The Data Science Lab
How to Compute Transformer Architecture Model Accuracy
Dr. James McCaffrey of Microsoft Research uses the Hugging Face library to simplify the implementation of NLP systems using Transformer Architecture (TA) models.
This article explains how to compute the accuracy of a trained Transformer Architecture model for natural language processing. Specifically, this article describes how to compute the classification accuracy of a condensed BERT model that predicts the sentiment (positive or negative) of movie reviews taken from the IMDB movie review dataset.
Transformer Architecture (TA) models have revolutionized natural language processing (NLP) but TA systems are extremely complex and implementing them from scratch can take hundreds or even thousands of man-hours. Hugging Face (HF) is an open source code library that provides pretrained models and an API set to work with the models. The HF library makes implementing NLP systems using TA models much less difficult.
You can think of a pretrained TA model as sort of an English language expert that knows about things such as sentence structure and synonyms. But the TA expert doesn't know anything about movies and so you provide additional training to fine-tune the model so that it understands the difference between a positive movie review and a negative review. I explained how to fine-tune and save a binary classification model in a previous article.
A good way to see where this article is headed is to take a look at the screenshot of a demo program in Figure 1. The demo program begins by loading a DistilBERT ("distilled" bidirectional encoder representations from transformers) model into memory. Next, the demo loads the model with the trained weights and biases that have been previously saved to file. The demo then loads test movie review data which has the same structure as the movie reviews that were used to train the model.
The test reviews are tokenized: converted from text ("I liked this movie") into integer IDs. The tokenized reviews are loaded into a PyTorch Dataset object so that they can be fed to the trained model. The demo processes the first five test reviews, one at a time. Test review [2] is incorrectly predicted as class 0 (negative) when in fact it is class 1 (positive) and so the demo displays the token IDs and the source review text (truncated to save space) for diagnosis.
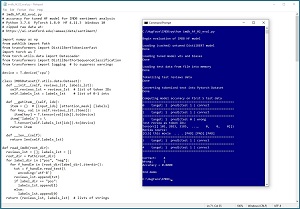 [Click on image for larger view.] Figure 1: Computing Model Accuracy for a Condensed BERT Model for Movie Sentiment Analysis
[Click on image for larger view.] Figure 1: Computing Model Accuracy for a Condensed BERT Model for Movie Sentiment Analysis
This article assumes you have advanced familiarity with a C-family programming language, preferably Python, and basic familiarity with PyTorch, but does not assume you know anything about the Hugging Face code library. The complete source code for the demo program is presented in this article, and the code is also available in the accompanying file download.
To run the demo program, you must have Python, PyTorch, and HF installed on your machine. The demo programs were developed on Windows 10 using the Anaconda 2020.02 64-bit distribution (which contains Python 3.7.6), PyTorch version 1.8.0 for CPU installed via pip, and HF transformers version 4.11.3. Installation of PyTorch is not trivial. You can find detailed step-by-step installation instructions in my blog post. Installing the HF transformers library is relatively simple. You can issue the shell command "pip install transformers."
The Demo Program
The complete demo code, with a few minor edits to save space, is presented in Listing 1. I prefer to indent using two spaces rather than the standard four spaces. The backslash character is used for line continuation to break down long statements.
