(cart, offer))
Console.WriteLine(cart.CustomerId);
As the size of the result set returned from querying the IMDG grows in size, so does the network delay and processing time required to analyze the results.
For example, returning 100K shopping carts of size 1KB to the client from a query would require moving 1MB across the network and then examining 100K objects in the client. The promise of big data analytics cannot be met if it introduces bottlenecks, which kill performance.
Moving Computation to Where Data Lives
In the above example, the ultimate result of the analysis was a subset of the shopping carts returned by the LINQ query selected by the Eligible() method. If instead, the Eligible() method is run within the IMDG, the size of the results returned to the client is likely to be reduced, and the CPU overhead required to run this method within the client is eliminated. For example, if only 10 percent of the shopping carts are eligible for an offer, the amount of data returned to the client is reduced by 10 times. Moreover, the IMDG can run this method in parallel across all servers within the cluster to scale performance for large datasets and reduce analysis time.
This technique for moving query analysis into the IMDG can be expressed as a simple extension method called InvokeFilter that further refines a LINQ query by incorporating the client's method as a Boolean "filter method" with the shopping offer passed in as a parameter:
var q = (from c in carts.QueryObjects<ShoppingCart>()
where c.TotalValue >= 100.00m
select c)
.InvokeFilter(
timeout: TimeSpan.Zero,
param: offer,
predicate: Eligible);
foreach (var cart in q)
Console.WriteLine(cart.CustomerId);
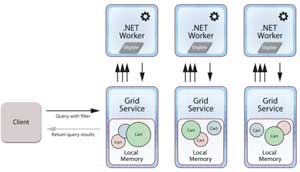
Now the query returns only those shopping carts corresponding to customers who are eligible for the special offer. Of course, to implement this extension, the IMDG has to be able to stage the client's code on the grid servers and execute this code during the execution of the query. This is typically accomplished by staging and running the client's code within a .NET worker process paired with the IMDG's grid service process on each server within the grid (see Figure 2).
 [Click on image for larger view.]
Figure 2: In this three-server cluster, client's code is staged and run within a .NET worker process that's paired with the IMDG's grid service process on each server within the grid.
[Click on image for larger view.]
Figure 2: In this three-server cluster, client's code is staged and run within a .NET worker process that's paired with the IMDG's grid service process on each server within the grid.
There are numerous details that need to be considered, such as how to securely ship and host client code, which are beyond the scope of this article but well within the capabilities of modern IMDGs.
With this extension, an IMDG provides its clients with more than a fast, scalable, in-memory data store. It evolves into a big data execution platform that can be accessed using familiar query techniques. Now clients can extend their queries with domain-specific algorithms that analyze objects held within the IMDG and return highly filtered results. For example, an IoT system can use an IMDG to store telemetry for a large set of remote sensors and periodically query the IMDG's objects using a complex algorithm that analyzes the telemetry for those sensors which require immediate attention.
The Next Step: Data-Parallel Processing
The obvious limitation of extending query using Boolean filter methods is that the query still must incur the overhead of returning objects stored within the IMDG. It would be more efficient to generalize the client's method so that it returns the result of an analysis, which could be merged with other results to return a final report to the client. In the above shopping cart example, the Eligible() method might return the expected monetary value of an offer to the selected customer instead of just a Boolean that selects the shopping cart.
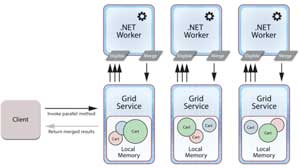
Then the expected values for all selected carts could be merged in parallel (to compute the sum and average, for example) using a second, client-specified method called Merge(), with the final result returned to the client. Now the IMDG can perform a full data-parallel computation on behalf of the client (see Figure 3).
 [Click on image for larger view.]
Figure 3: With the Merge method, the IMDG can perform a full data-parallel computation on behalf of the client.
[Click on image for larger view.]
Figure 3: With the Merge method, the IMDG can perform a full data-parallel computation on behalf of the client.
If the ultimate goal of querying the eligible shopping carts was simply to run this analysis, using the IMDG for data-parallel computation eliminates the need to ship shopping carts to the client. Beyond just lowering network overhead, the IMDG also offloads the computation from the client and scales performance to maintain fast execution time.
Summing Up
Although many business applications may not be ready yet to implement data-parallel computations, adding filter methods to LINQ queries provides a highly useful technique for extending the capabilities of .NET applications to harness the scalable data storage and processing power of IMDGs. By running user-defined methods for selecting objects of interest from the client within the grid, query times get faster, and network overhead drops significantly. This offers a powerful step-up from distributed caching by enabling web and other applications to identify important patterns, analyze fast-changing data, and quickly extract highly relevant query results. It also eliminates performance bottlenecks by dramatically reducing data motion to and from the grid's clients.
Over the last decade, IMDGs have proven their worth as distributed caches, and they are now increasingly being used as highly scalable platforms for in-memory computing. Adding filter methods to distributed queries takes an important first step in reaching that goal. As IMDGs begin to take on more computational tasks using straightforward techniques pioneered by big data, additional performance gains can be expected. This ensures that live applications can handle fast growing workloads with responsiveness and scalable performance.
Note: A runnable Visual Studio 2015 solution for the code samples is available in the Code Download link provided at the top of this article. The solution makes use of APIs in ScaleOut StateServer, which can be downloaded here.
About the Author
Dr. William Bain is founder and CEO of ScaleOut Software Inc., and holds a Ph.D. in electrical engineering from Rice University. Dr. Bain has contributed to advancements in parallel computing at Bell Labs research, Intel and Microsoft, and holds several patents in computer architecture and distributed computing. His previous company, Valence Research, developed and distributed Web load-balancing software, and was acquired by Microsoft. Dr. Bain is actively involved in entrepreneurship and the angel community at Seattle-based Alliance of Angels.