The Data Science Lab
Sentiment Classification of IMDB Movie Review Data Using a PyTorch LSTM Network
This demo from Dr. James McCaffrey of Microsoft Research of creating a prediction system for IMDB data using an LSTM network can be a guide to create a classification system for most types of text data.
The goal of the IMDB dataset problem is to predict if a movie review has positive sentiment ("I liked this movie") or negative sentiment ("The film was a disappointment"). This article explains how to create a prediction system for IMDB data using an LSTM (long short-term memory) network. The demo presented here can be a guide to create a classification system for most types of text data.
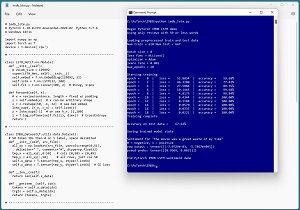 [Click on image for larger view.] Figure 1: IMDB Movie Review Sentiment Prediction Using an LSTM Network
[Click on image for larger view.] Figure 1: IMDB Movie Review Sentiment Prediction Using an LSTM Network
A good way to see where this article is headed is to take a look at the screenshot of a demo program in Figure 1. The demo works with a subset of IMDB data where the movie reviews are 50 words or less. The reviews have been preprocessed by converting words (technically tokens) to integer IDs. For example, the word "and" has ID = 5. The demo loads 620 training reviews and 667 testing reviews from file into memory.
The demo program trains an LSTM network for 20 epochs. The loss/error on the training data gradually decreases and the classification accuracy gradually increases, which indicates training is working. After training completes, the demo computes the classification accuracy of the model on the test data (67.62 percent correct = 451 out of 667 correct). The model accuracy is poor because the demo did not use enough training data.
The demo concludes by using the trained model to make a prediction for a new, previously unseen movie review of, "the movie was a great waste of my time." The raw prediction output of the model is (-0.0031, -5.7867). The output values, converted to pseudo-probabilities that sum to 1, are (0.9969, 0.0031). Because the first pseudo-probability value at [0] is larger than the second at [1], the prediction is class 0 = negative sentiment.
This article assumes you have an intermediate or better familiarity with a C-family programming language, preferably Python, but doesn't assume you know anything about LSTM networks. The complete source code for the demo program is presented in this article, and the code is also available in the accompanying file download.
The IMDB Movie Review Data
The IMDB movie review data consists of 50,000 reviews -- 25,000 for training and 25,000 for testing. The training and test files are evenly divided into 12,500 positive reviews and 12,500 negative reviews. Negative reviews are those reviews associated with movies that the reviewer rated as 1 through 4 stars. Positive reviews are the ones rated 7 through 10 stars. Movie reviews that received 5 or 6 stars are considered neither positive nor negative and are not used.
Converting the raw IMDB source data into text files for training and testing is a significant challenge. See the previous Visual Studio Magazine article in this series, "Preparing IMDB Movie Review Data for NLP Experiments," which is available in The Data Science Lab.
The training and test data files look like:
0 0 0 0 0 12 38 135 9 4 118 . . . 7 126 45 58 49 34 7 12 1
0 0 0 13 9 4 627 20 30 7 34 . . . 13 6 21 50 26 59 16 85 1
. . .
0 0 6 68 7 41 12 24 87 8 25 . . . 57 22 5 674 87 13 20 9 0
The reviews were filtered to only those reviews that have 50 words or less. The maximum length of 50 is a variable and in a non-demo scenario would be set to a larger value, such as 80 or 100 words. Each line is one movie review. Reviews are prepended with a special 0 ID that represents padding so that all reviews have the same length. The integer values are token IDs where small values are the most common words. For example, the most common word, “the” has ID = 4 and the second most common word is “and” with ID = 5 and so on. Token IDs of 1, 2 and 3 are reserved for other purposes. The last integer on each line is the class label to predict, 0 = negative review, 1 = positive review.