Listing 1: The Complete Model Accuracy Demo Program
# imdb_hf_02_eval.py
# accuracy for tuned HF model for IMDB sentiment analysis
# Python 3.7.6 PyTorch 1.8.0 HF 4.11.3 Windows 10
# zipped raw data at:
# https://ai.stanford.edu/~amaas/data/sentiment/
import numpy as np
from pathlib import Path
from transformers import DistilBertTokenizerFast
import torch as T
from torch.utils.data import DataLoader
from transformers import DistilBertForSequenceClassification
from transformers import logging # to suppress warnings
device = T.device('cpu')
class IMDbDataset(T.utils.data.Dataset):
def __init__(self, reviews_lst, labels_lst):
self.reviews_lst = reviews_lst # list of token IDs
self.labels_lst = labels_lst # list of 0-1 ints
def __getitem__(self, idx):
item = {} # [input_ids] [attention_mask] [labels]
for key, val in self.reviews_lst.items():
item[key] = T.tensor(val[idx]).to(device)
item['labels'] = \
T.tensor(self.labels_lst[idx]).to(device)
return item
def __len__(self):
return len(self.labels_lst)
def read_imdb(root_dir):
reviews_lst = []; labels_lst = []
root_dir = Path(root_dir)
for label_dir in ["pos", "neg"]:
for f_handle in (root_dir/label_dir).iterdir():
txt = f_handle.read_text(\
encoding='utf-8')
reviews_lst.append(txt)
if label_dir == "pos":
labels_lst.append(1)
else:
labels_lst.append(0)
return (reviews_lst, labels_lst) # lists of strings
def print_list(lst, front, back):
# print first and last items
n = len(lst)
for i in range(front): print(lst[i] + " ", end="")
print(" . . . ", end="")
for i in range(back): print(lst[n-1-i] + " ", end="")
print("")
def accuracy(model, ds, toker, num_reviews):
# item-by-item: good for debugging but slow
n_correct = 0; n_wrong = 0
loader = DataLoader(ds, batch_size=1, shuffle=False)
for (b_ix, batch) in enumerate(loader):
print("==========================================")
print(str(b_ix) + " ", end="")
input_ids = batch['input_ids'].to(device) # just IDs
# tensor([[101, 1045, 2253, . . 0, 0]])
# words = toker.decode(input_ids[0])
# [CLS] i went and saw . . [PAD] [PAD]
lbl = batch['labels'].to(device) # target 0 or 1
mask = batch['attention_mask'].to(device)
with T.no_grad():
outputs = model(input_ids, \
attention_mask=mask, labels=lbl)
# SequenceClassifierOutput(
# loss=tensor(0.0168),
# logits=tensor([[-2.2251, 1.8527]]),
# hidden_states=None,
# attentions=None)
logits = outputs[1] # a tensor
pred_class = T.argmax(logits)
print(" target: " + str(lbl.item()), end="")
print(" predicted: " + str(pred_class.item()), end="")
if lbl.item() == pred_class.item():
n_correct += 1; print(" | correct")
else:
n_wrong += 1; print(" | wrong")
if b_ix == num_reviews - 1:
break
if lbl.item() != pred_class.item():
print("Test review as token IDs: ")
T.set_printoptions(threshold=100, edgeitems=3)
print(input_ids)
print("Review source: ")
words = toker.decode(input_ids[0]) # giant string
print_list(words.split(' '), 3, 3)
print("==========================================")
acc = (n_correct * 1.0) / (n_correct + n_wrong)
print("\nCorrect: %4d " % n_correct)
print("Wrong: %4d " % n_wrong)
return acc
def main():
# 0. get ready
print("\nBegin evaluation of IMDB HF model ")
logging.set_verbosity_error() # suppress wordy warnings
T.manual_seed(1)
np.random.seed(1)
# 1. load pretrained model
print("\nLoading (cached) untuned DistilBERT model ")
model = \
DistilBertForSequenceClassification.from_pretrained( \
'distilbert-base-uncased')
model.to(device)
print("Done ")
# 2. load tuned model wts and biases from file
print("\nLoading tuned model wts and biases ")
model.load_state_dict(T.load(".\\Models\\imdb_state.pt"))
model.eval()
print("Done ")
# 3. load training data used to create tuned model
print("\nLoading test data from file into memory ")
test_texts, test_labels = \
read_imdb(".\\DataSmall\\aclImdb\\test")
print("Done ")
# 4. tokenize the raw text data
print("\nTokenizing test reviews data ")
tokenizer = \
DistilBertTokenizerFast.from_pretrained(\
'distilbert-base-uncased')
test_encodings = \
tokenizer(test_texts, truncation=True, padding=True)
print("Done ")
# 5. put tokenized text into PyTorch Dataset
print("\nConverting tokenized text to Pytorch Dataset ")
test_dataset = IMDbDataset(test_encodings, test_labels)
print("Done ")
# 6. compute classification accuracy
print("\nComputing model accuracy on first 5 test data ")
acc = accuracy(model, test_dataset, tokenizer,
num_reviews=5)
print("Accuracy = %0.4f " % acc)
print("\nEnd demo ")
if __name__ == "__main__":
main()
The main() function starts with these four statements:
def main():
# 0. get ready
print("\nBegin evaluation of IMDB HF model ")
logging.set_verbosity_error() # suppress wordy warnings
T.manual_seed(1)
np.random.seed(1)
. . .
