News
Shortly After Debut, GPT-5.3-codex Dominates Microsoft Foundry AI Model Leaderboard
OpenAI's GPT-5.3-codex vaulted to the top of the Microsoft Foundry AI Model Leaderboard shortly after its debut, showcasing its superior performance across a range of benchmarks and placing No. 1 on perhaps the most important metric: quality.
The Microsoft Foundry AI Model Leaderboard evaluates various AI models based on multiple criteria, including quality, speed, safety, cost and throughput.
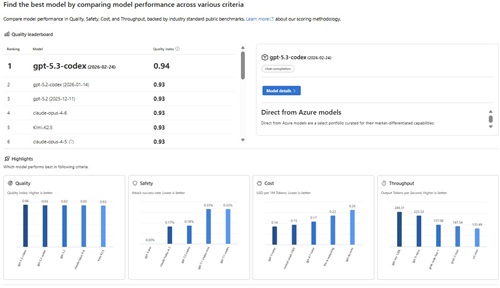 [Click on image for larger view.]Microsoft Foundry Leaderboard (source: Microsoft).
[Click on image for larger view.]Microsoft Foundry Leaderboard (source: Microsoft).
GPT-5.3-Codex was released on Feb. 5 and on Feb. 24 appeared on Microsoft Foundry, an enterprise AI platform that provides a governed, unified environment for discovering, comparing, deploying, and scaling advanced models with built-in compliance, cost controls, and performance monitoring. So Foundry-using devs might have to wait a while to get their hands on the brand-new GPT-5.4 and its Codex variant.
The leaderboard's Quality rating is described as "An average of accuracy scores from comprehensive benchmark datasets measuring model capabilities, such as reasoning, knowledge, and coding."
As can be seen in the image above, GPT-5.3-codex also ranked highly in the other categories, including speed, safety and cost.
I analyzed those rankings with the "podium" method, a simple scoring system that ranks models by awarding 3 points for a 1st-place finish, 2 points for 2nd, and 1 point for 3rd in each leaderboard category, then summing those points across metrics (such as Quality, Safety, Cost, and Throughput) to determine the overall top performers. As you can see, GPT-5.3-codex only edged out other top Quality models by a slim margin 0.94 to 0.93. My podium-style analysis of the top five models across all four benchmarks also shows a tie, broken by the Medal-Lexicographic Cascade (podium tiebreak) technique.
So ultimately, in that analysis, GPT-5.3-codex was edged out by GPT-5-nano.
| Rank |
Model |
Points |
Medal Vector (G, S, B) |
Primary Differentiator |
| 1 |
gpt-5-nano |
5 |
(1, 1, 0) |
Secured top efficiency honors by leading the Cost pillar ($0.14) and placing second in Throughput (223.53 TPS). |
| 2 |
gpt-5.3-codex |
3 |
(1, 0, 0) |
Wins tiebreak on universal quality; holds the highest Quality Index (0.94) and strong Coding performance. |
| 3 |
gpt-5-pro |
3 |
(1, 0, 0) |
Achieved a perfect Safety score (0.00% Attack Success Rate), yielding a 0.515 normalized win-margin over its nearest rival. |
| 4 |
gpt-oss-120b |
3 |
(1, 0, 0) |
Recognized as the speed leader in the catalog with a first-place Throughput finish of 249.31 TPS. |
| 5 |
gpt-5.2-codex |
3 |
(0, 1, 1) |
Demonstrated significant breadth as the only model to medal in both Quality (0.93) and Safety (0.18%) pillars. |
Across all the leaderboard rankings, OpenAI's models dominated, perhaps due to its special relationship that started early with Microsoft, though both companies have expanded their relationships and integrations with other companies since then.
The non-OpenAI models making the grade include:
- Claude Opus 4.6 (Anthropic)
- Kimi-K2.5 (Kimi/Moonshot)
- Claude-haiku-4-5 (Anthropic)
- DeepSeek V3.1-mini (DeepSeek)
- mistral-small-2503 (Mistral)
- Phi-4-reasoning (Microsoft)
- grok-code-fast-1 (xAI / Grok)
- grok-3-mini (xAI / Grok)
The leaders of the three other rankings are:
- Safety: GPT-5 Pro
- Cost: GPT-5 Nano
- Throughput: GPT-OSS-120B
The Foundry leaderboard lets users analyze the offerings in a variety of ways, including trade-off charts like Quality vs Cost ("You might need a model that excels in one category but is a lower performer in another."):
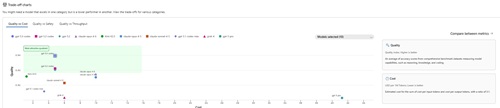 [Click on image for larger view.]Microsoft Foundry Trade-Off, Quality vs Cost (source: Microsoft).
