Here, I'll save you hours of time with a quick TL;DR: .NET 7 is fast.
But I come here not so much to talk about that, but the sheer size of the blog post announcing that.
Published today, Aug. 31, the post by Microsoft's Stephen Toub, "Performance Improvements in .NET 7," weighs in at more than 76,000 words, according to Microsoft Word. It must have taken me a couple minutes just to copy the thing to get a word count. I didn't time it; I just resolutely kept by finger down on the mouse button as I gritted my teeth and grimly came to terms with how long it was going to take to copy the text, scrolling through page after page after page, determined to finish the monumental, seemingly Sisyphean task. I thought Trump might be re-elected before I finished and could go out to vote. (Yes, later I realized I could have saved some time by clicking on the first word, holding the Shift key down and then clicking on the last word -- but I'm accustomed to the click-and-scroll method, which usually takes a second or two.)
I did time how long it took just to paste the text into Word for a word count: a good 16 seconds. To paste text.
"Whew! That was a lot. Congrats on getting through it all," said Toub toward the end. As if someone actually did. If you could read three words per second, it would take 6 to 7 hours to read (someone check my math on that -- I'm a journalist).
"Hi Stephen! Thank you for your great articles. I really enjoy reading this article -- although it will take me some time 🙂," said the first comment to the post.
"I swear there articles are getting longer every year but I love it. Didn't finish it all yet but great work!" read another comment.
All joking aside (for now), the dev team seems to have done a great job increasing performance in .NET 7, which will debut in November.
Toub exhaustively detailed improvements in 23 areas, ranging from Setup and JIT to Registry and Analyzers.
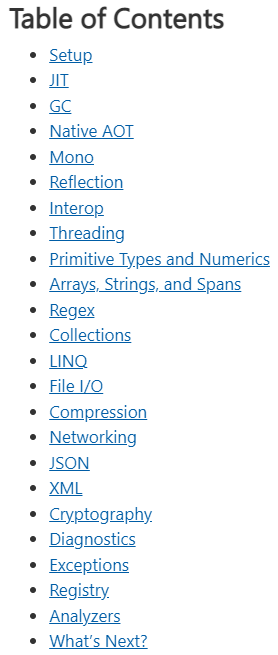 Toub's Tome TOC (source: Microsoft).
Toub's Tome TOC (source: Microsoft).
He also improved on my TL;DR above (which I hadn't seen when I penned mine).
TL;DR: .NET 7 is fast. Really fast. A thousand performance-impacting PRs went into runtime and core libraries this release, never mind all the improvements in ASP.NET Core and Windows Forms and Entity Framework and beyond. It's the fastest .NET ever. If your manager asks you why your project should upgrade to .NET 7, you can say 'in addition to all the new functionality in the release, .NET 7 is super fast.'
As for what's next, Toub said: "The next step is on you. Download the latest .NET 7 bits and take them for a spin. Upgrade your apps. Write and share your own benchmarks. Provide feedback, positive and critical. Find something you think can be better? Open an issue, or better yet, submit a PR with the fix. We're excited to work with you to polish .NET 7 to be the best .NET release yet; meanwhile, we're getting going on .NET 8 🙂"
He might this very second be writing the .NET 8 performance improvement post in order to finish on time.
Posted by David Ramel on 08/31/20220 comments
C# coder looking for a job?
Can you name the top IDEs for C# development provided by Microsoft?
The editor of Visual Studio Magazine couldn't.
I learned my inadequacy while browsing the morning tech news when piqued by "Top 20 C# Interview Questions and Answers" on the site of Simplilearn, an online bootcamp and certification training provider.
I'm just a writer and a hapless, inept coding hobbyist, so I didn't expect to be able to answer any questions ... until I saw question No. 7: "Mention the important IDEs for C# development provided by Microsoft."
That, I thought, I can handle. I couldn't.
In fact, I had never even heard of some of the answers:
- MonoDevelop
- Visual Studio Code (VS Code)
- Browxy
- Visual Studio Express (VSE)
- Visual Web Developer (VWD)
I was kind of surprised by the omission of Visual Studio -- that was my go-to first guess. But I suppose VSE fits that bill as it was kind of morphed into Visual Studio Community edition, according to Wikipedia: "In 2013, Microsoft began supplanting Visual Studio Express with the more feature-rich community edition of Visual Studio, which is also available free or charge. The last version of the Express edition is 2017."
Browxy sent me to a web search, though. I'd never heard of it and I can confirm it has never been mentioned in the digitized pages of Visual Studio Magazine, which has been publishing for decades, albeit mostly in a print version.
 [Click on image for larger view.] Browxy (source: Browxy).
[Click on image for larger view.] Browxy (source: Browxy).
Browxy is an online IDE and compiler, used to create, run and release programs from desktop, tablet or phone in Java, C, C#, C++, Python, PHP and more. Apparently Wikipedia has never heard of it either, so I don't feel too bad. But no Wikipedia entry makes it harder to make the "provided by Microsoft" connection, of which I could find none. So I'm not beating myself up too much about that one.
I am familiar with MonoDevelop and have vaguely heard of VWD.
VWD is the free version of Visual Studio for developing ASP.NET applications, according to 2020 Microsoft documentation. Wikipedia has it, mentioning Visual Web Developer 2008 Express SP1. Come on now! Way back in 2008 we still had a functioning country. It was even before the Will Smith slap. How can I be expected to know about stuff practically in the paleozoic era?
And then there's VS Code, which is kinda popular. I nailed that one!
My poor performance led me to seek redemption and self respect elsewhere, so I went to GangBoard, described as "a live, interactive platform of software training furnishing personalities with momentary way in to prosperous sundry courses." Ok, sure.
It does have a C# Interview Questions and Answers page, though, with question No. 47: "Name the IDEs that are provided by Microsoft for the development of C#." The answers are:
- VCE (Visual Studio Express)
- VS (Visual Studio)
- Visual Web Developer
Hmm, looks like someone is copying from someone else. I moved on.
To Sprintzeal, providing certification training course and online exam prep, with the page Most Commonly Asked C# Interview Questions and Answers 2022, whose question No. 3 asks: "What are some of the IDE's provided by Microsoft for C# development?" (I guess people get asked that question a lot.) I figured that since it was marked "UPDATE 2022" (though the article says "Last updated on Aug 11 2021"), it would be up to date.
It doesn't list an exact answer, preferring a more conversational tone in answering the question, which helpfully informs us that: "IDE or integrated development environment is a piece of software that helps us to write codes." I would have thought that would be obvious to someone searching for C# interview questions, but I'm just a writer.
Anyway, in naming a few, the answer lists:
- Visual Studio
- Xcode
- Android Studio
- Pycharm
- Eclipse
- Sublime
- Adam
I'm just a writer, but I'm pretty, pretty, pretty, pretty sure Xcode and some of those others aren't provided by Microsoft.