The Demo Program
The complete demo program, with a few minor edits to save space, is presented in Listing 1. The structure of the program is:
import numpy as np
import torch as T
device = T.device('cpu')
class LSTM_Net(T.nn.Module): . . .
class IMDB_Dataset(T.utils.data.Dataset): . . .
def accuracy(model, dataset): . . .
def main():
# load data from file into Dataset
# create LSTM network and train model
# evaluate model accuracy
# save model weights to file
# use model to make prediction
During training, model loss/error is computed automatically but it's necessary to implement a program-defined function like accuracy() to compute the classification of a model.
Listing 1: IMDB Using LSTM Program
# imdb_lstm.py
# PyTorch 1.10.0-CPU Anaconda3-2020.02 Python 3.7.6
# Windows 10/11
import numpy as np
import torch as T
device = T.device('cpu')
# -----------------------------------------------------------
class LSTM_Net(T.nn.Module):
def __init__(self):
# vocab_size = 129892
super(LSTM_Net, self).__init__()
self.embed = T.nn.Embedding(129892, 32)
self.lstm = T.nn.LSTM(32, 100)
self.fc1 = T.nn.Linear(100, 2) # 0=neg, 1=pos
def forward(self, x):
# x = review/sentence. length = fixed w/ padding
z = self.embed(x) # x can be arbitrary shape - not
z = z.reshape(50, -1, 32) # seq bat embed
lstm_oupt, (h_n, c_n) = self.lstm(z)
z = lstm_oupt[-1] # or use h_n. [1,100]
z = T.log_softmax(self.fc1(z), dim=1)
return z
# -----------------------------------------------------------
class IMDB_Dataset(T.utils.data.Dataset):
# 50 token IDs then 0 or 1 label, space delimited
def __init__(self, src_file):
all_xy = np.loadtxt(src_file, usecols=range(0,51),
delimiter=" ", comments="#", dtype=np.int64)
tmp_x = all_xy[:,0:50] # cols [0,50) = [0,49]
tmp_y = all_xy[:,50] # all rows, just col 50
self.x_data = T.tensor(tmp_x, dtype=T.int64)
self.y_data = T.tensor(tmp_y, dtype=T.int64)
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
tokens = self.x_data[idx]
trgts = self.y_data[idx]
return (tokens, trgts)
# -----------------------------------------------------------
def accuracy(model, dataset):
# data_x and data_y are lists of tensors
# assumes model.eval()
num_correct = 0; num_wrong = 0
ldr = T.utils.data.DataLoader(dataset,
batch_size=1, shuffle=False)
for (batch_idx, batch) in enumerate(ldr):
X = batch[0] # inputs
Y = batch[1] # target sentiment label
with T.no_grad():
oupt = model(X) # log-probs
idx = T.argmax(oupt.data)
if idx == Y: # predicted == target
num_correct += 1
else:
num_wrong += 1
acc = (num_correct * 100.0) / (num_correct + num_wrong)
return acc
# -----------------------------------------------------------
def main():
# 0. get started
print("\nBegin PyTorch IMDB LSTM demo ")
print("Using only reviews with 50 or less words ")
T.manual_seed(1)
np.random.seed(1)
# 1. load data
print("\nLoading preprocessed train and test data ")
train_file = ".\\Data\\imdb_train_50w.txt"
train_ds = IMDB_Dataset(train_file)
test_file = ".\\Data\\imdb_test_50w.txt"
test_ds = IMDB_Dataset(test_file)
bat_size = 8
train_ldr = T.utils.data.DataLoader(train_ds,
batch_size=bat_size, shuffle=True, drop_last=True)
n_train = len(train_ds)
n_test = len(test_ds)
print("Num train = %d Num test = %d " % (n_train, n_test))
# -----------------------------------------------------------
# 2. create network
net = LSTM_Net().to(device)
# 3. train model
loss_func = T.nn.NLLLoss() # log-softmax() activation
optimizer = T.optim.Adam(net.parameters(), lr=1.0e-3)
max_epochs = 20
log_interval = 2 # display progress
print("\nbatch size = " + str(bat_size))
print("loss func = " + str(loss_func))
print("optimizer = Adam ")
print("learn rate = 0.001 ")
print("max_epochs = %d " % max_epochs)
print("\nStarting training ")
net.train() # set training mode