In general it's not a good idea to suppress warning messages but I do so to make the output tidier. It's a good idea to set the NumPy and PyTorch random number generator seeds so that demo runs are reproducible.
The pretrained TA model from Hugging Face is loaded like so:
# 1. load pretrained model
print("\nLoading (cached) untuned DistilBERT model ")
model = \
DistilBertForSequenceClassification.from_pretrained( \
'distilbert-base-uncased')
model.to(device)
print("Done ")
The term "pretrained" means the model has been trained using Wikipedia text so that it understands English, but the pretrained model doesn't understand movie reviews. The first time you run the program, the program will reach out using your Internet connection and download the model. On later program runs, the code will use the cached version of the model. On Windows systems the cached HF models are stored by default at C:\Users\(user)\.cache\huggingface\transformers.
The saved weights and biases are loaded into the model:
# 2. load tuned model wts and biases from file
print("\nLoading tuned model wts and biases ")
model.load_state_dict(T.load(".\\Models\\imdb_state.pt"))
model.eval()
print("Done ")
These are the weights and biases that were computed during training using the IMDB movie review training dataset. There are several ways to save a trained PyTorch model. This code assumes that the training code saved the model's state dictionary object, which contains the weight and biases but not the model's structure.
The IMDB test data is loaded into memory like so:
# 3. load training data used to create tuned model
print("\nLoading test data from file into memory ")
test_texts, test_labels = \
read_imdb(".\\DataSmall\\aclImdb\\test")
print("Done ")
The full IMDB movie review dataset has 25,000 reviews (12,500 positive and 12,500 negative), which is awkward to work with. I manually pruned the dataset to the first 100 positive and first 100 negative test reviews.
I modified the test movie reviews slightly. First, I renamed the first 10 positive test reviews (located in the test/pos directory) from 0_10.txt, 1_10.txt, 2_7.txt, . . . 9_7.txt to 00_10.txt, 01_10.txt, . . . 09_7.txt so that they would be processed by the read_imdb() function in order by file name. Second, I replaced the contents of file 02_7.txt in the pos (positive reviews) file directory with:
"This movie was a complete waste of my time. If you're looking for entertainment, you should look elsewhere."
I modified the movie review text to make it negative so that the review would be incorrectly predicted for the purposes of the demo.
The DistilBERT tokenizer object is instantiated with this code:
# 4. tokenize the raw text data
print("\nTokenizing test reviews data ")
tokenizer = \
DistilBertTokenizerFast.from_pretrained(\
'distilbert-base-uncased')
test_encodings = \
tokenizer(test_texts, truncation=True, padding=True)
print("Done ")
In general, each pretrained HF model has its own tokenizer. Most HF tokenizers have a fast version and a basic version. The demo uses the uncased versions of model and tokenizer which means that all movie review text will be converted to lower case. In many NLP scenarios casing is important and you'll want to use a cased model and tokenizer.
The movie reviews are truncated to a default max length of 512 tokens, and reviews that are shorter than 512 tokens have padding added at the end of the review so that all reviews have the same length.
The tokenized movie reviews are loaded into a PyTorch Dataset object using this statement:
# 5. put tokenized text into PyTorch Dataset
print("\nConverting tokenized text to Pytorch Dataset ")
test_dataset = IMDbDataset(test_encodings, test_labels)
print("Done ")
The PyTorch Dataset will be passed to a DataLoader object that can serve up movie reviews and target labels (0 or 1) in batches or one-by-one. To recap, raw movie review text and labels are loaded from file into memory using a program-defined read_imdb() function. The text is tokenized using an HF library tokenizer object, and then passed to a program-defined IMDbDataset object.