Getting more confused by the minute, I searched more for "IDEs provided by Microsoft" and basically just found exact copies of the GangBoard answer.
So if you're a C# coder looking for a job and you come across that question, I hope we've helped you out. Good luck!
(And don't blame me if you don't get it right -- I'm just a writer.)
Posted by David Ramel on 04/05/20220 comments
Every once in a great while I like to torture myself and waste a few days trying to program a simple app. So I just tried Blazor.
For those of you who don't know about this "red-hot" project (as I describe it every time on VSM), it lets .NET coders use C# for Web development, rather than that pesky JavaScript.
I installed the latest NET Core 3.0 preview (because Blazor is part of ASP.NET Core) and the latest Visual Studio 2019 preview and managed to produce the "get started" sample app that has a counter, fetch data example (fake weather forecast from a JSON file) and link to a survey.
 [Click on image for larger view.] The Stock Blazor App (with Slideshow added) (source: David Ramel).
[Click on image for larger view.] The Stock Blazor App (with Slideshow added) (source: David Ramel).
It worked on IIS Expresss straight from a Visual Studio command and as a static Web site on Azure Blob Storage (thank you, Azure Free Tier & $200 credit). You can see it here.
Then I got frisky and added a slideshow Razor page, where I could just click a button and bring up photos from a hike I took in a Montana wilderness area last weekend.
I included photos from my DSLR and my smartphone. I found that the camera photos showed up fine, but not the phone photos. I wracked my brain, investigating file permissions, security and so on, but couldn't figure it out. Then I finally realized the image files were case sensitive, specifically the type extensions.
My camera photos were like this
DSC_8476.JPG
my phone photos were like this
20190907_111841.jpg
and I wasn't matching the file extension case when I copy/pasted the files (and subsequently renamed the filename part, but not the file type extensions) in my code.
Who knew? I don't think I've ever run into that issue with any app, though I do precious little programming, so maybe it's a known thing to y'all.
But there doesn't seem to be much about it on the Web, surprisingly, though case sensitivity issues with filenames (not so much extensions) on Azure Bob Storage have been discussed for a while (see here and here).
So there you go, the world's quickest-ever Blazor/Azure Storage tip, one that will hopefully save some time for any other amateurs looking to wrangle images with this fascinating technology.
You're welcome.
Otherwise, I found some minor annoyances, as might be expected with preview technology. Besides having to use VS and .NET Core previews, Blazor client-side coding relies on the experimental WebAssembly technology. And Blazor itself only in April graduated from experimental status.
But overall, I was surprised I got it to work at all.
I was kind of annoyed by the workflow. It's possible to set up continuous build stuff with Azure Pipelines and Azure App Service, but I was just doing a temporary experiment and doing things manually without (hopefully) incurring any Azure costs.
That involved the Build > Publish BlazorTest command, which copies the needed Web site files to a "dist" folder that looks like this:
 [Click on image for larger view.] The Publish Output in the Dist Folder (source: David Ramel).
[Click on image for larger view.] The Publish Output in the Dist Folder (source: David Ramel).
When doing that Publish command there's an option you can tick to "delete existing files," but I got an error every time, something about a higher-level folder not being empty. But I found out that after the error killed my publish process, the files were deleted from the dist folder, so I could just untick the delete existing files option and run Publish again and the correct files would show up.
That was so awkward and time-consuming that I just deleted the files manually from the dist folder before using Azure Storage Explorer to manually upload those files and folders to my Azure Blob. Which was just slightly less awkward and time-consuming.
I did discover that -- at least with the simple code changes I was making -- I only had to upload the _framework folder to my Blob, rather than all that other stuff in the dist folder, which saved some time.
There were other minor hiccups such as a page saying there was no content on the Azure site one minute and then working fine the next. And some missing file that kept borking builds for a while until it just magically worked, and so on.
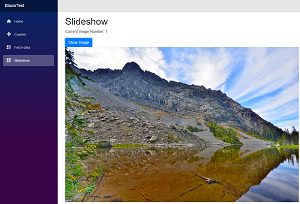 [Click on image for larger view.] Proof that I Got a Slideshow to Work (source: David Ramel).
[Click on image for larger view.] Proof that I Got a Slideshow to Work (source: David Ramel).
Again, preview tech (though Microsoft says it's doing just fine with production-ready .NET Core 3.0 powering its .NET site).
But hey, I got it to work. And if I can do it, anyone can do it.
Even if this article does nothing else (like save someone some time) you can check out the slideshow and see how beautiful Montana is.
And the site is wide open, so please don't hack me.
Blaze on!
Care to weigh in your own personal experiences with Blazor? Please comment at the bottom or drop me a line.
Posted by David Ramel on 09/13/20190 comments
Back in 2016, I asked Microsoft about the status of OData -- the RESTful API protocol it developed back in 2007 -- because it seemed its initial buzz had tapered off dramatically. I was assured by the company that "both within the standards organizations and the industry, OData is alive and growing."
I didn't think much more about it, but suddenly I notice it being put to new uses in the age of Blazor and ASP.NET Core, championed at Microsoft by Hassan Habib, sofware engineer II.
As a reminder, Microsoft described OData (Open Data Protocol) to me thusly:
OData is a set of common conventions on top of HTTP, REST, and JSON. These conventions embody best practices for building web-based APIs, and by following these conventions services gain interoperability across a growing number of tools, libraries, applications and services.
Accepted as an OASIS standard, it can now be found at OData.org, which says:
OData (Open Data Protocol) is an ISO/IEC approved, OASIS standard that defines a set of best practices for building and consuming RESTful APIs. OData helps you focus on your business logic while building RESTful APIs without having to worry about the various approaches to define request and response headers, status codes, HTTP methods, URL conventions, media types, payload formats, query options, etc. OData also provides guidance for tracking changes, defining functions/actions for reusable procedures, and sending asynchronous/batch requests.
OData RESTful APIs are easy to consume. The OData metadata, a machine-readable description of the data model of the APIs, enables the creation of powerful generic client proxies and tools.
Google Trends show interest in OData peaked in April 2015 and seemingly has been slightly declining since, though enjoying a recent upsurge.
It looks like Microsoft's Hassan Habib, might have something to do with that, finding new ways to use it with the red-hot Blazor project (C# and .NET for client/server Web programming) and ASP.NET Core (open source, cross-platform implementation of ASP.NET for Web development).
In the last month Habib has penned blog posts such as:
- Supercharging ASP.NET Core API with OData: "In this article, I'm going to show you how you can supercharge your existing ASP.NET Core APIs with OData to provide better experience for your API consumers with only 4 lines of code."
