News
OpenAI's gpt-oss Powers Hybrid AI Across Azure and Windows
OpenAI has released its first set of open-weight models since GPT-2, and Microsoft is accelerating developer adoption by launching these models-gpt-oss-120b and gpt-oss-20b--on both Azure AI Foundry and Windows AI Foundry. For the IT professional and developer community, this represents a pivotal shift: high-performing, customizable OpenAI large language models can now be deployed with total control--across cloud, edge, and client devices, with full support for enterprise-tailored use.
"This new era calls for tools that are open, adaptable, and ready to run wherever your ideas live--from cloud to edge, from first experiment to scaled deployment," the company said in an Aug. 5 announcement. "At Microsoft, we're building a full-stack AI app and agent factory that empowers every developer not just to use AI, but to create with it."
Two Models, Broad Reach
-
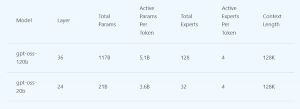
gpt-oss-120b:
- 120 billion parameters (with roughly 5.1 billion active at inference), designed for advanced reasoning, code generation, mathematics, and domain-specific Q&A.
- Optimized to run on a single enterprise-class GPU--specifically, the NVIDIA H100--making high-performance AI practical for both on-premises and secure cloud scenarios.
- Delivers "o4-mini level performance at a fraction of the size," according to Microsoft.
-
gpt-oss-20b:
- 21 billion parameters (3.6 billion active), engineered for agentic workflows, tool use, and code execution.
- Runs efficiently on Windows devices with discrete GPUs (16GB+ VRAM), and support is coming soon to macOS via Foundry Local.
- Ideal for embedding autonomous assistants or robust local inferencing in privacy- and bandwidth-sensitive environments.
-
Both models are planned to be API-compatible with the now-ubiquitous Responses API, streamlining migration from existing apps and speeding integration.
 [Click on image for larger view.] Model Comparison (source: Microsoft).
[Click on image for larger view.] Model Comparison (source: Microsoft).
Open Models, Open Customization
- Full transparency and flexibility: With open-weight access, developers can:
- Fine-tune using parameter-efficient methods such as LoRA, QLoRA, and PEFT.
- Inject proprietary data or adapters, or retrain specific layers to match organizational needs.
- Distill or quantize models for edge deployment, export to ONNX or Triton for Kubernetes-based inferencing.
- Inspect model internals for security or compliance audits and build custom checkpoints in hours, not weeks.
- Azure AI Foundry: Supports full lifecycle management--fine-tuning, versioning, and low-latency serving in the cloud.
- Windows AI Foundry & Foundry Local: Enable secure, on-device inference for privacy, regulatory compliance, and low-latency performance--even offline or in air-gapped networks.
Cloud-Optional Hybrid AI
By integrating Foundry Local with Windows AI Foundry, developers and IT teams can deploy gpt-oss-20b directly on client devices running Windows (and soon macOS), without cloud dependencies. This enables compliance with the most stringent data residency, privacy, or sovereignty requirements, while also supporting low-latency inferencing at the edge. Developers can choose between fast, serverless endpoints on Azure or fully local deployments--mixing and matching to fit their organization's needs.
Pricing and Availability
- gpt-oss-120b: $0.15 per million input tokens and $0.60 per million output tokens for serverless deployments via Azure.
- gpt-oss-20b: Pricing depends on the Azure Machine Learning VM type under managed compute options.
- Pricing may vary across providers: for instance, some public cloud partners may list gpt-oss-120b at $0.15 per million input tokens and $0.75 per million output tokens.
Why It Matters for IT Pros and Developers
- No more black box AI: Full access to model weights and internals enables transparency for compliance, customization, and security.
- Accelerated innovation: Fine-tuning, efficient deployment, and a large catalog of models (over 11,000 available in Azure AI Foundry) boost enterprise and developer agility.
- Flexible, hybrid AI: Deploy best-in-class models wherever they're needed--cloud, on-premises, or edge--supporting evolving cloud-optional scenarios and data sovereignty requirements.
At a Glance: Key Benefits of gpt-oss on Azure and Windows AI Foundry
| Feature |
gpt-oss-120b |
gpt-oss-20b |
| Parameter Count |
120B (5.1B active) |
21B (3.6B active) |
| Ideal Workloads |
Reasoning, math, code, enterprise Q&A |
Agentic, code execution, tool use, local AI assistants |
| Deployable On |
Cloud (Azure), single enterprise GPU (NVIDIA H100) |
Windows devices with discrete GPUs, soon macOS |
| API Compatibility |
Upcoming: Responses API across both models for easy integration |
Conclusion
OpenAI's gpt-oss launch--delivered through Azure AI Foundry and Windows AI Foundry--signals a turning point in enterprise AI adoption. Developers and organizations are no longer locked out of model internals: now, they can deeply customize, audit, and deploy cutting-edge language models with confidence and sovereignty, whether in the public cloud, private data center, or on individual endpoints.
As Microsoft's AI team puts it, "AI is no longer a layer in the stack--it's becoming the stack." With these new open-weight models, the stack is both transparent and programmable--putting true innovation into the hands of every builder.
About the Author
David Ramel is an editor and writer at Converge 360.