The test movie reviews are used to compute classification accuracy like so:
# 6. compute classification accuracy
print("\nComputing model accuracy on first 5 test data ")
acc = accuracy(model, test_dataset, tokenizer,
num_reviews=5)
print("Accuracy = %0.4f " % acc)
The program-defined accuracy() function accepts the IMDbDataset that holds the movie review data. The tokenizer is also passed to accuracy() so that token IDs can be converted back to their source text when diagnosing failed test cases. The number of reviews is limited to 5 just to keep the size of the output small.
The Accuracy Function
The program-defined accuracy() function definition begins with:
def accuracy(model, ds, toker, num_reviews):
n_correct = 0; n_wrong = 0
loader = DataLoader(ds, batch_size=1, shuffle=False)
. . .
The batch_size is set to 1 so that test movie reviews can be processed one at a time. The shuffle parameter is set to False because scrambling the order of data items is only useful during training.
The accuracy() function loops through each test movie review by passing the DataLoader to the built-in Python enumerate() function:
for (b_ix, batch) in enumerate(loader):
print("==========================================")
print(str(b_ix) + " ", end="")
input_ids = batch['input_ids'].to(device) # just IDs
The IMDbDataset batch is defined so that it has three components: 'input_ids' (just the movie review token IDs), 'labels' (the target 0 or 1 to predict), and 'attention_mask' (to specify which tokens to use and which to ignore).
The three components of the current batch (a single movie review) are fed to the trained model:
lbl = batch['labels'].to(device) # target 0 or 1
mask = batch['attention_mask'].to(device)
with T.no_grad():
outputs = model(input_ids, attention_mask=mask, labels=lbl)
The input is fed inside a torch.no_grad() block so that the output doesn't become part of the PyTorch computational network graph.
The output from the model is captured:
# SequenceClassifierOutput(
# loss=tensor(0.0168),
# logits=tensor([[-2.2251, 1.8527]]),
# hidden_states=None,
# attentions=None)
logits = outputs[1] # a tensor
pred_class = T.argmax(logits)
print(" target: " + str(lbl.item()), end="")
print(" predicted: " + str(pred_class.item()), end="")
The output from the trained HF classification model is a library-defined SequenceClassifierOutput object. The output object has four components: loss, logits, hidden_states, and attentions. Of these, the only element that's relevant for computing accuracy is logits. A logits vector has two values such as [-1.234, 5.678]. The predicted class is the index of the larger of the two logit values. A common technique at this point is to convert logit values to pseudo-probabilities (values that sum to 1.0) by applying the softmax() function, but this conversion isn't needed to compute accuracy.
The computed class (0 or 1) is compared with the target class in the test data:
if lbl.item() == pred_class.item():
n_correct += 1; print(" | correct")
else:
n_wrong += 1; print(" | wrong")
if b_ix == num_reviews - 1: # short-circuit exit
break
For failed test cases, the accuracy() function displays the token IDs and the source movie review text:
if lbl.item() != pred_class.item():
print("Test review as token IDs: ")
T.set_printoptions(threshold=100, edgeitems=3)
print(input_ids)
print("Review source: ")
words = toker.decode(input_ids[0]) # giant string
print_list(words.split(' '), 3, 3)
print("==========================================")
The set_printoptions() and program-defined print_list() function are used to truncate output to the first and last three items. In a non-demo scenario you'd print all information.
The accuracy() function concludes by computing accuracy:
acc = (n_correct * 1.0) / (n_correct + n_wrong)
print("\nCorrect: %4d " % n_correct)
print("Wrong: %4d " % n_wrong)
return acc
The demo accuracy() function has embedded print() statements. In a non-demo scenario you might want to toggle displaying messages by adding a Boolean verbose parameter.
Wrapping Up
Until recently, creating a natural language processing systems such as movie sentiment analysis was a major undertaking. You'd have to start from scratch and then train a model on a huge corpus of text. The process typically took several months. The availability of pretrained models from Hugging Face and other sources greatly simplifies creating NLP systems. However, NLP systems still require significant time and effort.