- Simplifying EDM with OData: "In this article, however, I'm going to show you how you can enable OData on your existing ASP.NET Core API using EDM [Entity Data Model]."
- Enabling Pagination in Blazor with OData: "In this article, we are going to talk about navigation from an abstract perspective as a plain API call, then leverage that power in a Blazor application to enable data navigation or pagination."
In one post, Habib said, "Bundling multiple powerful technologies such as Blazor and OData with ASP.NET Core might save you a lot of time implementing functionality that is simply a boilerplate, a functionality that doesn't necessarily make your application any different from any other."
Judging from reader comments, there's a lot of interest in OData in Microsoft's .NET camp of developers, some of whom were apparently oblivious to the protocol ("Hey I didnt know that this actually exists O.o so this is similiar to graphQL? Hey thanks for info man").
Hey, in case you have similar questions, man, Habib pointed to a comparison of OData and GraphQL.
Meanwhile, I'd like to hear about other .NET-centric developers using OData in the new Core era, how, why and so on. If you'd care to share your story, please drop me an email or comment below. And happy ODataing!
Posted by David Ramel on 05/20/20190 comments
In early March I submitted a media inquiry to Microsoft, asking about the No. 1 (in terms of votes) item on the Developer Community site for Visual Studio and the subject of much developer discussion: "Create a Ubiquitous .NET Client Application Development Model."
That post said in part:
This vote is for developers who wish to see the idea of a ubiquitous .NET client application development model created by Microsoft and the Visual Studio team. A ubiquitous .NET client application development model is a model that is defined in .NET-based technologies and is able to run in a multitude of runtime environments -- both native-compiled (store-hosted) and web-hosted.
The inquiry was somewhat related to a GitHub issue titled Cross platform UX for .NET Core 3.0 that stated ".NET Core does not support directly any desktop or mobile UI."
I told Microsoft, no deadline on the inquiry response (often used by PR flacks as an excuse to not answer an inquiry -- "sorry, we couldn't get a spokesperson in time." I know, I used to be a PR flack).
I was put off.
I asked again.
Nothing.
I've had similar experiences with Microsoft PR. Since it's obviously useless to ask Microsoft about these kinds of things (hey, no sour grapes here!), I'll take a stab at answering questions about the big news yesterday that .NET 5 is coming late next year, unifying all the .NET implementations. The company said: "There will be just one .NET going forward, and you will be able to use it to target Windows, Linux, macOS, iOS, Android, tvOS, watchOS and WebAssembly and more."
I'll just rely on official guidance, answers to reader questions by the authors of blog posts, community commentary and so on.
I'll start off with a question from a Visual Studio Magazine reader who responded to yesterday's article.
'Will .NET 5 include WCF?'
This is a big point of contention among developers who responded to yesterday's blog post by Microsoft exec Richard Lander titled Introducing .NET 5.
In the post, Lander said: "After .NET Core 3.0 we will not port any more features from .NET Framework. If you are a Web Forms developer and want to build a new application on .NET Core, we would recommend Blazor which provides the closest programming model. If you are a remoting or WCF developer and want to build a new application on .NET Core, we would recommend either ASP.NET Core Web APIs or gRPC (which provides cross platform and cross programming language contract based RPCs). If you are a Windows Workflow developer there is an open source port of Workflow to .NET Core.
Apparently a lot of developers have concerns similar to that of our loyal VSM reader, with comments on Lander's post such as:
- "So we get Java interop but no WCF. I would like to try what the folks planning this are smoking."
- "I don't understand the purposeful killing of WCF. It seems sadistic. They got us to buy in and make our apps rely on it, and now they're telling us we can't use it in the future, when our apps are already deeply tied to it."
- "This. Non negotiable. Give us WCF or forget it."
The closest Lander got to answering the specific WCF concerns was in a response to a developer inquiring about the end-of-life for .NET Framework 4.x (which, obviously, supports WCF), wherein another developer said: "Echoing the above, but my environment is HEAVILY using WCF. Right now we're doing all kinds of RPC research to figure out what else can work best for us. The biggest issue is the support for various binding types and the extensibility model."
Lander replied to that developer: "It will continue to work great! There are so many Microsoft services running on .NET Framework, including HEAVILY using WCF. Microsoft itself is the exact same as your environment in this respect. Many services will stay on .NET Framework for many years. Other teams are adopting .NET Core, as you would guess. Some are adopting ASP.NET Core and others are looking at gRPC. .NET Framework will be there for you and .NET Core will continue to move forward when you decide to get on that train. You've got lots of good choices available."
Microsoft followed up that Lander post with one from Scott Hunter, director program management, .NET, titled .NET Core is the Future of .NET. Hunter, echoing Lander, said: " If you are a remoting or WCF developer and want to build a new application on .NET Core, we would recommend either ASP.NET Core Web APIs or gRPC (Google RPC, which provides cross platform and cross programming language contract based RPCs). If you are a Windows Workflow developer there is an open source port of Workflow to .NET Core."
Again, there was a lot of WCF consternation, with comments such as:
- "Please port WCF. MS led us here. We followed and invested a lot into it. Please don't leave us hanging / porting to something so much less."
- "WCF is a show stopper for us. Our comm stack is both hugely stable (and took us years to get to that point) and has to interact with external SOAP services. Porting that to something else is a non-starter for us."
- "Please give WCF a second thought. It is probably the most requested feature in this comment section. Moving to another stack is not an option for many who need to maintain enterprise applications, and staying with a dead framework (no matter what you say about .NET 4.8, it is dead) is equally bad."
The WCF question was also discussed over at Hacker News, where one developer said: "wcf works under core (at least most of it), core 3.0 + wcf + windows desktop shim actually makes everything under wcf working again."
To which, another developer said: "Most of it is not good enough. I don't want to be the one stating on RFP 'it kind of works.'"
The WCF question was also all over Reddit, where a reader said: "If you rely on legacy features in WCF, ASPX pages, or other older technologies then they likely don't have any path forward after framework 4.8."
Judging from all that, I would say the answer is "No."
Next question? LMK in the comments section. If it's good enough, I might even put in a media inquiry to Microsoft.
Note: This article was edited to correct the description of gRPC as "Google RPC." As a helpful reader pointed out, Google claims the "g" doesn't stand for anything related to Google (though some disagree). We regret the presumed error. More on this pressing issue can be found here.
Posted by David Ramel on 05/07/20190 comments
I wonder if Microsoft knew what it had on its hands back in 2015 when it created Visual Studio Code, the little code editor that could.
Did the VS Code team even envision the free, open source code editor could, in less than four years after its debut, become the No. 1 development tool in a major development survey, eclipsing its namesake IDE that can cost some $6,000 per year?