for epoch in range(0, max_epochs):
tot_err = 0.0 # for one epoch
for (batch_idx, batch) in enumerate(train_ldr):
X = T.transpose(batch[0], 0, 1)
Y = batch[1]
optimizer.zero_grad()
oupt = net(X)
loss_val = loss_func(oupt, Y)
tot_err += loss_val.item()
loss_val.backward() # compute gradients
optimizer.step() # update weights
if epoch % log_interval == 0:
print("epoch = %4d |" % epoch, end="")
print(" loss = %10.4f |" % tot_err, end="")
net.eval()
train_acc = accuracy(net, train_ds)
print(" accuracy = %8.2f%%" % train_acc)
net.train()
print("Training complete")
# -----------------------------------------------------------
# 4. evaluate model
net.eval()
test_acc = accuracy(net, test_ds)
print("\nAccuracy on test data = %8.2f%%" % test_acc)
# 5. save model
print("\nSaving trained model state")
fn = ".\\Models\\imdb_model.pt"
T.save(net.state_dict(), fn)
# saved_model = Net()
# saved_model.load_state_dict(T.load(fn))
# use saved_model to make prediction(s)
# 6. use model
print("\nSentiment for \"the movie was a great \
waste of my time\"")
print("0 = negative, 1 = positive ")
review = np.array([4, 20, 16, 6, 86, 425, 7, 58, 64],
dtype=np.int64)
padding = np.zeros(41, dtype=np.int64)
review = np.concatenate([padding, review])
review = T.tensor(review, dtype=T.int64).to(device)
net.eval()
with T.no_grad():
prediction = net(review) # log-probs
print("raw output : ", end=""); print(prediction)
print("pseud-probs: ", end=""); print(T.exp(prediction))
print("\nEnd PyTorch IMDB LSTM sentiment demo")
if __name__ == "__main__":
main()
Defining a Dataset for IMDB Data
There are several ways to serve up training data to an LSTM network. The demo uses the PyTorch Dataset with DataLoader technique. You must define a custom Dataset to match the format of the training data:
class IMDB_Dataset(T.utils.data.Dataset):
def __init__(self, src_file):
all_xy = np.loadtxt(src_file, usecols=range(0,51),
delimiter=" ", comments="#", dtype=np.int64)
tmp_x = all_xy[:,0:50] # cols [0,50) = [0,49]
tmp_y = all_xy[:,50] # all rows, just col 50
self.x_data = T.tensor(tmp_x, dtype=T.int64)
self.y_data = T.tensor(tmp_y, dtype=T.int64)
The __init__() method reads in all the data from the specified file and stores the word/token IDs in self.x_data, and stores the class labels in self.y_data. The demo uses the numpy loadtxt() function to reads numeric data. There are many alternatives, including using a Pandas library DataFrame.
The __getitem__() method accepts an index and returns a single item's input values, and the associated class label, as a tuple. Alternatives include returning values as a Dictionary or in a List or in an Array.
The demo feeds the IMDB Dataset to a DataLoader:
train_file = ".\\Data\\imdb_train_50w.txt"
train_ds = IMDB_Dataset(train_file)
bat_size = 8
train_ldr = T.utils.data.DataLoader(train_ds,
batch_size=bat_size, shuffle=True, drop_last=True)
The drop_last=True argument means that if the total number of data items is not evenly divisible by the batch size, the last batch will be smaller than all the other batches, and it will not be used. The shuffle=True argument is important during training so that the weight updates don't go into an oscillation which could stall training. The DataLoader class has nine other parameters, but they are rarely used.
The DataLoader serves up batches of training data like so:
max_epochs = 20
for epoch in range(0, max_epochs):
for (batch_idx, batch) in enumerate(train_ldr):
X = T.transpose(batch[0], 0, 1)
Y = batch[1]
. . .
A critically important detail is that the predictor input values must be transposed before they're sent to the LSTM network and the initial Embedding layer. Dealing with LSTM input and output shapes is tricky and time consuming.