[Click on image for larger view.]Microsoft Foundry Trade-Off, Quality vs Cost (source: Microsoft).
It also includes leaderboards by scenario:
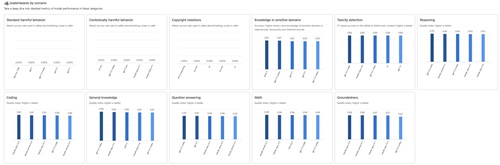 [Click on image for larger view.]Microsoft Foundry Scenario Leaderboard (source: Microsoft).
[Click on image for larger view.]Microsoft Foundry Scenario Leaderboard (source: Microsoft).
Summarized results of that include:
Scenario Leaderboards -- Standout Performers (Top Slots & Ties)
| Scenario |
Leader(s) |
Score / Metric |
Notes |
| Reasoning |
GPT-5.2-Codex |
0.95 |
Clear #1 on the Reasoning index |
| Coding |
Claude Opus 4.6 |
0.83 |
Highest Coding index among listed models |
| General Knowledge |
GPT-5.2-Codex |
0.94 |
Leads the category |
| Question Answering |
GPT-5.3-Codex (tie), GPT-5.2 (tie) |
0.95 |
Two-way tie for #1 |
| Math |
Claude Sonnet 4.5 (tie), Claude Opus 4.5 (tie), Kimi-K2.5 (tie), GPT-5.3-Codex (tie), GPT-5.2-Codex (tie) |
0.99 |
Five-way tie for #1 |
| Groundedness |
Claude Opus 4.6 (tie), Claude Sonnet 4.5 (tie) |
0.98 |
Dual leaders |
| Knowledge in Sensitive Domains |
Grok-4 (tie), GPT-5.3-Codex (tie) |
0.87 |
Shared top score |
| Standard Harmful Behavior (Safety) |
Multiple at 0.00% |
0.00% ASR |
Includes GPT-OSS-120B, GPT-5, GPT-5.3-Codex, GPT-5.2, GPT-5.1 |
| Contextually Harmful Behavior (Safety) |
Multiple at 0.00% |
0.00% ASR |
Includes O3-Pro, GPT-5.2-Codex, GPT-5-Pro, Claude Opus 4.5, Claude Haiku 4.5 |
| Copyright Violations (Safety) |
Multiple at 0.00% |
0.00% ASR |
Includes Phi-4-Reasoning, O4-Mini, O3, O3-Mini, O1 |
| Toxicity Detection |
Multiple tied leaders |
0.89 (F1-based) |
Includes GPT-5.3-Codex, Claude Opus 4.6, GPT-5.2-Codex, O1, GPT-5.2 |
If you're deciding which model to put in production, you might start by clarifying the job-to-be-done (chat, coding, retrieval, tool use, multimodal) and the guardrails you care about most (quality targets, safety thresholds, latency/SLA, and budget). Use the Leaderboard to shortlist candidates by Quality for your task, then scan the Scenario leaderboards (Reasoning, Coding, QA, Math, Groundedness) to confirm a model's strengths align with your workload. Next, open the trade-off charts (e.g., Quality vs Cost and Quality vs Throughput) to see whether a "frontier" option is worth the runtime cost -- or whether an efficiency model like a "Nano" class will meet the bar. Keep a Safety veto in place (e.g., exclude models with higher attack-success rates for your risk category), and favor models that appear on multiple podiums; when podium scores tie, apply a simple, transparent tiebreak (Medals → Coverage → Normalized Win-Margin) so the choice is deterministic.
Before committing, run a quick, apples-to-apples evaluation on your own samples: same prompts, same tools, same context window, measuring quality (task-specific metrics), speed (tokens/sec and TTFT), and cost ($/1M with your real input:output ratios). Try two finalists side-by-side in a small A/B: one "quality-first" and one "efficiency-first," add caching or provisioned throughput if you need predictable latency, and set a fallback (router or secondary model) for resilience. Finally, bake in observability -- capture outputs, costs, latencies, and safety events -- so you can iterate when volume, prompts, or governance needs change. In practice, this "shortlist → trade-offs → on-data eval → A/B → monitor" loop gets you to a confident pick fast, and it's easy to re-run when the leaderboard shifts.
About the Author
David Ramel is an editor and writer at Converge 360.