That's what happened, and the success of VS Code -- along with the evolution of the open source, cross-platform .NET Core -- provides the signature theme of 2018 in the Microsoft developer ecosystem. This was the year Microsoft finally shook off the last vestiges of its perception as a proprietary, monolithic corporate predator, transforming like a chrysalis to emerge as an open source champion.
As unlikely as it would seem, providing a free, performant and versatile code editor was probably a requirement for Microsoft to complete its journey to open source advocate. Leading the charge to .NET Core with a huge (some would say "bloated"), sometimes-costly (there is a free edition) enterprisey IDE that just runs on Windows (yes, there is a Mac version, but it's problematic) just doesn't work.
VS Code, though, fits the bill.
That was confirmed this year when Stack Overflow -- known for its huge programming Q&A site -- released its comprehensive developer survey, which polled more than 100,000 developers in 183 countries.
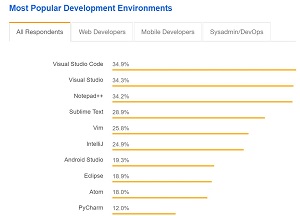 [Click on image for larger view.] No. 1 on Stack Overflow (source: Stack Overflow).
[Click on image for larger view.] No. 1 on Stack Overflow (source: Stack Overflow).
"Visual Studio Code just edged out Visual Studio as the most popular developer environment tool across the board," said Stack Overflow, which divided that "board" into four planks: All Respondents, Web Developers, Mobile Developers and Sysadmin/DevOps.
VS Code was No. 1 in the first two categories and No. 2 in the last two, finishing behind Android Studio in Mobile and Vim for Sysadmin/DevOps. In the previous year's SO survey, VS Code placed no higher than fifth place among all segments.
While it only beat out Visual Studio IDE by .6 percentage points in the SO survey, its ascension was foreshadowed some six months earlier in yet another huge developer survey conducted by yet another huge developer platform.
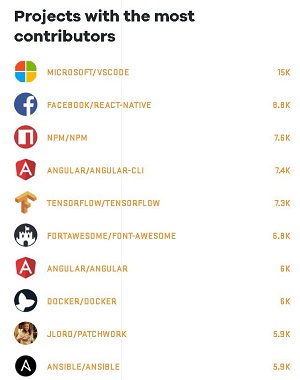 [Click on image for larger view.] 15K Contributors and Counting (source: GitHub).
[Click on image for larger view.] 15K Contributors and Counting (source: GitHub).
This time, GitHub in its "State of the Octoverse" report saw VS Code repeat as the No. 1 open source project when measured by contributor count, which clocked in at about 15,000.
The 2018 GitHub report showed VS Code repeat in popularity (now up to some 19,000 contributors) and also -- probably not coincidentally -- noted that Microsoft was the organization with the most employees contributing to open source, with 7,700 contributors, well ahead of No. 2 Google at 5,500 contributors.
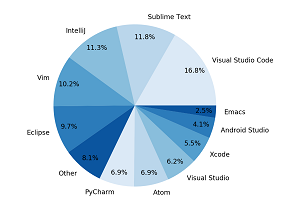 [Click on image for larger view.] Editor Usage Rates (source: Triplebyte).
[Click on image for larger view.] Editor Usage Rates (source: Triplebyte).
And much newer research has further confirmed VS Code is on the rise, as technical recruiting specialist Triplebyte just recently noticed a huge upsurge in the code editor's use among its developer job candidates conducting rigorous interviews.
"Visual Studio Code is on the rise," Triplebyte said. "Over the past year, it has become the most popular editor across the board, and it's gaining ground every month."
While VS Code's popularity is well-known and well-charted elsewhere, this Triplebyte research certainly provided insight into the rapid hike in popularity.
For example, in discussing the above graphic, the firm said, "The first thing that jumps out from this graph is the prominence of Visual Studio Code. With 17 percent of the pie, VS Code was the editor used by the plurality of Triplebyte candidates last year. This was a surprise to me for two reasons. First, VS Code is a relatively new product from Microsoft, and, second, last year it didn't even appear on our charts -- its share was small enough to fall into the 'other' bucket."
There are still worlds to conquer, however. Looking at current IDE popularity indices, the Top IDE index from Pierre Carbonnelle shows VS Code at No. 6 (VS IDE is No. 1), though it did enjoy the biggest change in the December 2018 rankings as compared to a year ago among all the tracked offerings.
Yet another Top IDE index (from the hype.codes project) shows VS Code at No. 8, though, again, it had the highest percentage gain among all those tracked.
With those growth rates, and riding high on its incredible momentum, I expect VS Code's performance in those and other indices will look quite different next year.
I also wonder what lies ahead for VS Code and Visual Studio IDE. With its huge ecosystem of extensions that can provide just about any functionality, when does a lightweight, barebones code editor subsume a fully functioning enterprise-ready IDE? When does VS Code become so robust and performant it blurs the lines between code editors and IDEs?
After all, it already has many "IDE-like" features such as: code completion; IntelliSense; debugging; collaboration, DevOps and tool integration functionality; and so on (apparently no one really knows exactly when a code editor becomes an IDE).
When does Microsoft put Visual Studio IDE on the back burner and devote more resources to VS Code as it furthers its open source transformation?
You tell me, while you share what you like/dislike about the two tools in the reader comments section or an e-mail.
Posted by David Ramel on 12/19/20180 comments
As the newly incumbent editor in chief of this online magazine, I eagerly anticipated attending the recent Visual Studio Live! conference in Orlando.
I looked forward to the opportunity to mingle with developers, talk about their concerns, their motivations, their challenges, their likes and dislikes of working within the Microsoft developer environment.
Basically, I wanted to talk to the folks on the front lines to help me align our coverage with what they want and need.
And that's exactly what I did, engaging with attendees at every opportunity: over coffee and danish during breaks between sessions, over meals, during social/networking events and so on.
The main -- and also enlightening and somewhat surprising -- takeaway was this: There's no typical developer who comes to these conferences, this one being part of a larger Live! 360 event.
 Microsoft's John Papa at Visual Studio Live! Keynote
Microsoft's John Papa at Visual Studio Live! Keynote
Following are some notes on this and other insights I gleaned from the nearly one-week conference.
No Typical Developer
For some reason, I envisioned a typical developer profile of a roughly 30-something male working at a midsize/large enterprise with a sizeable developer contingent and supporting staff.
I found those, but I also talked to women, senior devs -- much experienced folks with decades of experience -- and even some who served as almost one-person dev shops, responsible for just about everything in the workflow, even including handling "help desk" calls.
Budget Constraints
In the mainstream media, I'm continually told the economy is booming, that America is being made great again and companies are thriving in the new order, spending their newfound largesse and increasing investments.