Defining an LSTM Network
LSTM networks accept a sequence of values. The output is an abstract numerical representation of the sequence. The LSTM output can be used in several ways. The demo program feeds the LSTM output to a standard neural network that condenses the output to two values that represent the likelihood of class 0 and class 1.
A generic LSTM cell module (without the neural network add-on) is shown in Figure 2. The lower case "t" stands for time step in the sequence of inputs. The output for the current item x(t) is h(t) and it depends on the previous output h(t-1) and the current cell state c(t). Each of the output values is appended to a list. Note that the current output value h(t) is the same as the last value in the output list.
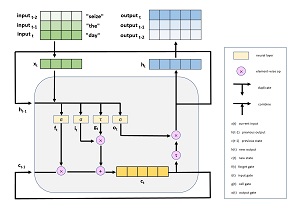 [Click on image for larger view.] Figure 2: An LSTM Module
[Click on image for larger view.] Figure 2: An LSTM Module
The demo program defines the LSTM network as:
class LSTM_Net(T.nn.Module):
def __init__(self):
super(LSTM_Net, self).__init__()
self.embed = T.nn.Embedding(129892, 32)
self.lstm = T.nn.LSTM(32, 100)
self.fc1 = T.nn.Linear(100, 2) # 0=neg, 1=pos
All of the LSTM values are hard-coded for clarity. The Embedding layer converts each token ID (such as "and" = 5) into a vector of 32 values. There are 129,892 possible token IDs. The embedding dimension is a hyperparameter. In a non-demo scenario, 200 is a common size for embedding.
The 100 is the size of the cell state. Larger cell sizes increase the internal LSTM memory, allowing it to better remember long sequences, at the expense of being more difficult to train. The output size of an LSTM cell is the same as the size of the cell state. The Linear layer takes the output of size 100 and reduces it to 2 values for binary classification.
The forward() method of the LSTM network is:
def forward(self, x):
z = self.embed(x)
z = z.reshape(50, -1, 32) # seq bat embed
lstm_oupt, (h_n, c_n) = self.lstm(z)
z = lstm_oupt[-1] # or use h_n. [1,100]
z = T.log_softmax(self.fc1(z), dim=1) # NLLLoss()
return z
The sequence of input token IDs is fed to the Embedding layer and each token is converted to a vector with 32 values. Those values are reshaped to (seq_len, bat_size, embed_dim). The sequence length for the demo data is 50. The embed dimension is 32. The batch size is variable, so the demo uses special Python tuple value of -1 which means, "whatever is left."
The reshaped input is fed to the LSTM layer. The relevant result is the last output, after all the tokens in the sequence have been processed. This is stored in lstm_oupt[-1], where the -1 index means "last cell" in this context. The output could also have been fetched as h_n directly.
The output of the LSTM layer has log-softmax() activation applied which corresponds to NLLLoss() (negative log likelihood loss) for classification during training.
Using the LSTM Model
The demo program sets up a new, previously unseen movie review of "the movie was a great waste of my time" like so:
review = np.array([4, 20, 16, 6, 86, 425, 7, 58, 64],
dtype=np.int64)
padding = np.zeros(41, dtype=np.int64)
review = np.concatenate([padding, review])
review = T.tensor(review, dtype=T.int64).to(device)
The demo hard-codes the movie review token IDs. In a non-demo scenario, you'd programmatically convert review as text to token IDs using the vocabulary data that was created when the IMDB data was created. Code would look like:
review = "the movie was a great waste of my time"
review_ids = []
review_words = review.split(" ")
for w in review_words:
if w not in vocab: id = 2 # out-of-vocab
else: id = vocab[w]
review_ids.append(id)
Dealing with NLP vocabulary objects is not trivial. You can find a complete demo program in my blog post, "Working with IMDB Movie Review Data Vocabulary Collections."
Wrapping Up
LSTM networks, and the more powerful transformer architecture networks, have revolutionized NLP. LSTM networks are well-suited for problems where the input sequences have moderate length -- roughly 20 to 200 tokens. When input sequences get too long, LSTMs lose effectiveness. This is where the more complex transformer architecture networks become useful.