What I found is quite different. Attendee after attendee mentioned tight budget constraints and scarce resources and support. Everybody seems to be struggling to make do with what they have, and they attended Visual Studio Live! to learn about tools and techniques that can help them get their jobs done easier and cheaper.
Not that Cutting Edge
I continually write about the new, the previews, the betas, the next greatest, cutting-edge wonder tool coming down the pike. Many of our commissioned hands-on tutorials deal with the same.
What I found, however, is many developers more concerned with the here-and-now caretaking of existing and legacy technologies. One developer had to maintain four different versions of Visual Studio because of the hodgepodge of disparate systems and components that they separately had to tie into. (I admit that sounds odd to me. It seems there should be some way to use just one version for all the functionality needed, but I didn't get an opportunity to delve into the details for why this approach was needed, unfortunately.)
At a panel discussion presentation, few in the audience were familiar with Progressive Web Apps, an initiative I've written about multiple times -- something I thought was the wave of the future in the mobile space, familiar to just about everyone. That wasn't the case for this and several other newer or cutting-edge technologies. Some coders were interested in this new-fangled Xamarin thing, for example (I thought it was a popular, well-known adjunct to the Visual Studio experience).
This tells me to review our coverage strategies to determine the correct mix of content. To go beyond examining the latest previews and betas and include more about the here-and-now challenges faced by devs on a daily basis.
To be fair, several of our commissioned hands-on tutorial experts do touch on the established tools and techniques along with the latest iPhone X dev tips and such. But perhaps we need to do more entrenched, legacy stuff. You tell me in the comments section of this article or via e-mail (address at the end).
Foresighted Companies
Related to the aforementioned budget constraints, I found it interesting that even small companies were sending their developers to Visual Studio Live! Even though times are seemingly still tough for many, firms of all sizes are sending developers to learn how to do their jobs better.
More than one attendee said their bosses (actually some of them were bosses) see it as an investment for the future. The initial cost, they believe, will be more than offset by productivity gains and new initiatives or techniques that will directly affect the bottom line.
I worked for a successful media conglomerate during the lean mid-2000s that followed the same philosophy, sending me and other staffers to educational and professional events while most others were cutting back on travel and almost all other expenses. They knew business ran in cycles, and during the next upturn the company would be better positioned for growth and success than competitors chasing the quarterly bottom line. The owner of that company wasn't a multi-billionaire for nothing, I'm guessing.
Calling Them As I See Them, and Looking for Help
Believe, me, I'm aware that the above might be perceived by some as an advertisement for the conference. But I'm an old-school, seasoned, professional journalist who has had ethics and objectivity drilled into me starting with high school journalism classes through a college journalism degree through decades of experience at several organizations. I call them as I see them in both news articles and opinion pieces like this blog post.
So that's what I saw and learned. And based on that, I want to do better in serving our readers. Please share your thoughts on the site's contents -- what you like, what you don't like, what you'd like to see more of. Please comment below or drop me a line.
Posted by David Ramel on 12/22/20170 comments
There's no doubt iOS development is hot right now, with all the iPhone 8/iPhone X hoopla, the new iOS 11 recently shipping with cutting-edge features and so on.
But there's that pesky Mac thing. Apple requires that you have a Mac machine for a full development cycle that includes deploying an app to the App Store.
But there is an awful lot you can do just with Visual Studio on Windows, thanks to a preview tool and a handy cloud service, Matthew Soucoup explained in a presentation at the Visual Studio Live! conference in Orlando, Fla.
Soucoup, senior cloud developer advocate at Microsoft, was on hand to explain how to "Go Mobile with C#, Visual Studio and Xamarin." He demonstrated how Xamarin enables Visual Studio developers to create cross-platform apps for iOS, Android and Windows, while sharing significant amounts of code.
One part of his presentation especially interesting to his developer audience was pairing his Visual Studio project to an iPhone for live debugging. This prompted several audience questions about whether a Mac really was required for iOS development.
The ultimate answer was "Yes" ... eventually. That is, when it comes time for App Store deployment.
"You always will need a Mac," Soucoup told the audience. "Will it get better? I would hope so." He said he hopes the workflow and tools will eventually reach a point where everything can be done on a Windows machine.
 "Xamarin Live Player frees you to do a lot of prototype and rapid iterative development quickly, where you don't have to have your device hooked up and do a full build and deploy process."
"Xamarin Live Player frees you to do a lot of prototype and rapid iterative development quickly, where you don't have to have your device hooked up and do a full build and deploy process."
Matthew Soucoup, senior cloud developer advocate at Microsoft
In the meantime, the audience was pretty impressed with the Xamarin Live Player functionality. Xamarin Live Player -- a new tool in preview status -- is described thusly:
Xamarin Live Player lets you make live edits to your app and have those changes reflected live on your device. Your code runs inside the Xamarin Live Player app – there is no need to set up emulators or to use cables to deploy the code!
Soucoup did just that during his VS Live! presentation, and several audience members had questions about the process.
To use Xamarin Live Player, Soucoup scanned a generated QR code with the Xamarin Live Player app (available in Apple's App Store and the Google Play store) to pair the Visual Studio project with the iPhone via WiFi. He then debugged a simple example app, with code changes showing up almost instantly on the device, "which is actually pretty slick, without having to go to a Mac at all."
He also mentioned another tool that lets developers get beyond the immediate need for a Mac, called MacinCloud. It lets developers manage and access MacinCloud servers from anywhere with Internet access in order to develop apps and perform other tasks that require a Mac.
Soucoup said that when that cloud service first arrived, he thought it would be slow, but subsequently he's heard good things about it.
Getting back to Xamarin Live Player, the Microsoft developer advocated noted that the tool -- as an early-stage preview -- still has some limitations, such as not supporting all NuGet packages and sometimes losing WiFi connectivity, but he expects it to continue to get better.
That's good news to the many developers in the VS Live! audience who questioned him about the tool.
After the presentation, I asked Soucoup if he's noticed more interest in developing iOS apps without a Mac.
"I do get that question a lot, and I think a lot of it is because that they're .NET developers coming here and everybody's used to developing on Visual Studio on Windows," he said. "And going to iOS development with a Mac can seem -- I'm not going to say strange -- but it can seem a little bit out of the ordinary in that usually you can develop anything you want with Visual Studio and all of the sudden Apple does say, 'Hey, you need a Mac to go with this.' So it's just something that seems weird and that people have questions about."
Noting the popularity of the subject in his Xamarin presentations, he said: "I attribute that to, I think, Visual Studio is a great IDE to use, and the fact that Xamarin has given you the remoted iOS simulator on there where you can use a lot of -- like the Surface's touch features, where you can't even do that on a Mac -- has really expanded that. However with that said, Visual Studio on the Mac is coming along very nicely so if you are doing a lot of development on a Mac like I do, I almost live 100 percent in Visual Studio on the Mac, so they're both great experiences to use."
And Xamarin Live Player, no doubt, will continue to generate oohs and aahs from his audiences.
"What the Live Player does for you, is it frees you to do a lot of prototype and rapid iterative development quickly, where you don't have to have your device hooked up and do a full build and deploy process, which if you have a huge app can take several minutes to do," Soucoup said. "And so you can change your UI and see the changes on it within a couple seconds, having it come up. So it's a great tool, it's an exciting tool and I can't wait to see where they're going with it."
The next Visual Studio Live! show will be in Las Vegas March 11-16.
Posted by David Ramel on 11/14/20170 comments
One week from today, a public preview of Microsoft SQL Operations Studio will be available for download. Microsoft provided a "sneak preview" of the tool at the recent PASS Summit for SQL Server developers and DBAs, but details remain scant.
I, for one, wonder how this new offering will fit into the Microsoft data ecosystem, which already has tools like SQL Server Data Tools (SSDT) and SQL Server Management Studio (SSMS) for wrangling the company's flagship RDBMS.
From the information provided so far in a PASS keynote and accompanying blog post, it appears to be a blending of those two tools, with some container and DevOps functionality thrown in along with some Visual Studio Code goodness -- and apparently built on Electron.
In the blog post, Microsoft SQL Operations Studio (MSOS from here on, for brevity) was described as a cross-platform, lightweight tool for modern database development and operations. Along with SQL Server, it will be used to work with other Microsoft data offerings like Azure SQL Database and Azure SQL Data Warehouse.
Like VS Code and other editors, MSOS will provide easy access to code snippets (in the T-SQL language, in this case) and dashboards to monitor performance in the cloud or on the Azure cloud.
 [Click on image for larger view.] Microsoft SQL Operations Studio (source: Microsoft).
[Click on image for larger view.] Microsoft SQL Operations Studio (source: Microsoft).
As for more of that VS Code goodness, Microsoft said "You'll be able to leverage your favorite command line tools like Bash, PowerShell, sqlcmd, bcp and ssh in the Integrated Terminal window. Users can contribute directly to SQL Operations Studio via pull requests from the GitHub repository."
Microsoft exec Rohan Kumar, who opened the PASS Summit with a keynote address, provided more details about MSOS.
"We believe this is the way of the future," Kumar said. "It's in its infancy. We see a lot of devops experiences, [where] development and testing is being used right on containers, but this is only going to get better and SQL is already prepared for it."
The SQL Server Data Tools team provided more info in its Twitter feed, which makes for a handy, ad-hoc Q&A:
- Q: Come in black?
A: Of course, many colors.
- Q: Will this tool replace SSMS?
A: It is not in our roadmap.
- Q: Is it mostly like a cross platform SSMS?
A: It targets both devs and ops in multi-os.
- Q: Is this a @code plugin or fork?
A: It is based on MSSQL extension on VS code, VS code and many more.
- Q: Will it be backward compatible...?
A: Yes all SQL tools are backward compatible. :)
- Q: As far as I understand, it's more on the "operations" side (read: SSMS light & cross-platform) as opposed to the dev side.
A: SQL Operations Studio is for Database developers and ops. Equally important to us.
- Q: Congrats! Electron?
A: Yup.
Many SQL Server devs and DBAs seemed to be pretty excited about the new tool according to other tweets. Some of the apparently attended the PASS session that introduced the tool (I couldn't find any recordings or downloads for the presentation or attended an on-site demo. Here are a few:
- I am going to try my best to use this as my primary IDE. So excited! Thanks again @sqltoolsguy and team!
- This was AMAZING! Finally, some cool tools for us backend devs.
- Pretty excited about this and an important step towards getting some of the web dev world over to a full featured/intelligent database layer.
Jeffrey Schwartz attended the PASS Summit and provides more information in a post on our sister site, RedmondMag.com. It's a good read, and here's a tease:
Joseph D 'Antonio, a principal consultant with Denny Cherry and Associates and a SQL Server MVP, has been testing SQL Operations Studio for more than six months. "It's missing some functionality but it's a very solid tool," said D 'Antonio, who also is a Redmond contributor. "For the most part, this is VS code, with a nice database layer."
Anybody out there have more details on MSOS? Please comment here or drop me a line.
Posted by David Ramel on 11/08/20170 comments
So much for the "new" Microsoft.
I thought Microsoft had transformed from a hated, closed-off corporate predator into an openness champion, embracing other technologies and pleasing developers by seeking their feedback and enhancing its tooling accordingly.
I was wrong.
Microsoft programming languages, products -- and even the company itself -- graded poorly in a Stack Overflow data scientist's investigation into the most "disliked" tech offerings on the popular coding Q&A site.
SO's David Robinson used his data science skills to investigate the site's Developer Story feature (kind of an online technical resume) that lets programmers indicate with topic tags what languages, technologies and so on they'd like to work with and which ones they'd rather not work with.
To determine how "polarizing" each topic tag is, Robinson computed how often a tag it appears in someone's "disliked" tags compared to how often it appears in someone else's disliked or "liked" tags.
The study examined programming langages and other tech offerings in general, such as OSes, platforms and libraries. In that generalized category, Internet Explorer was the most disliked tag, heading up several more Microsoft offerings.
Speaking of those dislike tags, Robinson said, "Several are Microsoft technologies, particularly Internet Explorer and Visual Basic, as well as the 'Microsoft' tag ('Apple' also makes the list, though it's not as dramatically disliked)."
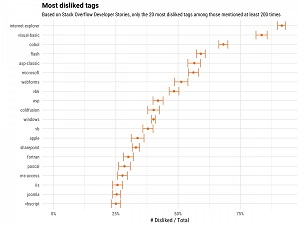 [Click on image for larger view.] Most Disliked Tags (source: Stack Overflow).
[Click on image for larger view.] Most Disliked Tags (source: Stack Overflow).
But also making the list were ASP-Classic, VB6, ASP, Windows, VB, WebForms, SharePoint, Microsoft Access, IIS, VBScript and even Microsoft, clocking in at No. 6. That makes for 13 Microsoft-related offerings dominating the top 20 list.
Another anslysis invovled organizing the dislike tags into networks to represent an overall software ecosystem, quickly scannable with the help of connected, colored nodes to indicate the grouping of disliked tags. It shows a big cluster of Microsoft offerings.
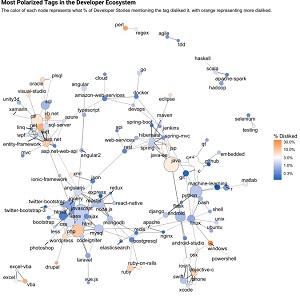 [Click on image for larger view.] Most Disliked Tags, Networked (source: Stack Overflow).
[Click on image for larger view.] Most Disliked Tags, Networked (source: Stack Overflow).
"By laying out Developer Story tags into sub-ecosystems, this network tells a story about what types of tags tend to be polarizing," Robinson said. "There are clusters of polarizing tags within the sub-ecosystems for Microsoft (centered around C# and .NET), PHP (along with WordPress and Drupal), and mobile development (particularly Objective-C). Within the cluster of operating systems (lower right), we can see that systems such as OSX and especially Windows have their detractors, but tags like Linux, Ubuntu and Unix don't."
Yet another investigation attempted to glean insights about "rivalries," measuring how often a person who likes a certain tag will dislike others. Here, "Windows" topped the chart as being most often disliked by people who said they like Linux.
There was also a little Microsoft-bashing on the Reddit social site for coders, where a link to the study was posted. One reader said, "I like C# as a language, but the whole rest of the Microsoft infrastructure and tooling puts me off." In reply, another said, "Oh god, the ecosystem sucks. But to be fair it really only sucks compared to Java. If you can get over the Microsoft lock-in (I haven't, but I can see through it now), it's not much worse than other languages."
On Hacker News, though, none of the comments mentioned Microsoft at all. I would have expected plenty of Microsoft rips on these sites, as their readers aren't known for holding back their feelings, especially of the negative variety (see here).
This makes me think the SO study might be overstating things when it comes to Microsoft ire. After all, I'm continually writing articles that indicate Microsoft has implemented some new feature or fix in response to developer feedback. I mean, again and again -- it has become a common theme. And the company seems to go out of its way to solicit feature requests, bug reports and other feedback and then act on it. Maybe "act" in another context is the operative word here, but the company's feedback-gathering efforts on the UserVoice site for Visual Studio, GitHub issues, forums and elsewhere seem genuine to me (and not because the company is infused with altruism, but rather because it just makes good business sense).
Robinson emphasized that his study wasn't intended to indict any technologies as to their quality or popularity, but rather was just measuring which ones are viewed negatively by those SO-affiliated developers who cared to share this information publicly.
He also added a personal note sharing his own thoughts, where the "polarzing" Microsoft again figures prominently.
"I don't have any interest in 'language wars,' and I don't have any judgment of users who share technologies they'd rather not work with," Robinson said. "Thinking about how polarizing Microsoft technologies often are does encourage me to share my personal experience. I've been a lifelong Mac and UNIX user, and nearly all of my programming in college and graduate school was centered around Python and R. Despite that, I was happy to join a company with a .NET stack, and I'm glad I did -- because I loved the team, the product, and the data. I can't speak for anyone else, but I'm glad I defined myself in terms of what work I wanted to do, and not something I wanted to avoid."
There's plenty more information of all types, sizes and slices in the study, which you can read more about in this article.
Posted by David Ramel on 10/31/20170 comments
Citing "passionate feedback" from developers (some called it "backlash") that was "very helpful, painful, and entertaining all at the same time," Microsoft reversed its decision to change the color of its icons for the Visual Studio Code editor.
Sans the color reversal, however, the new design remains in place. Stay tuned for the coming "feedback" on that.
To sum up this situation:
- Microsoft in August floated some new designs for the VS Code icons in the midst of a broader developer tools initiative at the company.
- The negative feedback started immediately, proving once again how finicky developers can be about the UI of their favorite tools.
- On GitHub issues, coding forums, article comments, blog posts, Twitter feeds and more, coders aired their feelings on the new design, with a negative-vs.-positive ratio that I would guess to be around 95:5.
- Yesterday, while apologizing for the delay in response, Chris Dias, a Microsoft group program manager, related "The Icon Journey" and announced this TL;DR:
Thanks for all the passionate feedback. It has been very helpful, painful, and entertaining all at the same time. We're changing the orange icon to blue for Stable and keeping green for Insiders.
If nothing else, this whole icon-change saga provides interesting insights into the decision-making processes at large companies, even over something as seemingly insignificant as the appearance of a tiny icon that might measure just 32x32 pixels or even 16x16.
 The Previous VS Code Icon (source: Microsoft).
The Previous VS Code Icon (source: Microsoft).
The broader developer tool initiative for new branding icons began back in March, Dias said, noting that "we had to work within a set of 'challenging' corporate branding guidelines."
Who hasn't been there? Hearing from the bosses, "OK, you've got to do this, but meanwhile, you have to follow this, allow for that, can't do this other thing, and absolutely must comply with these. Go get 'em!"
Not that Dias was making excuses. "It is easy to blame the guidelines, but at the same time, having a set of products that are easily and broadly recognizable is a valuable asset," he said. "Instead, we took on the challenge of working within the constraints while also working across the company to evolve the guidelines and address the problems we faced."
The team sweated over the tiniest details, working up and discarding idea after idea, iteration after iteration, color after color, option after option.
Finally, Dias seemed to indicate the team got so tired of the whole thing they just went with what was available.
"By mid-summer, icon fatigue rolled in. We had made so many iterations, we finally said let's go with the current shape, and we checked in the 'pre-release' design for Insiders."
Who hasn't been there? You work on something so much for so long you just get worn out and say: "Forget it, let's ship." (Actually, stronger language than "forget" would probably be used.)
 [Click on image for larger view.] Some Early Considerations (source: Microsoft).
[Click on image for larger view.] Some Early Considerations (source: Microsoft).
But more work remained to be done, primarily concerning colors. It was fascinating to see that Dias admitted one of the principal complaints about the new icon scheme -- its similarity to the Sublime Text editor, which many developers have installed along with VS Code -- was actually considered by the team but discounted as a significant factor.
 The New Sublime Text Logo, Which Took Microsoft by Surprise (source: Sublime Text).
The New Sublime Text Logo, Which Took Microsoft by Surprise (source: Sublime Text).
"At this point, we pretty much ran out of colors in the family palette, except for the now infamous orange. There was some concern about the similarity to Sublime Text color palette, but no one had issues when we tested it. And quite honestly, we were more surprised by the latest Sublime's use of a folded ribbon."
Of course, many developers complained the similarity caused them to open up the wrong program by mistake.
 [Click on image for larger view.] New Logos Introduced with VS Code v1.17 (source: Microsoft).
[Click on image for larger view.] New Logos Introduced with VS Code v1.17 (source: Microsoft).
The new orange color introduced for the Insiders build (an early preview program) didn't generate much feedback for a couple months, Dias said.
"Maybe our fears were unfounded. Maybe users would really like the new icons and all the angst on a handful of problems were not worth losing sleep over. We decided not to shine a light on something that might not be a problem. We pushed the changes and made a small reference to the new icons in the release notes."
Developers noticed that small reference and began to complain. We reported on the issue and noted that Microsoft was "risking the wrath of recalcitrant developers." Oh boy, were they.
 The Latest: Back to Blue (source: Microsoft).
The Latest: Back to Blue (source: Microsoft).
"Each day there were additional comments, each expressing a dislike of the new icon in new and interesting ways," Dias said. "After the first couple of days, we thought the feedback would slow and we would be able to address the individual issues. Turns out, we were wrong. The feedback just kept coming in. New issues were opened, comments came in faster than we could respond. Hacker News, Visual Studio Magazine. High School friends posted comments on FaceBook. Awesome."
Paraphrasing a capsule summation of the top issues, Dias listed:
- The color change was far too drastic, orange is the opposite color of blue, making that which looked good before, look horrible now.
- A flat single color icon that relies entirely on transparency to create negative space makes it less distinct and aggravates the distinguishability problems.
- The new border is so large and bold that it's more distinct to the eye than the infinity symbol is.
"All of this feedback urged us go back and see if we could do a better job while still creating a family of products," Dias said. "As a result, we are going change the Stable icon to the much-loved blue."
 Insiders (Green) and Stable (Blue) (source: Microsoft).
Insiders (Green) and Stable (Blue) (source: Microsoft).
Dias noted that simple color change doesn't address all the issues raised, and more changes are likely in store, with the team being open to new ideas.
Will developers accept the color change as a welcome response to their concerns -- yet another manifestation of the new Microsoft that really values "Developers! Developers! Developers!" Or will they complain it isn't enough and demand a total retrenchment?
Well, what do you think?
Posted by David Ramel on 10/25/20170 comments
I knew this was going to happen.
Developers are revolting against the new icons introduced by Microsoft for Visual Studio Code, the open source, cross-platform little cousin to the Visual Studio IDE.
Besides venting their frustration on forums and GitHub issues, the coding community has launched petitions to revert back to the original scheme, and developers have figured out on their own how to do a manual replacement.
I just knew this was going to happen.
When announcing the news in August, I started out saying Microsoft was "risking the wrath of recalcitrant developers." You just don't mess with the UI of an editor/IDE when it comes to typography, colors or other subjective aspects of design without annoying some segment of finicky coders.
Microsoft's effort to redesign several dev tooling icons came to light in a GitHub issue filed to request a new VS Code icon for Mac OS X in May 2016. Out of that discussion, new VS Code icons were revealed to be in the works, with some prototypes shown, and all angst broke loose. The issue now has 111 comments, still coming in this morning. Few of them are positive.
So, of course, another issue sprang up earlier this month, this one titled "New VS Code icon is ugly!" It says: "Can we return previous app icon or draw a new one? It really looks bad." Nine days old, the issue has garnered 153 comments.
Soon following that, developer Alex Kras last week posted a tutorial on "Restoring Original Visual Studio Code Icon on MacOS," inspired by one of the replacement icons offered up by GitHub commentators.
Here's a visual history of the issue starting out with the original icon:
The Previous VS Code Icon (source: Microsoft).
Then, during a lengthy development process, these icons were proffered in an August post by Microsoft, with different variations for stable and Windows Insider releases on different platforms:

[Click on image for larger view.] The New VS Code Icons as Originally Presented in a GitHub Issue (source: Microsoft).
At the time, a Microsoft's Chris Dias pointed to a blog post titled "Iterations on infinity" blog post that he said does a good job explaining how the company decided upon the latest Visual Studio family of icons.
"For VS Code specifically, we took our time to iterate on a number of 'editor' related symbols before pivoting to a subset of the infinity symbol," he said. "We feel that the icon denotes 'openness'. It conveys that VS Code is (in a good way) a subset of our big brother, the Visual Studio IDE. And, if you look hard enough, you'll find a small tribute to a great mind."
And finally, this is what Microsoft introduced with VS Code 1.17:
[Click on image for larger view.] New Logos Introduced with v1.17 (source: Microsoft).
Note that if you want to do a manual revert, the post by Kras provides instructions for doing so only on Mac OS. It simply involves downloading the original .icns files and copying over the new ones and forcing a refresh.
And similar workarounds -- which some developers said are easy to do -- will probably soon be available for Windows implementations, if they haven't already been published.
Because developers will never, ever, agree on design.
Where Dias saw "openness," another developer commenting on his post saw "too much going on."
Where Microsoft says the icon offers a new interpretation of the infinity sign, showing oppenness (with the open end), another developer asks why it was turned into a fish.
Where Microsoft's design exec John Lea says "I'm quite proud of what our designers have accomplished," a Hacker News reader thought the new icon "makes you think for a sec if the app is corrupted or something."
On Reddit, a reader said UX folks seem prone to being "artsy-fartsy, twaddlepated dweebledorfs."
Other readers of Dias's post weighed in with comments such as:
- "Why orange? Why not blue as same? I think blue is look better than orange."
- "The old green Icon was much more minimalistic, is there somewhere I can get it to swap it out manually? This new one doesn't stand out and just blends in with the rest making it harder to see."
- "It's also really difficult to tell the two icons apart at small sizes, especially on MacOS. I like the concept, and I think the two icons look fantastic, but I don't think they are an improvement."
Comments on our August article included:
- "I don't like this new icon at all .. look stupid and not nice colors .. why mimic sublime text icon actually .. I want the blue icon back"
- "We feel that the icon denotes incompetence from Microsoft, taking 4 months to design an icon that is simple, ugly and with only one color that any children could realize in less than an hour."
- "OMG I hate this icon. Everything was so clean before. I had VS Code, Express and Studio all lined up in pretty order. Messing up my feng shui man!"
- "lol I am happy that the old icon was changed. Because I often accidentally opened Microsoft Outlook instead of Visual Code. Now this no longer will be the case."
Besides the commentary, other GitHub users have filed issues saying "VS Code icon is too transparent" and "new VS Code icon doesn't look right in Windows Open dialog" and "New icon too similar to sublime."
BTW, that last comment was duplicated by a Visual Studio Magazine reader ("Now I open Sublime Text 3 every time I want to open VS Code") in the commentary on our August article. That article, as I write this, is the most popular one on the site, surpassing recent top-notch, hands-on tutorials from subject-area experts on topics such as writing precompiled Azure Functions, building DOM additions with Angular and TypeScript, neural network L2 regularization using Python and so on.
Which, of course, is why I'm writing this.
Because my feelings are more aligned with the top comment on Hacker News, which says, in part: "Really? It's an icon. An icon! And we are spending time deliberating on this? Stop being petty and worry about things that actually matter."
So tell me why it matters. Because it obviously does. How does the color/shape of a tiny icon affect your performance when using VS Code? Comment here or drop me a line.
Posted by David Ramel on 10/16/20170 comments